Sparks of Cooperative Reasoning: LLMs as Strategic Hanabi Agents
作者: Mahesh Ramesh, Kaousheik Jayakumar, Aswinkumar Ramkumar, Pavan Thodima, Aniket Rege
分类: cs.CL
发布日期: 2026-01-26
💡 一句话要点
利用大型语言模型进行合作推理:作为花火战略智能体
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 合作推理 花火游戏 上下文工程 强化学习
📋 核心要点
- 现有方法在不完全信息下的合作推理能力不足,尤其是在需要心智理论和战略沟通的复杂游戏中,如花火。
- 论文提出通过上下文工程,结合程序化推理、贝叶斯推断和工作记忆等机制,提升大型语言模型在合作推理任务中的表现。
- 实验结果表明,经过监督和强化学习微调的4B模型在花火游戏中取得了显著提升,并在其他合作推理任务中展现出泛化能力。
📝 摘要(中文)
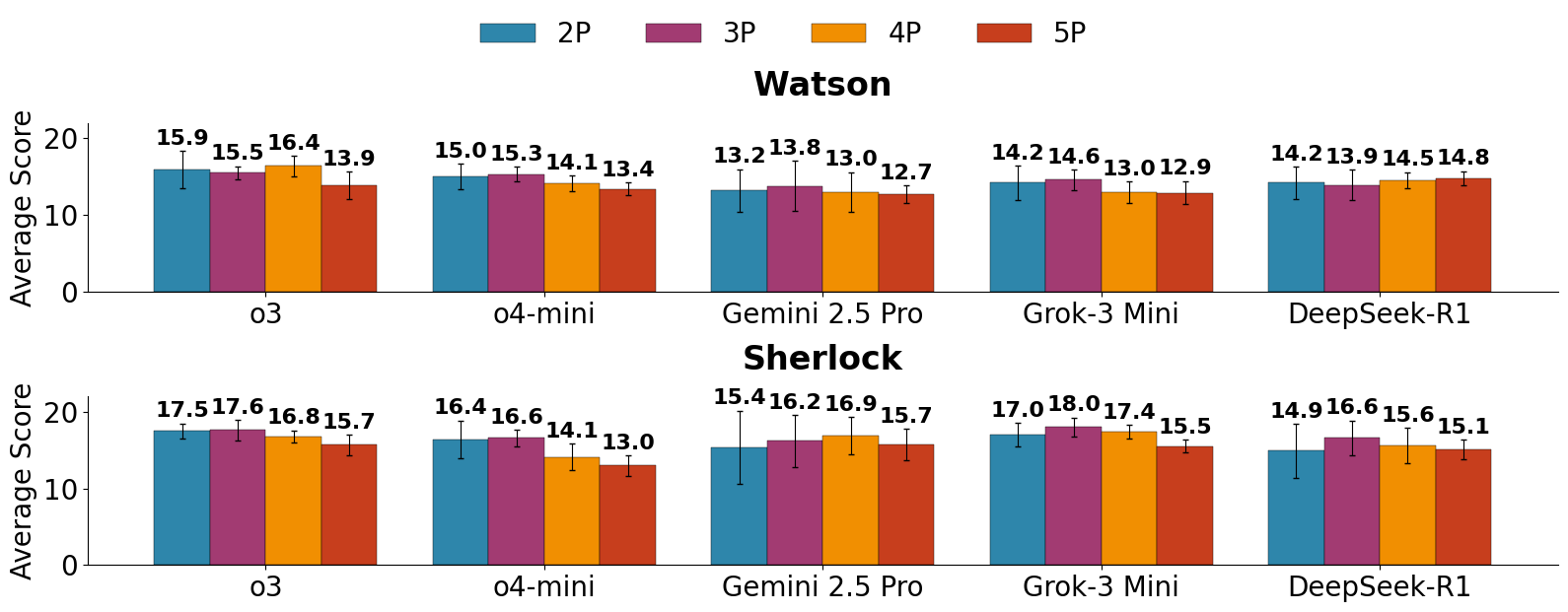
在不完全信息下进行合作推理对人类和多智能体系统来说仍然具有挑战性。纸牌游戏“花火”体现了这一挑战,它需要心智理论推理和战略沟通。本文在2-5人游戏中对17个最先进的LLM智能体进行了基准测试,并研究了跨模型规模(4B到600B+)的上下文工程的影响,以了解持续的协调失败和对脚手架的鲁棒性:从只有显式卡牌细节的最小提示(Watson设置),到具有程序化的、贝叶斯动机的推论的脚手架(Sherlock设置),再到通过工作记忆进行多轮状态跟踪(Mycroft设置)。结果表明:(1)智能体可以维护内部工作记忆以进行状态跟踪;(2)不同LLM之间的交叉对战性能随模型强度平滑插值。在Sherlock设置中,最强的推理模型在不同玩家数量下平均超过15分,但仍然落后于经验丰富的人类和专业的花火智能体,它们都始终得分高于20分。本文发布了第一个公开的花火数据集,其中包含带注释的轨迹和移动效用:(1)HanabiLogs,包含1,520个完整的游戏日志,用于指令微调;(2)HanabiRewards,包含560个游戏,其中包含所有候选移动的密集移动级别价值注释。在我们的数据集上对4B开放权重模型(Qwen3-Instruct)进行监督和强化学习微调,分别将合作花火游戏性能提高了21%和156%,使性能达到接近强大的专有推理模型(o4-mini)约3分的水平,并超过了最佳的非推理模型(GPT-4.1)52%。