Calibrating Beyond English: Language Diversity for Better Quantized Multilingual LLM
作者: Everlyn Asiko Chimoto, Mostafa Elhoushi, Bruce A. Bassett
分类: cs.CL, cs.AI
发布日期: 2026-01-26
备注: Accepted to EACL 2026 Main Conference
💡 一句话要点
提出多语言校准方法,提升量化多语言大语言模型在多种语言上的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言大语言模型 模型量化 后训练量化 校准数据集 困惑度 语言对齐 GPTQ AWQ
📋 核心要点
- 现有量化方法主要依赖英语校准集,忽略了多语言大模型在非英语语种上的性能退化问题。
- 该论文提出使用非英语和多语言混合校准集,以提升量化模型在多种语言上的困惑度表现。
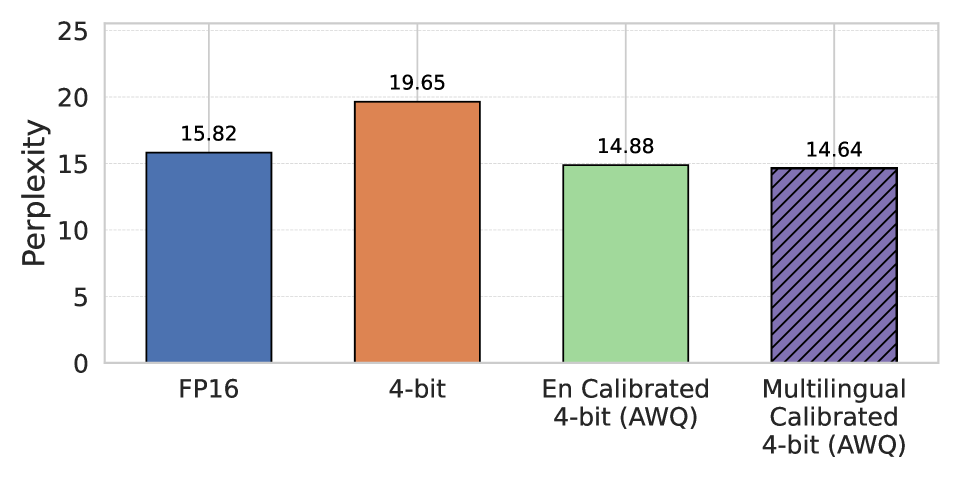
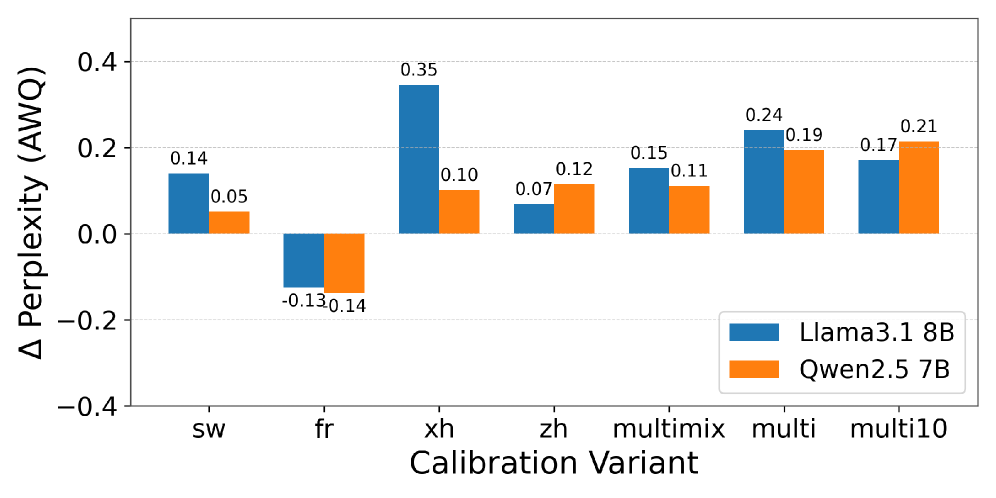
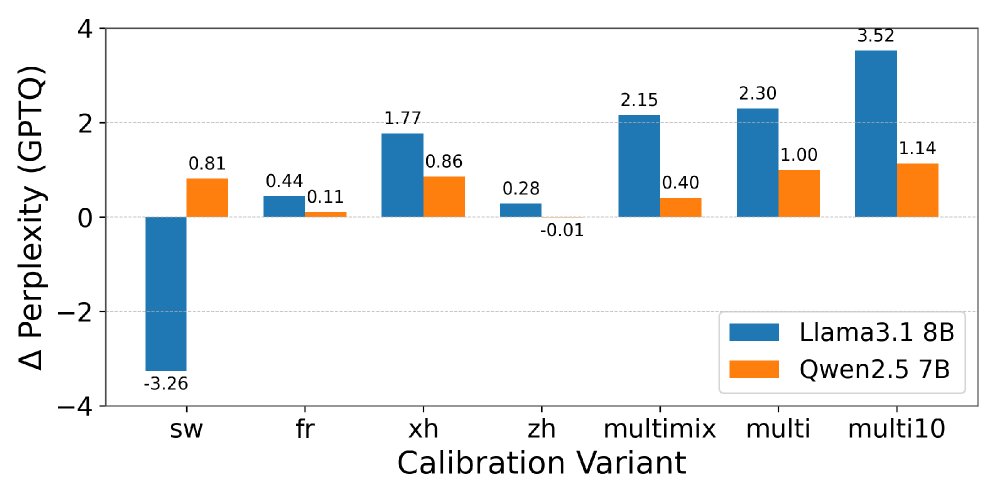
- 实验表明,多语言校准集能显著降低Llama3.1 8B和Qwen2.5 7B的困惑度,最高降低3.52点。
📝 摘要(中文)
量化是一种降低大语言模型(LLM)存储空间和计算成本的有效技术,但通常会导致性能下降。现有的后训练量化方法通常使用小型、仅限英语的校准集;然而,它们对多语言模型的影响仍未得到充分探索。我们系统地评估了八种校准设置(五种单语和三种多语混合)在来自10种语言的数据上,使用两种量化器(GPTQ、AWQ)。我们的发现揭示了一个一致的趋势:与仅英语的基线相比,非英语和多语言校准集显著提高了困惑度。具体来说,我们观察到Llama3.1 8B和Qwen2.5 7B在两种量化器上的平均困惑度都有显著提高,其中多语言混合实现了最大的整体降低,高达3.52点困惑度。此外,我们的分析表明,为评估语言定制校准集可以为单个语言带来最大的改进,突出了语言对齐的重要性。我们还发现了一些特定的失败案例,其中某些语言-量化器组合会降低性能,我们将其归因于不同语言之间激活范围分布的差异。这些结果表明,静态的“一刀切”校准是次优的,并且在语言和多样性方面定制校准数据在稳健地量化多语言LLM中起着至关重要的作用。
🔬 方法详解
问题定义:论文旨在解决多语言大语言模型量化后在非英语语种上性能下降的问题。现有方法主要采用英语校准集,无法充分捕捉不同语言的特性,导致量化后的模型在非英语语种上表现不佳。
核心思路:论文的核心思路是利用非英语和多语言混合的校准数据集,对量化过程进行优化,从而提升模型在多种语言上的性能。通过引入更多语言信息,使量化过程更好地适应不同语言的激活分布,减少量化误差。
技术框架:该研究主要包括以下几个步骤:1) 选择多语言大语言模型(如Llama3.1 8B和Qwen2.5 7B);2) 构建包含多种语言的校准数据集;3) 使用不同的量化器(GPTQ、AWQ)对模型进行量化;4) 在多种语言上评估量化模型的困惑度;5) 分析不同校准设置对模型性能的影响。
关键创新:该论文的关键创新在于提出了多语言校准的概念,并系统地评估了不同语言组合的校准集对量化模型性能的影响。研究表明,针对特定评估语言定制校准集可以获得最佳性能,这突出了语言对齐的重要性。
关键设计:论文实验中使用了五种单语校准集(包括英语)和三种多语言混合校准集。评估了两种量化器(GPTQ和AWQ)在10种语言上的性能。通过困惑度指标来衡量量化模型的性能,并分析了不同语言的激活范围分布,以解释某些语言-量化器组合导致性能下降的原因。
🖼️ 关键图片
📊 实验亮点
