Integrating Fine-Grained Audio-Visual Evidence for Robust Multimodal Emotion Reasoning
作者: Zhixian Zhao, Wenjie Tian, Xiaohai Tian, Jun Zhang, Lei Xie
分类: cs.MM, cs.CL, cs.CV
发布日期: 2026-01-26
🔗 代码/项目: GITHUB
💡 一句话要点
提出SABER-LLM框架,通过细粒度音视频证据融合提升多模态情感推理的鲁棒性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态情感分析 情感推理 大型语言模型 视听融合 细粒度感知 鲁棒性 数据集构建
📋 核心要点
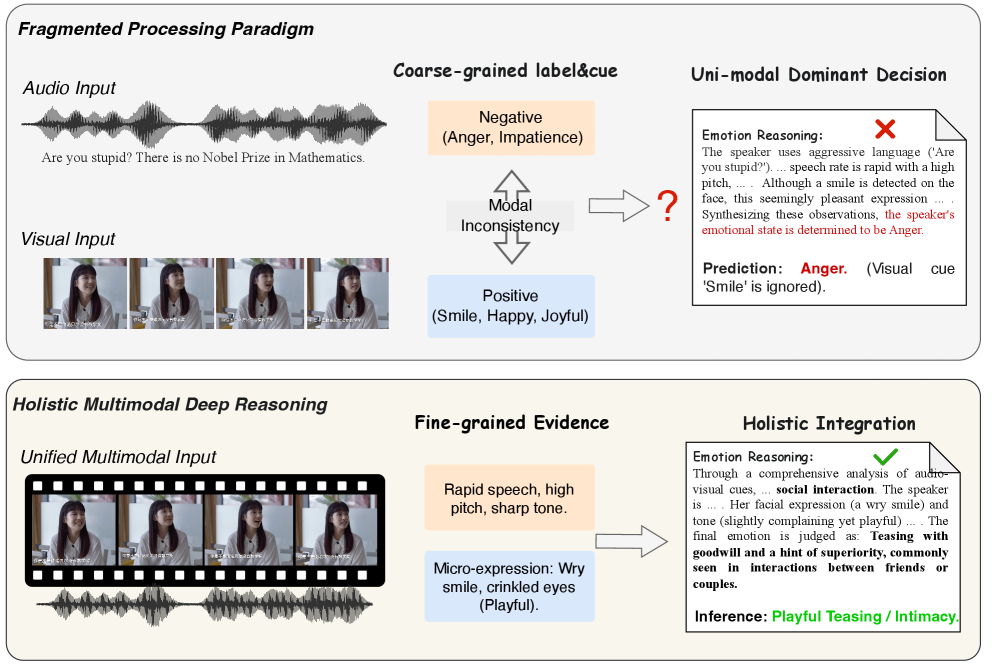
- 现有MLLM在细粒度情感感知上存在不足,易受单模态主导影响,导致复杂场景下推理错误。
- 提出SABER-LLM框架,通过结构化证据分解和一致性感知优化,提升模型对细粒度音视频信息的利用。
- 在多个情感分析数据集上,SABER-LLM显著优于开源模型,并在鲁棒性上与闭源模型竞争。
📝 摘要(中文)
多模态情感分析正从静态分类转向生成式推理。为了实现鲁棒的情感推理,需要综合面部微表情和韵律等细粒度信号,从而解码复杂社会背景下的潜在因果关系。然而,当前的多模态大型语言模型(MLLM)在细粒度感知方面面临显著限制,主要原因是数据稀缺和跨模态融合不足。这导致模型经常表现出单模态主导,从而在复杂的多模态交互中产生幻觉,尤其是在视觉和听觉线索微妙、模糊甚至矛盾的情况下(例如,在讽刺场景中)。为了解决这个问题,我们引入了SABER-LLM,一个为鲁棒多模态推理设计的框架。首先,我们构建了SABER,一个包含60万个视频片段的大规模情感推理数据集,并使用一种新的六维模式进行标注,该模式共同捕获视听线索和因果逻辑。其次,我们提出了结构化证据分解范式,该范式强制在证据提取和推理之间进行“感知-然后-推理”的分离,以减轻单模态主导。通过一致性感知直接偏好优化进一步增强了感知复杂场景的能力,该优化显式地鼓励模态之间在模糊或冲突的感知条件下保持一致性。在EMER、EmoBench-M和SABER-Test上的实验表明,SABER-LLM显著优于开源基线,并在解码复杂情感动态方面实现了与闭源模型竞争的鲁棒性。数据集和模型可在https://github.com/zxzhao0/SABER-LLM获得。
🔬 方法详解
问题定义:当前多模态情感分析模型在处理复杂场景时,由于数据稀缺和跨模态融合不足,难以有效利用细粒度的视听信息(如微表情、语调),导致模型容易受到单模态信息主导,产生幻觉,尤其是在模态信息冲突或模糊时,影响情感推理的准确性和鲁棒性。
核心思路:SABER-LLM的核心思路是通过构建大规模细粒度情感推理数据集SABER,并结合结构化证据分解范式和一致性感知直接偏好优化,来提升模型对细粒度视听信息的感知和利用能力,从而减轻单模态主导,增强多模态情感推理的鲁棒性。
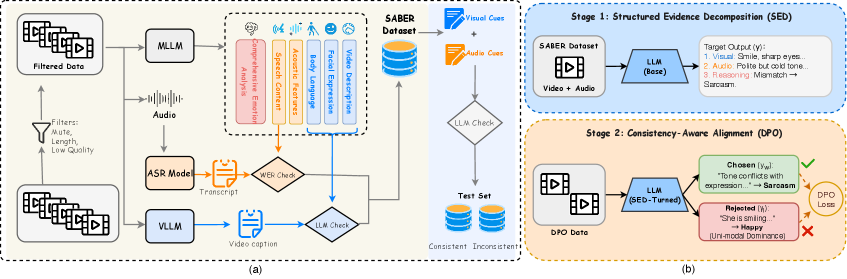
技术框架:SABER-LLM框架主要包含以下几个部分:1) 大规模情感推理数据集SABER的构建,包含60万视频片段,并使用六维模式标注视听线索和因果逻辑;2) 结构化证据分解范式,将情感推理过程分解为“感知-然后-推理”两个阶段,首先提取细粒度的视听证据,然后进行情感推理;3) 一致性感知直接偏好优化,通过显式地鼓励模态之间在模糊或冲突的感知条件下保持一致性,来增强模型对复杂场景的理解。
关键创新:该论文的关键创新点在于:1) 构建了大规模细粒度情感推理数据集SABER,为模型训练提供了丰富的数据支持;2) 提出了结构化证据分解范式,有效分离了证据提取和推理过程,减轻了单模态主导;3) 引入了一致性感知直接偏好优化,增强了模型在模态信息冲突或模糊情况下的鲁棒性。与现有方法相比,SABER-LLM更加注重细粒度信息的利用和跨模态一致性,从而提升了情感推理的准确性和鲁棒性。
关键设计:SABER数据集使用六维模式标注,具体维度未知(论文未详细描述)。结构化证据分解范式的具体实现方式未知(论文未详细描述)。一致性感知直接偏好优化的具体损失函数和优化策略未知(论文未详细描述)。
🖼️ 关键图片

📊 实验亮点
