Typhoon-S: Minimal Open Post-Training for Sovereign Large Language Models
作者: Kunat Pipatanakul, Pittawat Taveekitworachai
分类: cs.CL, cs.AI
发布日期: 2026-01-26
备注: 19 pages. Code is publicly available at https://github.com/scb-10x/typhoon-s . Datasets and model weights are available at https://huggingface.co/collections/typhoon-ai/typhoon-s
💡 一句话要点
Typhoon-S:面向主权大语言模型的极简开放式后训练方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 后训练 监督微调 强化学习 在线蒸馏 主权AI 低资源语言 法律推理
📋 核心要点
- 现有LLM训练和评估主要集中在高资源语言,且依赖大规模计算资源,限制了主权机构对模型的可控性和透明度。
- Typhoon-S提出一种极简开放的后训练方法,结合监督微调、在线蒸馏和小规模强化微调,旨在降低训练成本。
- 实验表明,该方法在泰语法律推理和特定知识方面表现出色,同时保持了通用能力,为资源受限场景提供了可行方案。
📝 摘要(中文)
大型语言模型(LLMs)发展迅速,但大多数最先进的模型主要在高资源语言(如英语和中文)中进行训练和评估,并且通常由少数能够访问大规模计算和数据的组织开发。这种限制为主权环境带来了实际障碍,在这些环境中,区域或国家级机构或领域所有者必须在有限的资源和严格的透明度约束下,保持对模型权重、训练数据和部署的控制和理解。为此,我们确定了两个核心要求:(1)适应性,即将基础模型转化为通用助手的能力;(2)主权能力,即执行高风险、特定区域任务的能力(例如,本地语言的法律推理和文化知识)。我们研究了是否可以在不扩展大规模指令语料库或依赖复杂的偏好调整流程和大规模强化微调(RFT)的情况下实现这些要求。我们提出了Typhoon S,一种极简且开放的后训练方法,它结合了监督微调、在线蒸馏和小规模RFT。以泰语作为代表性案例研究,我们证明了我们的方法可以将主权适应和通用基础模型转化为具有强大通用性能的指令调整模型。我们进一步表明,使用InK-GRPO(GRPO的扩展,使用下一个词预测损失来增强GRPO损失)的小规模RFT可以提高泰语法律推理和泰语特定知识,同时保持通用能力。我们的结果表明,精心设计的后训练策略可以减少所需的指令数据和计算规模,从而为在学术规模资源下实现高质量的主权LLM提供了一条切实可行的途径。
🔬 方法详解
问题定义:论文旨在解决在资源有限且需要高度可控性的主权环境下,如何高效地训练高质量的大语言模型的问题。现有方法通常依赖于大规模的数据集和计算资源,这对于许多区域性或国家级的机构来说是难以负担的。此外,现有模型的透明度不足,使得这些机构难以理解和控制模型的行为。
核心思路:论文的核心思路是通过一种极简的后训练方法,在已有的基础模型上进行微调,使其具备通用能力和特定领域的能力。这种方法旨在减少对大规模数据和计算资源的依赖,同时提高模型的可控性和透明度。
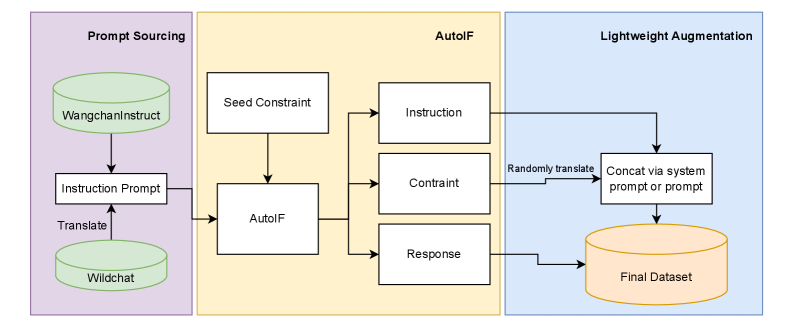
技术框架:Typhoon-S的整体框架包括三个主要阶段:1) 监督微调(SFT):使用指令数据对基础模型进行微调,使其具备基本的指令遵循能力。2) 在线蒸馏:利用教师模型生成的数据,对学生模型进行蒸馏训练,提高模型的性能和泛化能力。3) 小规模强化微调(RFT):使用强化学习方法,对模型进行进一步的微调,使其在特定领域(如法律推理)表现更好。
关键创新:该方法最重要的创新点在于其极简的设计,它能够在资源有限的情况下,通过精心设计的后训练策略,获得高质量的模型。此外,InK-GRPO的引入,通过结合下一个词预测损失,进一步提高了模型在特定领域的性能。
关键设计:在RFT阶段,论文提出了InK-GRPO,它是GRPO(Gradient Ratio Policy Optimization)的扩展,通过增加下一个词预测损失来增强GRPO损失。具体来说,InK-GRPO的目标函数是GRPO损失和下一个词预测损失的加权和。这种设计旨在提高模型在特定领域的知识和推理能力,同时保持其通用能力。具体的权重参数设置未知。
🖼️ 关键图片


📊 实验亮点
Typhoon-S在泰语法律推理和泰语特定知识方面取得了显著的提升,同时保持了良好的通用能力。通过小规模的RFT和InK-GRPO的结合,模型在特定领域的性能得到了进一步的增强。具体性能数据未知,但结果表明该方法在资源受限的情况下具有很强的竞争力。
🎯 应用场景
该研究成果可应用于需要高度可控性和透明度的场景,例如政府机构、法律机构和教育机构。它可以帮助这些机构在资源有限的情况下,构建具有特定领域知识和推理能力的大语言模型,从而提高工作效率和服务质量。此外,该方法还可以促进低资源语言的大语言模型发展。
📄 摘要(原文)
Large language models (LLMs) have progressed rapidly; however, most state-of-the-art models are trained and evaluated primarily in high-resource languages such as English and Chinese, and are often developed by a small number of organizations with access to large-scale compute and data. This gatekeeping creates a practical barrier for sovereign settings in which a regional- or national-scale institution or domain owner must retain control and understanding of model weights, training data, and deployment while operating under limited resources and strict transparency constraints. To this end, we identify two core requirements: (1) adoptability, the ability to transform a base model into a general-purpose assistant, and (2) sovereign capability, the ability to perform high-stakes, region-specific tasks (e.g., legal reasoning in local languages and cultural knowledge). We investigate whether these requirements can be achieved without scaling massive instruction corpora or relying on complex preference tuning pipelines and large-scale reinforcement fine-tuning (RFT). We present Typhoon S, a minimal and open post-training recipe that combines supervised fine-tuning, on-policy distillation, and small-scale RFT. Using Thai as a representative case study, we demonstrate that our approach transforms both sovereign-adapted and general-purpose base models into instruction-tuned models with strong general performance. We further show that small-scale RFT with InK-GRPO -- an extension of GRPO that augments the GRPO loss with a next-word prediction loss -- improves Thai legal reasoning and Thai-specific knowledge while preserving general capabilities. Our results suggest that a carefully designed post-training strategy can reduce the required scale of instruction data and computation, providing a practical path toward high-quality sovereign LLMs under academic-scale resources.