Grounded Concreteness: Human-Like Concreteness Sensitivity in Vision-Language Models
作者: Aryan Roy, Zekun Wang, Christopher J. MacLellan
分类: cs.CL
发布日期: 2026-01-26
💡 一句话要点
研究视觉语言模型对具体概念的敏感性,揭示其更接近人类的理解能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 语言具体性 多模态学习 感知基础 注意力机制
📋 核心要点
- 现有大型语言模型在理解语言具体性方面存在不足,缺乏对物理世界的感知。
- 通过对比视觉语言模型和纯文本模型,研究多模态预训练对模型理解具体概念的影响。
- 实验表明,视觉语言模型在处理具体概念时表现更好,更接近人类的理解方式。
📝 摘要(中文)
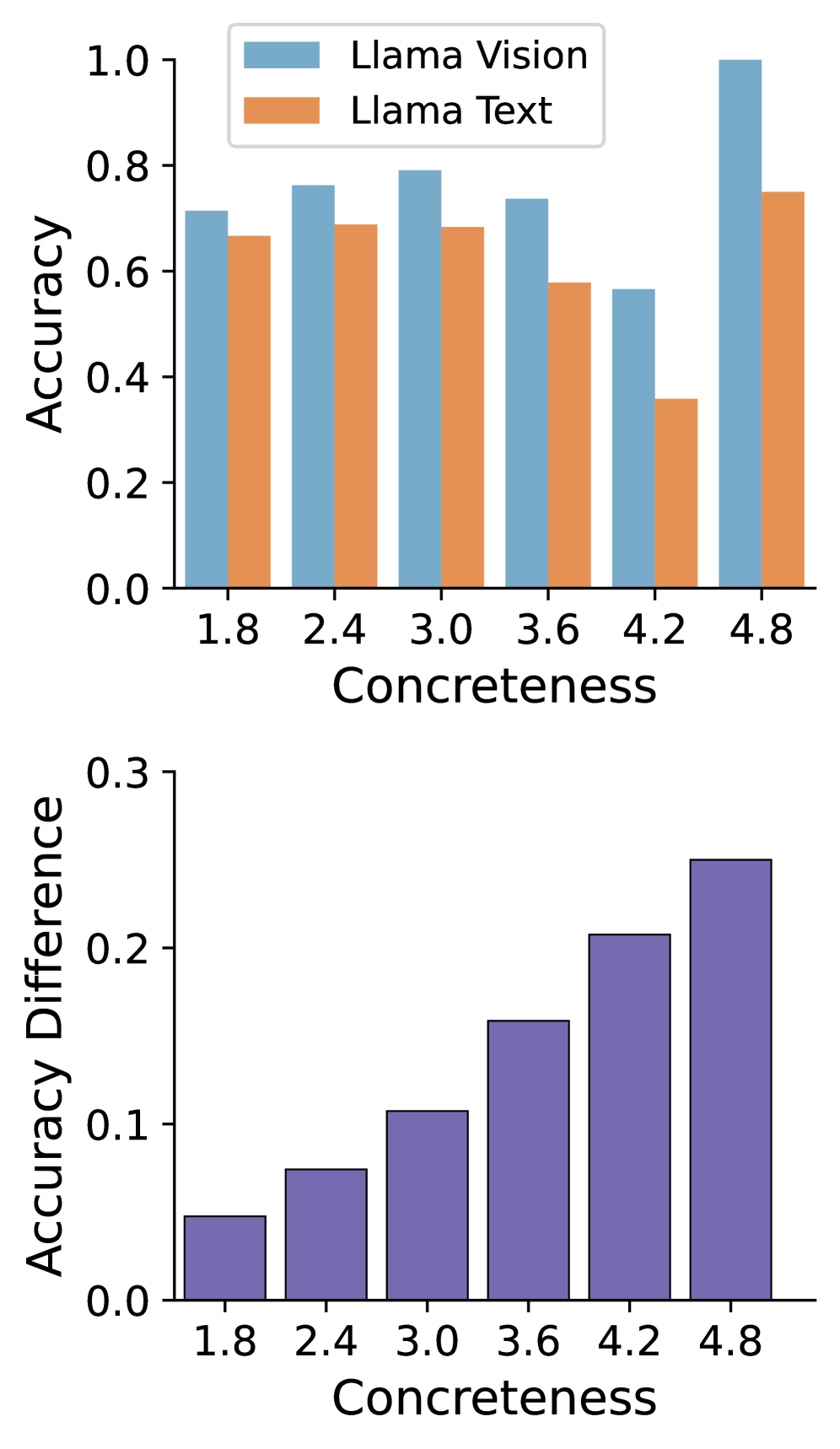
本文研究了视觉语言模型(VLMs)在仅使用文本提示进行评估时,是否比纯文本大型语言模型(LLMs)对语言具体性的敏感度更高。通过在多个模型规模上,对匹配的Llama文本骨干网络及其Llama Vision对应网络进行受控比较,将多模态预训练视为感知基础的一种消融,而非推理时访问图像。我们在三个互补的层面上衡量具体性效应:(i)输出行为,通过将问题层面的具体性与QA准确率联系起来;(ii)嵌入几何,通过测试表征是否沿着具体性轴组织;(iii)注意力动态,通过注意力熵度量量化上下文依赖性。此外,我们从模型中提取token级别的具体性评分,并评估与人类规范分布的对齐情况,测试多模态训练是否产生更符合人类一致性的判断。在各个基准和规模上,VLMs在更具体的输入上表现出更大的增益,表现出更清晰的具有具体性结构的表征,产生更符合人类规范的评分,并显示出与增加的基础相一致的系统性不同的注意力模式。
🔬 方法详解
问题定义:现有的大型语言模型,尤其是纯文本模型,在理解语言中的具体性(concreteness)方面存在局限。它们缺乏与物理世界的直接感知联系,导致在处理涉及具体事物和场景的语言时表现不佳。论文旨在研究视觉语言模型(VLMs)是否能够通过多模态预训练,获得更接近人类的对具体概念的敏感性。
核心思路:论文的核心思路是将多模态预训练视为一种“感知基础”(perceptual grounding)的手段,而非仅仅是推理时访问图像的能力。通过对比经过多模态预训练的VLMs和仅经过文本训练的LLMs,研究视觉信息对模型理解具体概念的影响。核心假设是,VLMs能够通过视觉信息的辅助,更好地理解和处理与具体事物相关的语言。
技术框架:论文采用了一种受控的比较实验框架。首先,选择Llama作为文本骨干网络,并构建其对应的视觉语言模型Llama Vision。然后,在多个模型规模上,对这两种模型进行比较。评估指标包括:(1)输出行为,通过分析问题具体性与QA准确率的关系;(2)嵌入几何,通过测试表征是否沿着具体性轴组织;(3)注意力动态,通过注意力熵度量量化上下文依赖性。此外,还从模型中提取token级别的具体性评分,并与人类规范分布进行比较。
关键创新:论文的关键创新在于将多模态预训练视为一种“感知基础”的手段,并系统地研究了其对模型理解语言具体性的影响。通过多方面的评估指标,揭示了VLMs在处理具体概念时,在输出行为、表征结构和注意力模式等方面都更接近人类的理解方式。此外,论文还提出了token级别的具体性评分,并将其与人类规范分布进行比较,为评估模型的具体性理解能力提供了一种新的方法。
