FABLE: Forest-Based Adaptive Bi-Path LLM-Enhanced Retrieval for Multi-Document Reasoning
作者: Lin Sun, Linglin Zhang, Jingang Huang, Change Jia, Zhengwei Cheng, Xiangzheng Zhang
分类: cs.CL
发布日期: 2026-01-26
💡 一句话要点
FABLE:提出一种基于森林结构的自适应双路径LLM增强检索框架,用于多文档推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 多文档推理 大语言模型 知识组织 分层索引
📋 核心要点
- 现有RAG系统在多文档推理中存在语义噪声和跨文档合成能力不足的问题,限制了其性能。
- FABLE通过构建LLM增强的分层森林索引,并结合双路径检索策略,实现细粒度的证据获取和效率权衡。
- 实验结果表明,FABLE在显著减少token数量的同时,性能优于SOTA RAG方法,并接近全上下文LLM推理。
📝 摘要(中文)
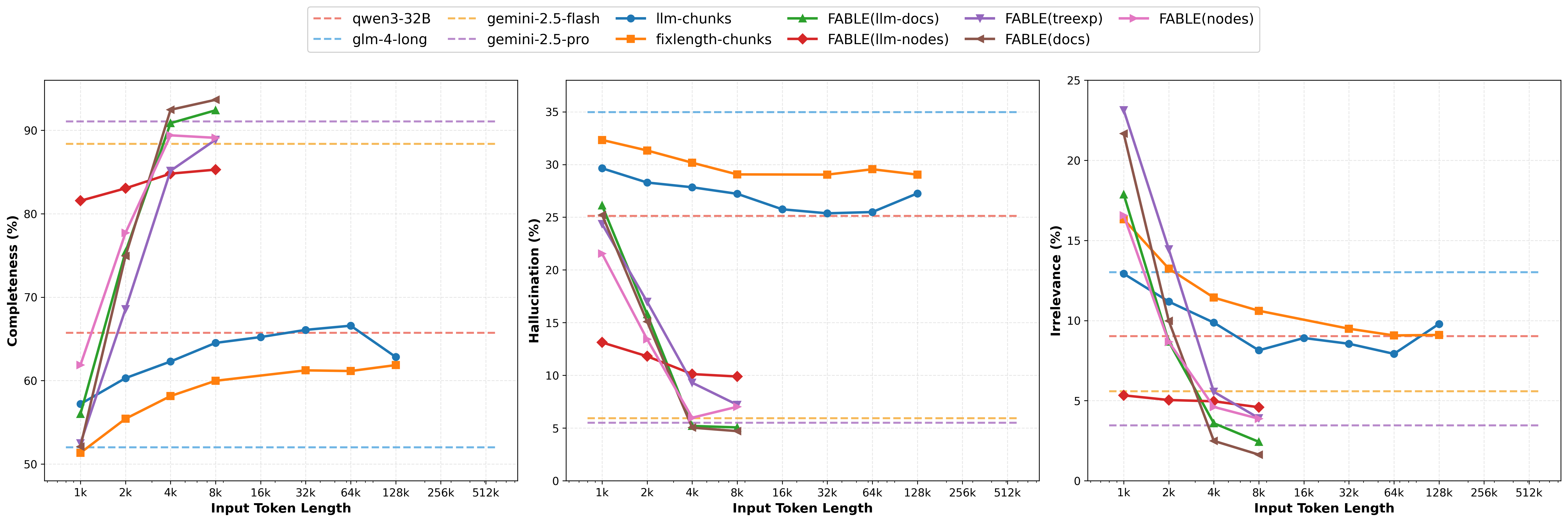
长文本大语言模型(LLM)的快速发展重新引发了关于检索增强生成(RAG)是否仍然必要的讨论。然而,经验证据表明,长文本推理仍然存在局限性,包括中间信息丢失现象、高计算成本以及多文档推理的可扩展性差。另一方面,传统的RAG系统虽然高效,但受到扁平的chunk级别检索的限制,这引入了语义噪声,并且无法支持结构化的跨文档合成。我们提出了FABLE,一个基于森林结构的自适应双路径LLM增强检索框架,它将LLM集成到知识组织和检索中。FABLE构建了具有多粒度语义结构的LLM增强分层森林索引,然后采用双路径策略,结合LLM引导的分层遍历和结构感知传播,以进行细粒度的证据获取,并通过显式的预算控制来实现自适应的效率权衡。大量实验表明,FABLE始终优于SOTA RAG方法,并且在减少高达94%的token数量的情况下,实现了与全上下文LLM推理相当的准确性,表明长文本LLM放大了而非完全取代了对结构化检索的需求。
🔬 方法详解
问题定义:论文旨在解决多文档推理中,传统RAG方法由于扁平的chunk级别检索引入语义噪声,以及无法有效进行跨文档结构化信息整合的问题。现有方法难以在效率和准确性之间取得平衡,尤其是在处理长上下文时,面临计算成本高昂和信息丢失的挑战。
核心思路:FABLE的核心思路是利用LLM增强的森林结构来组织知识,并采用双路径检索策略,结合LLM的推理能力和结构化知识的优势,实现高效且准确的证据获取。通过分层索引和自适应检索,在保证性能的同时,显著降低计算成本。
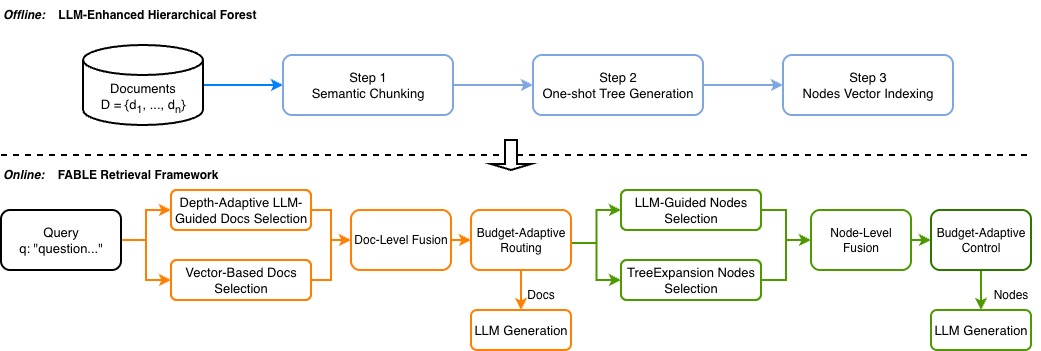
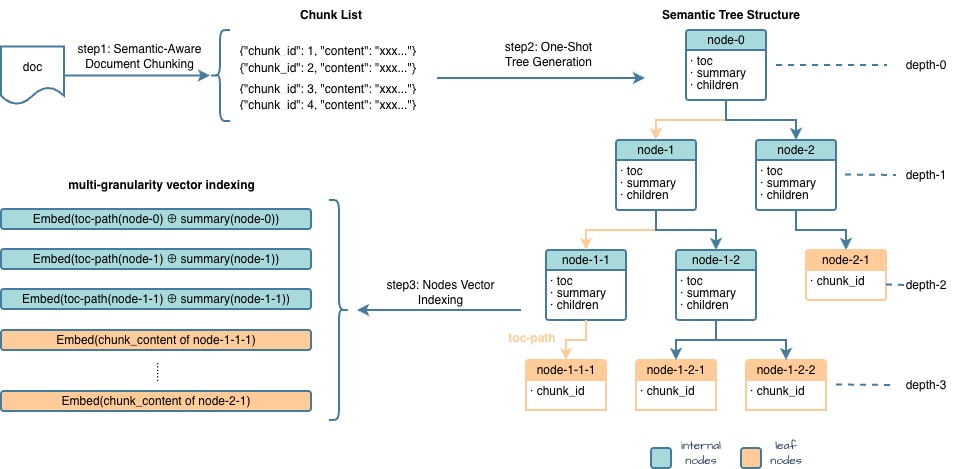
技术框架:FABLE框架主要包含两个阶段:知识组织和知识检索。在知识组织阶段,利用LLM构建多粒度的分层森林索引,将文档组织成具有语义结构的树状结构。在知识检索阶段,采用双路径策略,一条路径是LLM引导的分层遍历,另一条路径是结构感知的传播,最终融合两条路径的结果,得到最终的检索结果。框架还包含一个预算控制模块,用于在效率和准确性之间进行权衡。
关键创新:FABLE的关键创新在于将LLM集成到知识组织和检索的整个流程中,构建了LLM增强的分层森林索引,并提出了双路径检索策略。与传统的RAG方法相比,FABLE能够更好地利用LLM的推理能力,同时避免了扁平检索带来的语义噪声。此外,自适应预算控制机制使得FABLE能够在不同的计算资源下实现最佳的性能。