HanabiRewards强化学习微调模型进一步泛化到花火之外,在合作群体猜测基准测试中提高了11%的性能,在EventQA上的时间推理提高了6.4%,在IFBench-800K上的指令遵循提高了1.7 Pass@10,并匹配了AIME 2025数学推理Pass@10。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在不完全信息下进行合作推理的难题,特别是在需要高度策略性和沟通技巧的“花火”纸牌游戏中。现有方法,如直接使用LLMs进行决策,往往无法有效模拟人类玩家的心智理论和战略沟通,导致合作效率低下。
核心思路:论文的核心思路是通过上下文工程(context engineering)来增强LLMs的合作推理能力。具体来说,通过构建不同的提示策略,例如提供显式卡牌信息、程序化的贝叶斯推断结果以及多轮状态跟踪的工作记忆,来引导LLMs进行更有效的推理和决策。这种方法旨在弥补LLMs在处理不完全信息和复杂策略时的不足。
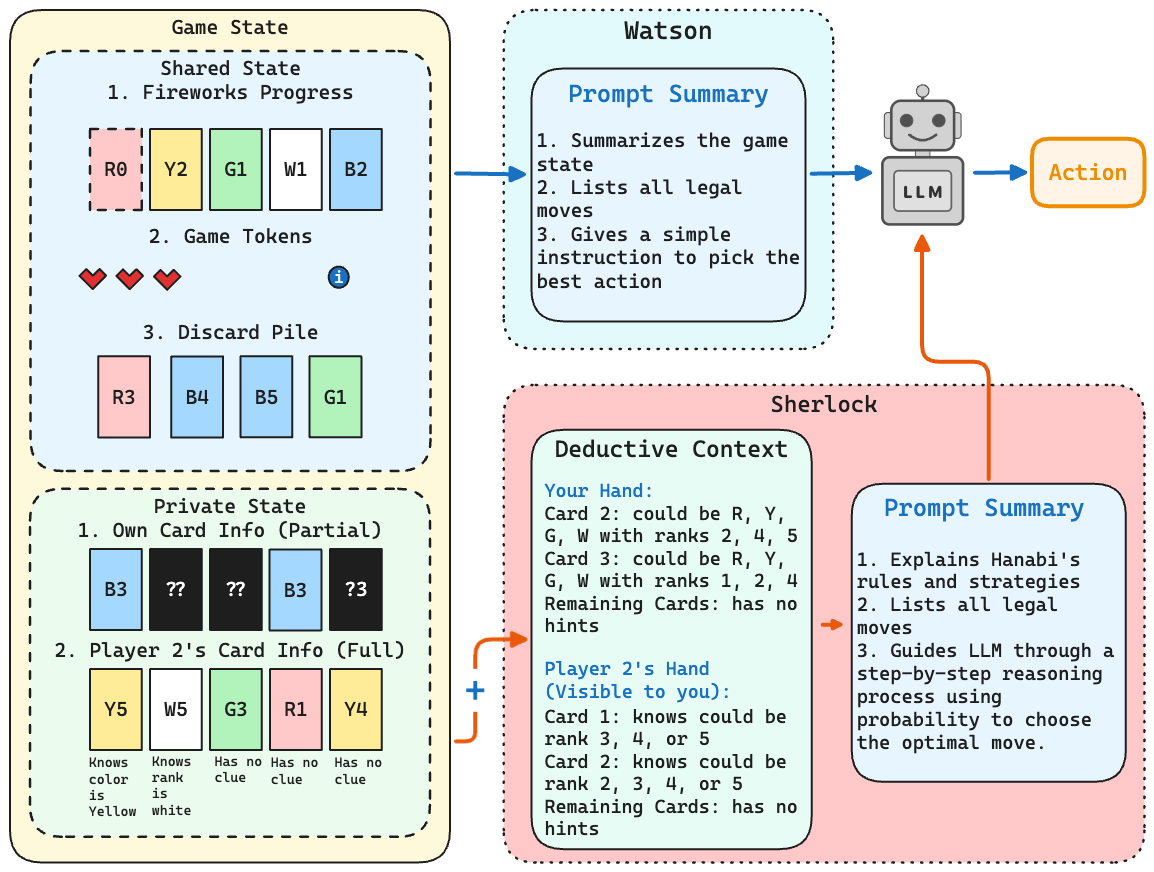
技术框架:整体框架包括三个主要的设置:Watson(最小提示,仅包含显式卡牌信息)、Sherlock(在Watson的基础上增加程序化的贝叶斯推断结果)和Mycroft(在Sherlock的基础上增加多轮状态跟踪的工作记忆)。LLMs作为智能体参与花火游戏,根据当前游戏状态和提示信息做出行动决策。游戏轨迹被记录下来,用于后续的监督学习和强化学习微调。此外,论文还构建了HanabiLogs和HanabiRewards两个数据集,分别用于指令微调和强化学习。
关键创新:论文的关键创新在于系统性地研究了不同上下文工程策略对LLMs合作推理能力的影响。通过对比不同设置下的模型表现,揭示了程序化推理和工作记忆对提升合作效率的重要性。此外,论文还通过构建高质量的花火数据集,为进一步研究LLMs在合作推理方面的能力提供了宝贵资源。
关键设计:在Sherlock设置中,使用了贝叶斯推断来计算每张卡牌的可能性,并将这些推断结果作为提示信息提供给LLMs。在Mycroft设置中,LLMs维护一个工作记忆,用于跟踪游戏状态和玩家之间的沟通信息。在强化学习微调中,使用了PPO算法,并根据HanabiRewards数据集中的移动价值注释来设计奖励函数。Qwen3-Instruct (4B) 模型被用作微调的基础模型。
🖼️ 关键图片
📊 实验亮点
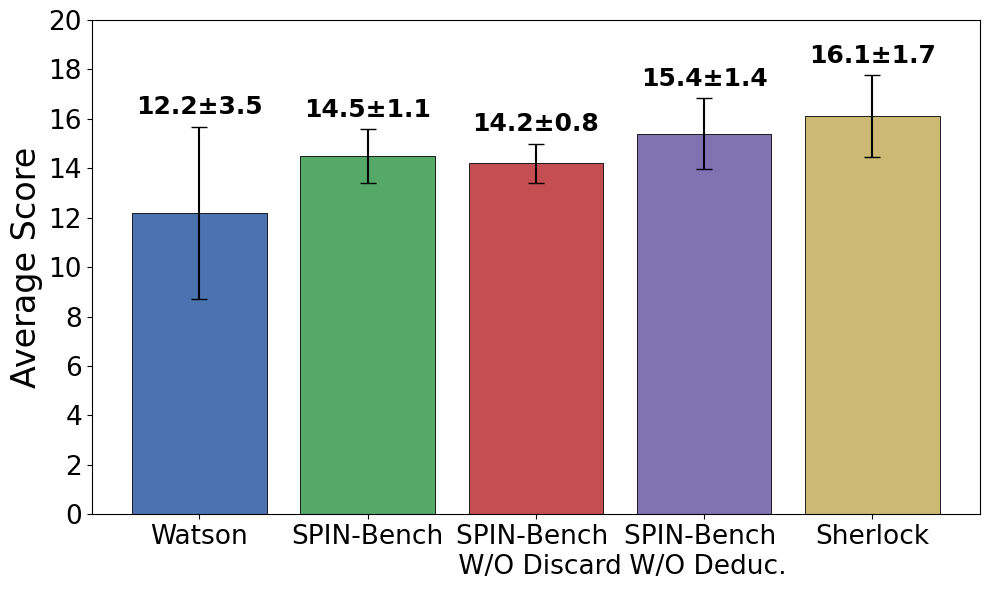