实验结果表明,与仅使用英语校准集相比,使用非英语和多语言混合校准集可以显著降低量化模型的困惑度。在Llama3.1 8B和Qwen2.5 7B模型上,多语言混合校准集实现了高达3.52点的困惑度降低。此外,针对特定评估语言定制校准集可以获得最佳性能,突出了语言对齐的重要性。
🎯 应用场景
该研究成果可应用于各种需要部署多语言大语言模型的场景,例如多语言聊天机器人、跨语言信息检索、机器翻译等。通过使用多语言校准方法,可以显著提升量化模型的性能,降低部署成本,并提高用户体验。未来,该方法可以进一步推广到更多语言和模型,实现更高效、更准确的多语言大语言模型部署。
📄 摘要(原文)
Quantization is an effective technique for reducing the storage footprint and computational costs of Large Language Models (LLMs), but it often results in performance degradation. Existing post-training quantization methods typically use small, English-only calibration sets; however, their impact on multilingual models remains underexplored. We systematically evaluate eight calibration settings (five single-language and three multilingual mixes) on two quantizers (GPTQ, AWQ) on data from 10 languages. Our findings reveal a consistent trend: non-English and multilingual calibration sets significantly improve perplexity compared to English-only baselines. Specifically, we observe notable average perplexity gains across both quantizers on Llama3.1 8B and Qwen2.5 7B, with multilingual mixes achieving the largest overall reductions of up to 3.52 points in perplexity. Furthermore, our analysis indicates that tailoring calibration sets to the evaluation language yields the largest improvements for individual languages, underscoring the importance of linguistic alignment. We also identify specific failure cases where certain language-quantizer combinations degrade performance, which we trace to differences in activation range distributions across languages. These results highlight that static one-size-fits-all calibration is suboptimal and that tailoring calibration data, both in language and diversity, plays a crucial role in robustly quantizing multilingual LLMs.