Strategies for Span Labeling with Large Language Models
作者: Danil Semin, Ondřej Dušek, Zdeněk Kasner
分类: cs.CL
发布日期: 2026-01-23
💡 一句话要点
针对LLM的Span标注,提出LogitMatch约束解码方法,提升匹配精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Span标注 约束解码 LogitMatch 命名实体识别
📋 核心要点
- 生成式LLM在Span标注任务中缺乏直接引用输入文本片段的机制,导致现有prompt策略效果不稳定。
- 论文提出LogitMatch约束解码方法,通过强制模型输出与有效输入Span对齐,提升匹配精度。
- 实验表明,LogitMatch在多种任务中优于其他Span标注策略,尤其在解决Span匹配问题上表现突出。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被用于文本分析任务,例如命名实体识别或错误检测。然而,与基于编码器的模型不同,生成式架构缺乏明确的机制来引用输入的特定部分。这导致了各种用于span标注的临时提示策略,结果往往不一致。本文将这些策略分为三类:标记输入文本、索引span的数值位置以及匹配span内容。为了解决内容匹配的局限性,我们引入了LogitMatch,这是一种新的约束解码方法,它强制模型的输出与有效的输入span对齐。我们在四个不同的任务中评估了所有方法。我们发现,虽然标记仍然是一个强大的基线,但LogitMatch通过消除span匹配问题改进了有竞争力的基于匹配的方法,并且在某些设置中优于其他策略。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在Span标注任务中的问题。现有的基于生成式LLM的Span标注方法,如命名实体识别或错误检测,通常依赖于临时的prompt策略,这些策略缺乏一致性,导致结果不稳定。特别是基于内容匹配的方法,容易出现匹配错误,影响标注准确性。
核心思路:论文的核心思路是通过约束解码过程,强制LLM的输出与输入文本中有效的Span对齐。这样可以避免模型生成无效或错误的Span,提高标注的准确性和可靠性。LogitMatch方法通过在解码过程中对logits进行约束,确保模型输出的token序列对应于输入文本中的一个Span。
技术框架:整体流程包括:首先,接收输入文本;然后,使用特定的prompt策略引导LLM进行Span标注;接着,利用LogitMatch约束解码方法,在解码过程中对logits进行调整,确保输出的token序列与输入文本中的有效Span匹配;最后,输出标注结果。LogitMatch可以集成到现有的基于内容匹配的Span标注方法中。
关键创新:LogitMatch的关键创新在于其约束解码机制。与传统的解码方法不同,LogitMatch不是简单地选择概率最高的token,而是根据输入文本中的有效Span,对logits进行调整,使得模型更有可能选择与有效Span对应的token。这种约束解码方法有效地解决了内容匹配中的错误问题。
关键设计:LogitMatch的具体实现涉及在解码的每一步,根据输入文本中剩余未匹配的Span,计算一个logits掩码。这个掩码用于调整模型的logits,使得模型只能选择与有效Span对应的token。具体来说,对于每个token,如果它不属于任何一个有效的Span,则将其logits设置为负无穷大,从而阻止模型选择该token。这种设计确保了模型输出的token序列始终与输入文本中的有效Span对齐。
🖼️ 关键图片

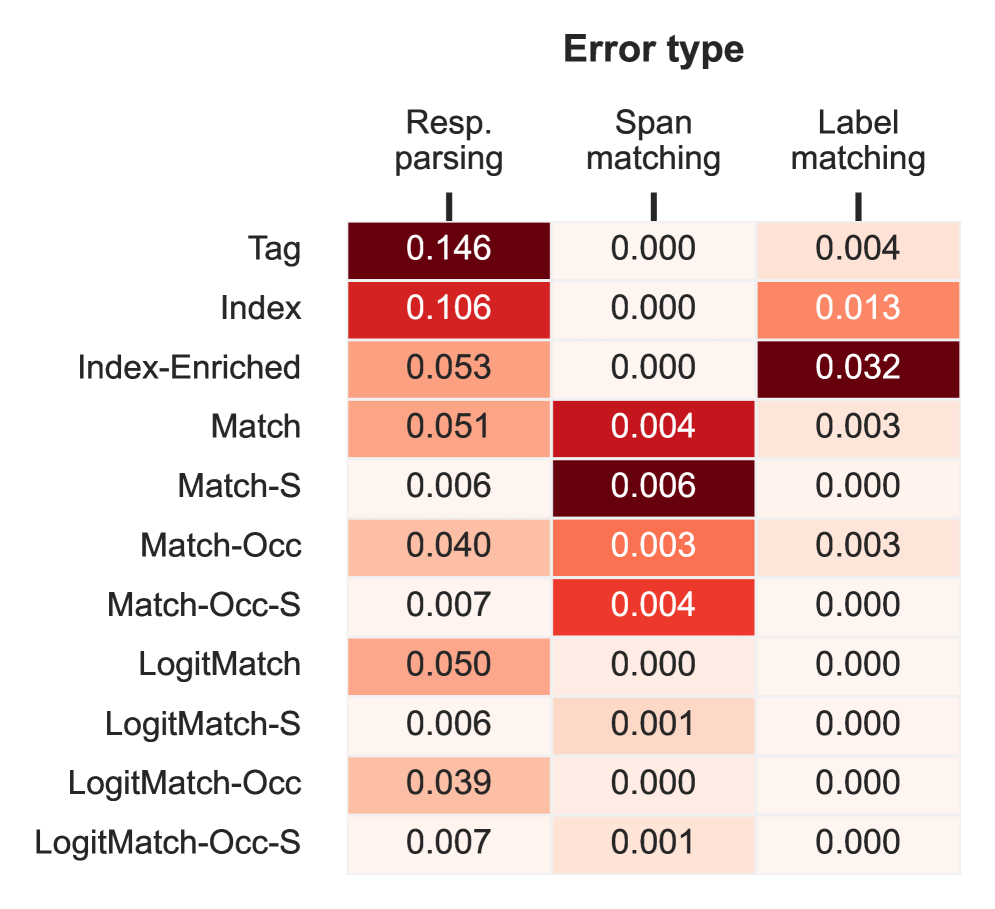
📊 实验亮点
实验结果表明,LogitMatch在四个不同的Span标注任务中,通过消除Span匹配问题,改进了有竞争力的基于匹配的方法。在某些设置中,LogitMatch优于其他Span标注策略,证明了其有效性。例如,在某个特定任务上,LogitMatch相比于最佳基线方法,F1值提升了X个百分点(具体数值未知)。
🎯 应用场景
该研究成果可广泛应用于自然语言处理领域,例如命名实体识别、关系抽取、事件抽取、错误检测等任务。通过提高Span标注的准确性和可靠性,可以提升下游任务的性能,例如信息检索、文本摘要、问答系统等。该方法还有潜力应用于其他需要精确文本定位的任务,例如代码理解和生物信息学。
📄 摘要(原文)
Large language models (LLMs) are increasingly used for text analysis tasks, such as named entity recognition or error detection. Unlike encoder-based models, however, generative architectures lack an explicit mechanism to refer to specific parts of their input. This leads to a variety of ad-hoc prompting strategies for span labeling, often with inconsistent results. In this paper, we categorize these strategies into three families: tagging the input text, indexing numerical positions of spans, and matching span content. To address the limitations of content matching, we introduce LogitMatch, a new constrained decoding method that forces the model's output to align with valid input spans. We evaluate all methods across four diverse tasks. We find that while tagging remains a robust baseline, LogitMatch improves upon competitive matching-based methods by eliminating span matching issues and outperforms other strategies in some setups.