Trapped in the past? Disentangling fluid and crystallized intelligence of large language models using chess
作者: Leonard S. Pleiss, Maximilian Schiffer, Robert K. von Weizsäcker
分类: cs.CL, cs.AI
发布日期: 2026-01-23
💡 一句话要点
利用国际象棋解耦大语言模型的流体智力和晶体智力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 流体智力 晶体智力 国际象棋 推理能力 泛化能力 模型评估
📋 核心要点
- 大型语言模型的能力日益强大,但其推理能力与记忆能力之间的界限仍不清晰,需要更细致的评估方法。
- 论文提出使用国际象棋作为测试平台,通过控制棋局的训练集接近程度,区分模型对已知棋局的记忆和对未知棋局的推理能力。
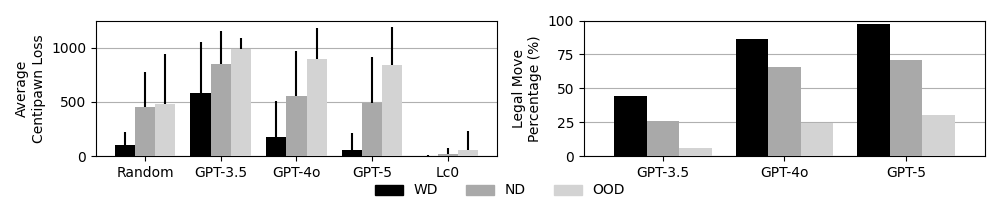
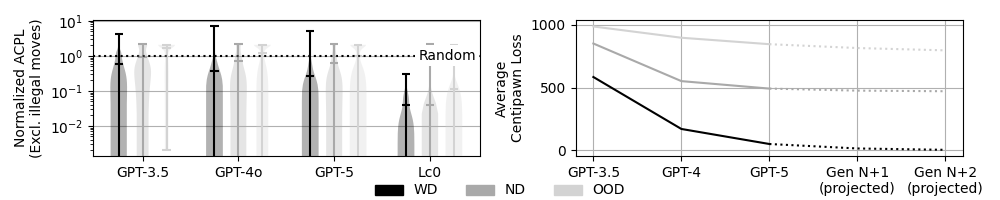
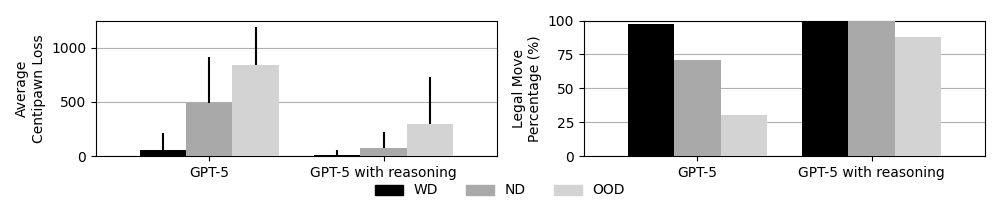
- 实验结果表明,随着棋局的陌生程度增加,模型性能显著下降,即使是推理增强的方法,其收益也会随着棋局的陌生程度而降低。
📝 摘要(中文)
大型语言模型(LLM)展现出卓越的能力,但这些能力在多大程度上反映了复杂的记忆(晶体智力)或推理能力(流体智力)仍不清楚。本文引入国际象棋作为一个受控的试验平台,用于解耦这些能力。利用游戏的结构和可扩展的引擎评估,我们构建了一个位置分类体系,这些位置在训练语料库中的接近程度各不相同——从可以通过记忆解决的常见状态到需要第一性原理推理的新颖状态。我们系统地评估了不同推理强度下的多个GPT生成结果。我们的分析揭示了一个清晰的梯度:随着流体智力需求的增加,性能持续下降。值得注意的是,在分布外的任务中,性能会崩溃到随机水平。虽然较新的模型有所改进,但对于训练分布之外的任务,进展显着放缓。此外,虽然推理增强的推理提高了性能,但每次token的边际效益随着分布接近度的增加而降低。这些结果表明,当前的架构在系统泛化方面仍然受到限制,突出了除了规模之外,还需要其他机制来实现强大的流体智力。
🔬 方法详解
问题定义:论文旨在区分大型语言模型(LLM)的晶体智力(即记忆能力)和流体智力(即推理能力)。现有方法难以有效分离这两种能力,因为LLM在训练过程中学习了大量知识,很难判断其行为是基于记忆还是推理。因此,需要一种可控的测试环境,能够系统地改变任务的难度,从而区分这两种能力。
核心思路:论文的核心思路是利用国际象棋作为测试平台。国际象棋具有明确的规则和结构,可以通过控制棋局的复杂度和在训练数据中出现的频率来调节任务的难度。通过评估LLM在不同难度棋局上的表现,可以推断其推理能力和记忆能力。
技术框架:论文的技术框架主要包括以下几个部分:1) 构建国际象棋棋局数据集,该数据集包含不同难度和训练集接近程度的棋局;2) 使用不同的GPT模型(包括不同版本和规模的模型)在这些棋局上进行测试;3) 评估模型在不同推理强度下的表现,例如使用不同的prompt策略和解码方法;4) 分析模型在不同难度棋局上的表现,从而推断其推理能力和记忆能力。
关键创新:论文的关键创新在于将国际象棋作为一种可控的测试平台,用于评估LLM的推理能力。与传统的自然语言处理任务相比,国际象棋具有更明确的规则和结构,可以更精确地控制任务的难度。此外,论文还提出了一种新的方法来评估LLM的推理强度,通过改变prompt策略和解码方法,可以调节模型的推理过程。
关键设计:论文的关键设计包括:1) 棋局数据集的构建,需要选择具有代表性的棋局,并控制其难度和训练集接近程度;2) prompt策略的设计,需要选择合适的prompt,引导模型进行推理;3) 评估指标的选择,需要选择能够反映模型推理能力的指标,例如棋局的胜率和走法的合理性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,随着棋局的难度增加,GPT模型的性能显著下降,尤其是在分布外的棋局中,性能接近随机水平。推理增强的策略虽然可以提高性能,但其边际效益随着棋局的熟悉程度而降低。这些结果表明,当前LLM在系统泛化方面存在局限性,需要进一步提升其推理能力。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型的推理能力。通过国际象棋测试平台,可以更准确地了解模型的优势和不足,从而指导模型架构设计、训练数据选择和推理策略优化。此外,该方法还可以推广到其他需要推理能力的任务中,例如数学问题求解、逻辑推理等。
📄 摘要(原文)
Large Language Models (LLMs) exhibit remarkable capabilities, yet it remains unclear to what extent these reflect sophisticated recall (crystallized intelligence) or reasoning ability (fluid intelligence). We introduce chess as a controlled testbed for disentangling these faculties. Leveraging the game's structure and scalable engine evaluations, we construct a taxonomy of positions varying in training corpus proximity--ranging from common states solvable by memorization to novel ones requiring first-principles reasoning. We systematically evaluate multiple GPT generations under varying reasoning intensities. Our analysis reveals a clear gradient: performance consistently degrades as fluid intelligence demands increase. Notably, in out-of-distribution tasks, performance collapses to random levels. While newer models improve, progress slows significantly for tasks outside the training distribution. Furthermore, while reasoning-augmented inference improves performance, its marginal benefit per token decreases with distributional proximity. These results suggest current architectures remain limited in systematic generalization, highlighting the need for mechanisms beyond scale to achieve robust fluid intelligence.