实验结果表明,在Sherlock设置下,最强的推理模型在花火游戏中平均得分超过15分,但仍低于人类专家和专业智能体(>20分)。通过在HanabiLogs和HanabiRewards数据集上进行微调,Qwen3-Instruct模型在花火游戏中的性能分别提升了21%和156%,接近专有模型o4-mini,并超越了GPT-4.1。此外,该模型在其他合作推理任务中也展现出泛化能力。
🎯 应用场景
该研究成果可应用于多智能体协作系统、人机协作、以及需要复杂推理和沟通的决策场景。例如,在自动驾驶中,多个车辆需要协同规划路线以避免拥堵;在医疗诊断中,多个专家系统需要共享信息并达成共识。该研究有助于提升智能体在复杂环境下的合作能力,实现更高效、更可靠的协作。
📄 摘要(原文)
Cooperative reasoning under incomplete information remains challenging for both humans and multi-agent systems. The card game Hanabi embodies this challenge, requiring theory-of-mind reasoning and strategic communication. We benchmark 17 state-of-the-art LLM agents in 2-5 player games and study the impact of context engineering across model scales (4B to 600B+) to understand persistent coordination failures and robustness to scaffolding: from a minimal prompt with only explicit card details (Watson setting), to scaffolding with programmatic, Bayesian-motivated deductions (Sherlock setting), to multi-turn state tracking via working memory (Mycroft setting). We show that (1) agents can maintain an internal working memory for state tracking and (2) cross-play performance between different LLMs smoothly interpolates with model strength. In the Sherlock setting, the strongest reasoning models exceed 15 points on average across player counts, yet still trail experienced humans and specialist Hanabi agents, both consistently scoring above 20. We release the first public Hanabi datasets with annotated trajectories and move utilities: (1) HanabiLogs, containing 1,520 full game logs for instruction tuning, and (2) HanabiRewards, containing 560 games with dense move-level value annotations for all candidate moves. Supervised and RL finetuning of a 4B open-weight model (Qwen3-Instruct) on our datasets improves cooperative Hanabi play by 21% and 156% respectively, bringing performance to within ~3 points of a strong proprietary reasoning model (o4-mini) and surpassing the best non-reasoning model (GPT-4.1) by 52%. The HanabiRewards RL-finetuned model further generalizes beyond Hanabi, improving performance on a cooperative group-guessing benchmark by 11%, temporal reasoning on EventQA by 6.4%, instruction-following on IFBench-800K by 1.7 Pass@10, and matching AIME 2025 mathematical reasoning Pass@10.