关键设计:论文的关键设计包括:(1)选择Llama作为文本骨干网络,保证了文本能力的可比性;(2)采用多种评估指标,从不同角度衡量模型的具体性理解能力;(3)进行受控的比较实验,确保了实验结果的可靠性;(4)提出token级别的具体性评分,并将其与人类规范分布进行比较,为评估模型的具体性理解能力提供了一种新的方法。具体参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,视觉语言模型在处理更具体的输入时表现出更大的性能提升。VLMs展现出更清晰的具有具体性结构的表征,其产生的具体性评分更符合人类规范。此外,VLMs还表现出与增加的基础相一致的系统性不同的注意力模式。具体的性能数据和提升幅度未在摘要中详细说明,属于未知信息。
🎯 应用场景
该研究成果可应用于提升视觉语言模型在常识推理、视觉问答、图像描述等任务中的性能。通过增强模型对具体概念的理解,可以使其更好地理解和处理与物理世界相关的语言,从而在机器人控制、人机交互等领域发挥更大的作用。未来,该研究可以进一步扩展到其他模态,例如声音、触觉等,以构建更全面、更智能的多模态人工智能系统。
📄 摘要(原文)
Do vision--language models (VLMs) develop more human-like sensitivity to linguistic concreteness than text-only large language models (LLMs) when both are evaluated with text-only prompts? We study this question with a controlled comparison between matched Llama text backbones and their Llama Vision counterparts across multiple model scales, treating multimodal pretraining as an ablation on perceptual grounding rather than access to images at inference. We measure concreteness effects at three complementary levels: (i) output behavior, by relating question-level concreteness to QA accuracy; (ii) embedding geometry, by testing whether representations organize along a concreteness axis; and (iii) attention dynamics, by quantifying context reliance via attention-entropy measures. In addition, we elicit token-level concreteness ratings from models and evaluate alignment to human norm distributions, testing whether multimodal training yields more human-consistent judgments. Across benchmarks and scales, VLMs show larger gains on more concrete inputs, exhibit clearer concreteness-structured representations, produce ratings that better match human norms, and display systematically different attention patterns consistent with increased grounding.