Temp-R1: A Unified Autonomous Agent for Complex Temporal KGQA via Reverse Curriculum Reinforcement Learning
作者: Zhaoyan Gong, Zhiqiang Liu, Songze Li, Xiaoke Guo, Yuanxiang Liu, Xinle Deng, Zhizhen Liu, Lei Liang, Huajun Chen, Wen Zhang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-01-26
备注: Work in progress
🔗 代码/项目: GITHUB
💡 一句话要点
提出Temp-R1以解决复杂时间知识图谱问答问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 时间知识图谱 问答系统 强化学习 反向课程学习 复杂推理 自主代理 动态事实
📋 核心要点
- 核心问题:现有TKGQA方法依赖固定流程和闭源API,限制了灵活性和可扩展性。
- 方法要点:提出Temp-R1,通过强化学习训练的自主代理,扩展动作空间并引入反向课程学习。
- 实验或效果:Temp-R1在MultiTQ和TimelineKGQA上表现优异,复杂问题性能提升19.8%。
📝 摘要(中文)
时间知识图谱问答(TKGQA)具有挑战性,因为它需要对动态事实进行复杂推理,涉及多跳依赖和复杂的时间约束。现有方法依赖固定工作流程和昂贵的闭源API,限制了灵活性和可扩展性。我们提出了Temp-R1,这是第一个通过强化学习训练的自主端到端代理,用于TKGQA。为了解决单步推理中的认知负担,我们扩展了动作空间,增加了专门的内部动作。为了防止在简单问题上的捷径学习,我们引入了反向课程学习,先在困难问题上训练,迫使模型发展复杂推理能力,然后再转向简单问题。我们的8B参数Temp-R1在MultiTQ和TimelineKGQA上实现了最先进的性能,在复杂问题上比强基线提高了19.8%。
🔬 方法详解
问题定义:本论文旨在解决时间知识图谱问答(TKGQA)中的复杂推理问题。现有方法通常依赖于固定的工作流程和昂贵的闭源API,导致灵活性不足和可扩展性差。
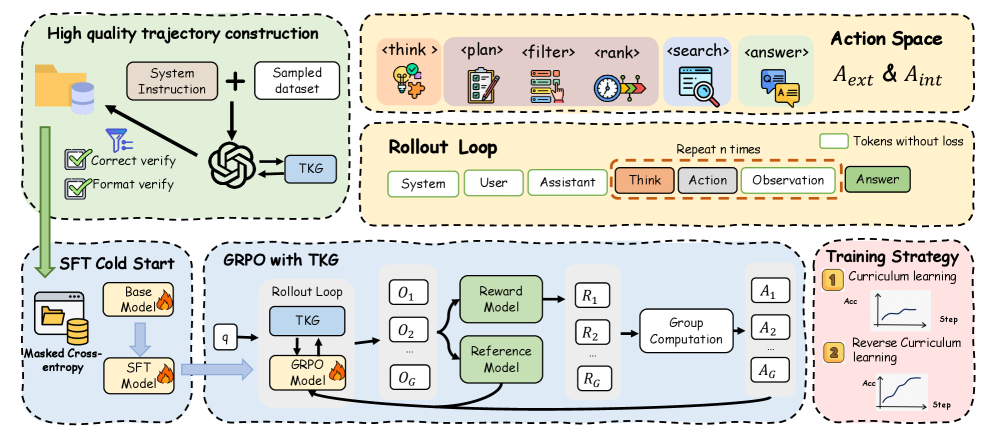
核心思路:我们提出Temp-R1,这是第一个通过强化学习训练的自主端到端代理。为了解决单步推理中的认知负担,我们扩展了动作空间,增加了内部动作,并引入反向课程学习,从困难问题开始训练,以促进复杂推理能力的发展。
技术框架:Temp-R1的整体架构包括多个模块,首先是问题解析模块,然后是推理模块,最后是答案生成模块。每个模块都经过精心设计,以支持复杂的时间推理任务。
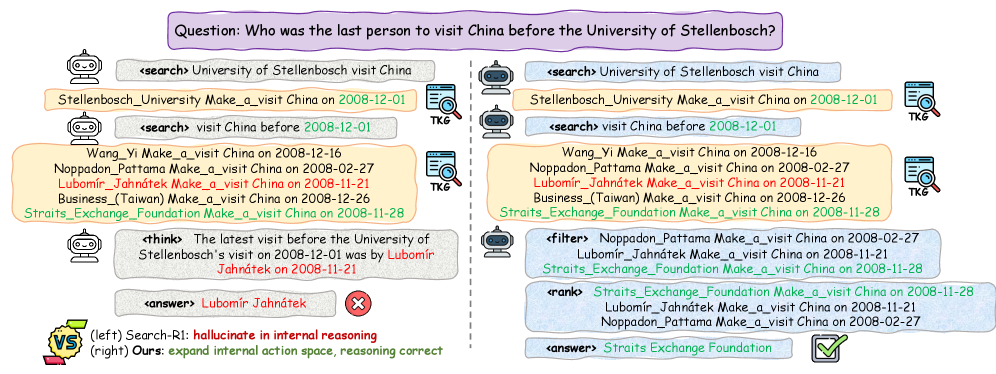
关键创新:最重要的创新点在于引入反向课程学习策略,先训练困难问题,避免模型在简单问题上形成捷径学习的倾向。这一设计与现有方法的本质区别在于其训练策略的灵活性和有效性。
关键设计:在模型设计中,我们使用了8B参数的网络结构,采用了特定的损失函数来优化推理过程,并通过扩展的动作空间来增强模型的推理能力。
🖼️ 关键图片

📊 实验亮点
Temp-R1在MultiTQ和TimelineKGQA数据集上实现了最先进的性能,尤其在复杂问题上比强基线提高了19.8%。这一显著提升证明了反向课程学习和扩展动作空间的有效性,为未来的研究提供了新的方向。
🎯 应用场景
该研究的潜在应用领域包括智能问答系统、信息检索和知识管理等。通过提升时间知识图谱问答的能力,Temp-R1能够为用户提供更准确和及时的信息,具有重要的实际价值和未来影响。
📄 摘要(原文)
Temporal Knowledge Graph Question Answering (TKGQA) is inherently challenging, as it requires sophisticated reasoning over dynamic facts with multi-hop dependencies and complex temporal constraints. Existing methods rely on fixed workflows and expensive closed-source APIs, limiting flexibility and scalability. We propose Temp-R1, the first autonomous end-to-end agent for TKGQA trained through reinforcement learning. To address cognitive overload in single-action reasoning, we expand the action space with specialized internal actions alongside external action. To prevent shortcut learning on simple questions, we introduce reverse curriculum learning that trains on difficult questions first, forcing the development of sophisticated reasoning before transferring to easier cases. Our 8B-parameter Temp-R1 achieves state-of-the-art performance on MultiTQ and TimelineKGQA, improving 19.8% over strong baselines on complex questions. Our work establishes a new paradigm for autonomous temporal reasoning agents. Our code will be publicly available soon at https://github.com/zjukg/Temp-R1.