关键设计:在知识组织阶段,使用LLM对文档进行语义分析,提取关键信息,并构建多粒度的分层结构。在检索阶段,LLM引导的分层遍历利用LLM的推理能力,逐步缩小搜索范围。结构感知传播则利用森林结构的拓扑信息,进行信息的传递和聚合。预算控制模块通过调整LLM的调用次数和检索深度,实现效率和准确性的权衡。具体的参数设置和损失函数等技术细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FABLE在多文档推理任务中,性能始终优于SOTA RAG方法。在减少高达94%的token数量的情况下,FABLE实现了与全上下文LLM推理相当的准确性。这些结果表明,FABLE能够有效地利用LLM的推理能力和结构化知识,在保证性能的同时,显著降低计算成本。
🎯 应用场景
FABLE可应用于需要处理大量文档并进行复杂推理的场景,例如金融分析、法律咨询、医学诊断等。该研究可以提高信息检索的效率和准确性,帮助用户快速找到所需信息,并支持更深入的知识发现和决策制定。未来,FABLE有望成为构建智能问答系统和知识图谱的重要组成部分。
📄 摘要(原文)
The rapid expansion of long-context Large Language Models (LLMs) has reignited debate on whether Retrieval-Augmented Generation (RAG) remains necessary. However, empirical evidence reveals persistent limitations of long-context inference, including the lost-in-the-middle phenomenon, high computational cost, and poor scalability for multi-document reasoning. Conversely, traditional RAG systems, while efficient, are constrained by flat chunk-level retrieval that introduces semantic noise and fails to support structured cross-document synthesis. We present \textbf{FABLE}, a \textbf{F}orest-based \textbf{A}daptive \textbf{B}i-path \textbf{L}LM-\textbf{E}nhanced retrieval framework that integrates LLMs into both knowledge organization and retrieval. FABLE constructs LLM-enhanced hierarchical forest indexes with multi-granularity semantic structures, then employs a bi-path strategy combining LLM-guided hierarchical traversal with structure-aware propagation for fine-grained evidence acquisition, with explicit budget control for adaptive efficiency trade-offs. Extensive experiments demonstrate that FABLE consistently outperforms SOTA RAG methods and achieves comparable accuracy to full-context LLM inference with up to 94\% token reduction, showing that long-context LLMs amplify rather than fully replace the need for structured retrieval.