Large Language Models as Automatic Annotators and Annotation Adjudicators for Fine-Grained Opinion Analysis
作者: Gaurav Negi, MA Waskow, Paul Buitelaar
分类: cs.CL
发布日期: 2026-01-23
💡 一句话要点
利用大语言模型作为自动标注器和仲裁器,解决细粒度情感分析的数据标注难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 自动标注 情感分析 细粒度情感分析 标注仲裁 自然语言处理 声明式标注
📋 核心要点
- 细粒度情感分析标注成本高昂,领域数据集稀缺,限制了模型训练和实际应用。
- 提出利用LLM作为自动标注器和仲裁器,通过声明式流程降低人工干预,提升标注一致性。
- 实验表明LLM标注器在ASTE和ACOS任务上表现出高标注一致性,降低了标注成本。
📝 摘要(中文)
本文探讨了利用大型语言模型(LLM)作为自动标注器,进行细粒度情感分析的可行性,旨在解决领域特定标注数据集的短缺问题。细粒度情感分析能够深入理解文本中表达的情感,包括所涉及的实体。然而,为此类模型训练数据集进行标注需要大量的人力和物力,尤其是在跨领域和实际应用中。本文采用一种声明式的标注流程,减少了在使用LLM识别文本中细粒度情感跨度时手动提示工程的可变性。此外,还提出了一种新颖的方法,使LLM能够仲裁多个标签并生成最终标注。通过对不同规模的模型进行方面情感三元组抽取(ASTE)和方面-类别-观点-情感(ACOS)分析任务的试验,结果表明LLM可以作为自动标注器和仲裁器,并在基于LLM的个体标注器之间实现高标注者间一致性,从而降低创建这些细粒度情感标注数据集的成本和人力投入。
🔬 方法详解
问题定义:细粒度情感分析需要对文本中表达的情感及其对象进行精细标注,例如“用户对A产品的B功能的情感是C”。传统方法依赖人工标注,成本高、效率低,且难以保证标注一致性,尤其是在领域知识要求高的场景下。现有方法缺乏有效的自动化标注方案,限制了细粒度情感分析的广泛应用。
核心思路:利用大型语言模型(LLM)的强大语言理解和生成能力,将其作为自动标注器和仲裁器。通过精心设计的提示(prompt)和声明式标注流程,引导LLM识别文本中的情感元素,并生成相应的标注。同时,设计一种LLM仲裁机制,解决多个LLM标注结果不一致的问题,提高标注质量。
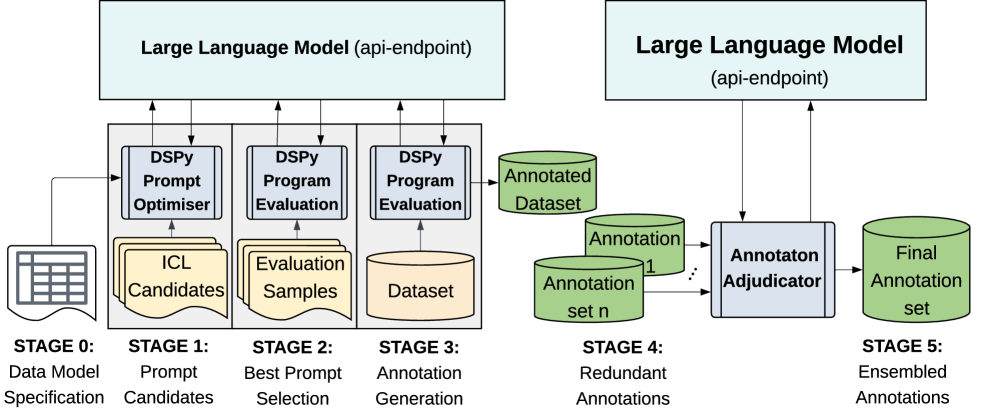
技术框架:该方法包含以下几个主要阶段:1) 数据准备:收集需要标注的文本数据。2) LLM标注:使用预先定义的提示,引导多个LLM独立地对文本进行标注,生成多个候选标注结果。3) 标注仲裁:使用另一个LLM作为仲裁器,对多个候选标注结果进行整合和修正,生成最终的标注结果。4) 评估:评估LLM标注结果的质量,例如通过计算标注者间一致性(Inter-Annotator Agreement)。
关键创新:1) 声明式标注流程:相比于传统的手动提示工程,该方法采用声明式的方式定义标注规则,降低了提示设计的复杂性,提高了标注的一致性和可复用性。2) LLM标注仲裁机制:提出了一种新颖的LLM仲裁方法,能够有效地整合和修正多个LLM的标注结果,提高标注质量。
关键设计:1) 提示设计:设计清晰、明确的提示,引导LLM识别文本中的情感元素,例如方面(aspect)、情感词(sentiment word)和情感极性(sentiment polarity)。2) 仲裁策略:设计合理的仲裁策略,例如基于多数投票、置信度加权等方法,选择或生成最终的标注结果。3) 评估指标:采用合适的评估指标,例如标注者间一致性(IAA),评估LLM标注结果的质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM作为自动标注器和仲裁器,在ASTE和ACOS任务上取得了显著的成果。不同LLM标注器之间实现了较高的标注者间一致性,表明该方法具有良好的稳定性和可靠性。该方法有效降低了人工标注的成本和工作量,为细粒度情感分析的研究和应用提供了新的途径。
🎯 应用场景
该研究成果可广泛应用于舆情监控、产品评论分析、客户服务等领域。通过自动生成高质量的细粒度情感标注数据,可以降低模型训练成本,加速相关应用的开发和部署。未来,该方法有望扩展到其他自然语言处理任务,例如命名实体识别、关系抽取等。
📄 摘要(原文)
Fine-grained opinion analysis of text provides a detailed understanding of expressed sentiments, including the addressed entity. Although this level of detail is sound, it requires considerable human effort and substantial cost to annotate opinions in datasets for training models, especially across diverse domains and real-world applications. We explore the feasibility of LLMs as automatic annotators for fine-grained opinion analysis, addressing the shortage of domain-specific labelled datasets. In this work, we use a declarative annotation pipeline. This approach reduces the variability of manual prompt engineering when using LLMs to identify fine-grained opinion spans in text. We also present a novel methodology for an LLM to adjudicate multiple labels and produce final annotations. After trialling the pipeline with models of different sizes for the Aspect Sentiment Triplet Extraction (ASTE) and Aspect-Category-Opinion-Sentiment (ACOS) analysis tasks, we show that LLMs can serve as automatic annotators and adjudicators, achieving high Inter-Annotator Agreement across individual LLM-based annotators. This reduces the cost and human effort needed to create these fine-grained opinion-annotated datasets.