SABER-LLM在EMER、EmoBench-M和SABER-Test数据集上进行了评估,实验结果表明,SABER-LLM显著优于开源基线模型,并在解码复杂情感动态方面实现了与闭源模型竞争的鲁棒性。具体的性能提升数据未知(论文未提供具体数值)。
🎯 应用场景
该研究成果可应用于智能客服、心理咨询、人机交互等领域。通过更准确地理解用户的情感状态,可以提供更个性化、更贴心的服务。未来,该技术有望应用于社交媒体情感分析、舆情监控、智能驾驶等领域,具有广阔的应用前景。
📄 摘要(原文)
Multimodal emotion analysis is shifting from static classification to generative reasoning. Beyond simple label prediction, robust affective reasoning must synthesize fine-grained signals such as facial micro-expressions and prosodic which shifts to decode the latent causality within complex social contexts. However, current Multimodal Large Language Models (MLLMs) face significant limitations in fine-grained perception, primarily due to data scarcity and insufficient cross-modal fusion. As a result, these models often exhibit unimodal dominance which leads to hallucinations in complex multimodal interactions, particularly when visual and acoustic cues are subtle, ambiguous, or even contradictory (e.g., in sarcastic scenery). To address this, we introduce SABER-LLM, a framework designed for robust multimodal reasoning. First, we construct SABER, a large-scale emotion reasoning dataset comprising 600K video clips, annotated with a novel six-dimensional schema that jointly captures audiovisual cues and causal logic. Second, we propose the structured evidence decomposition paradigm, which enforces a "perceive-then-reason" separation between evidence extraction and reasoning to alleviate unimodal dominance. The ability to perceive complex scenes is further reinforced by consistency-aware direct preference optimization, which explicitly encourages alignment among modalities under ambiguous or conflicting perceptual conditions. Experiments on EMER, EmoBench-M, and SABER-Test demonstrate that SABER-LLM significantly outperforms open-source baselines and achieves robustness competitive with closed-source models in decoding complex emotional dynamics. The dataset and model are available at https://github.com/zxzhao0/SABER-LLM.