Persuasion Tokens for Editing Factual Knowledge in LLMs
作者: Paul Youssef, Jörg Schlötterer, Christin Seifert
分类: cs.CL, cs.LG
发布日期: 2026-01-23
备注: Accepted at EACL Main 2026
💡 一句话要点
提出说服令牌(P-Tokens),实现LLM中高效的事实知识编辑,无需特定示例。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识编辑 上下文学习 说服令牌 模型微调
📋 核心要点
- 现有上下文知识编辑(IKE)依赖大量特定事实的演示,成本高且占用上下文窗口。
- 论文提出说服令牌(P-Tokens),通过训练特殊令牌模拟IKE效果,无需特定事实演示。
- 实验表明,P-Tokens在多个数据集和LLM上表现与IKE相当甚至更好,且对干扰因素鲁棒。
📝 摘要(中文)
上下文知识编辑(IKE)是一种有前景的技术,用于使用新信息更新大型语言模型(LLM)。然而,IKE依赖于冗长的、特定于事实的演示,这些演示的创建成本高昂,并且会消耗大量的上下文窗口空间。在本文中,我们引入了说服令牌(P-Tokens)——经过训练的特殊令牌,可以复制IKE演示的效果,从而实现高效的知识编辑,而无需特定于事实的演示。我们评估了两个编辑数据集和三个LLM上的P-Tokens,证明了其性能与IKE相当,甚至通常超过IKE。我们进一步发现,编辑性能对干扰因素具有鲁棒性,对相邻事实的负面影响很小,并且增加P-Tokens的数量可以提高性能。我们的工作解决了IKE的关键限制,并为编辑LLM提供了一种更实用和可扩展的替代方案。
🔬 方法详解
问题定义:现有上下文知识编辑(IKE)方法在更新LLM的事实知识时,需要提供大量特定于事实的演示示例。这些示例的构建成本很高,并且会占用LLM有限的上下文窗口空间,限制了IKE的实用性和可扩展性。因此,如何高效地更新LLM的知识,同时避免对大量示例的依赖,是一个亟待解决的问题。
核心思路:论文的核心思路是训练一组特殊的令牌,称为说服令牌(P-Tokens),这些令牌能够模拟IKE演示的效果,从而在不需要提供特定事实示例的情况下,实现对LLM知识的编辑。通过学习这些令牌的表示,模型可以仅凭这些令牌就能理解并执行知识更新,从而大大减少了对上下文窗口的需求。
技术框架:该方法主要包含两个阶段:首先,使用包含知识编辑任务的数据集训练P-Tokens。训练过程中,P-Tokens被添加到输入序列中,并与模型一起进行微调,以学习如何影响模型的输出,使其符合编辑后的知识。其次,在推理阶段,将训练好的P-Tokens添加到需要进行知识编辑的输入序列中,模型将根据这些令牌的指示,生成更新后的输出。
关键创新:该方法最重要的创新点在于引入了P-Tokens的概念,通过训练特殊令牌来模拟IKE演示的效果,从而实现了高效的知识编辑,而无需依赖大量特定事实的示例。这与传统的IKE方法形成了鲜明对比,后者需要为每个需要编辑的事实提供相应的演示示例。
关键设计:P-Tokens的数量是一个关键参数,论文发现增加P-Tokens的数量可以提高编辑性能。损失函数的设计目标是使模型在给定P-Tokens的情况下,能够生成符合编辑后知识的输出。具体的训练细节(如学习率、优化器等)未知,但推测使用了标准的Transformer训练方法。
🖼️ 关键图片

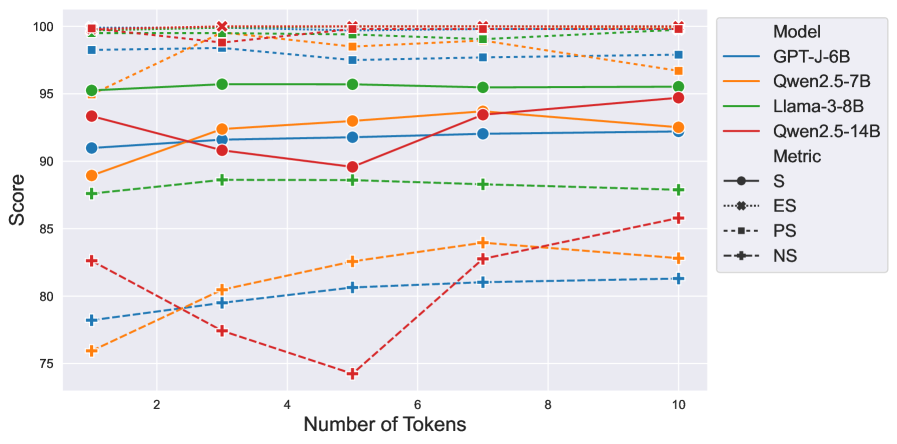
📊 实验亮点
实验结果表明,P-Tokens在知识编辑任务上表现出色,性能与IKE相当,甚至通常超过IKE。此外,P-Tokens对干扰因素具有鲁棒性,对相邻事实的负面影响很小。研究还发现,增加P-Tokens的数量可以提高编辑性能。这些结果表明,P-Tokens是一种有效且实用的知识编辑方法,具有广泛的应用前景。
🎯 应用场景
该研究成果可应用于各种需要快速更新知识的LLM应用场景,例如:问答系统、对话机器人、信息检索等。通过使用P-Tokens,可以高效地更新LLM的知识库,使其能够回答最新的问题,提供更准确的信息,并适应不断变化的世界。该方法还有助于减少LLM对大量训练数据的依赖,降低训练成本,并提高模型的泛化能力。
📄 摘要(原文)
In-context knowledge editing (IKE) is a promising technique for updating Large Language Models (LLMs) with new information. However, IKE relies on lengthy, fact-specific demonstrations which are costly to create and consume significant context window space. In this paper, we introduce persuasion tokens (P-Tokens) -- special tokens trained to replicate the effect of IKE demonstrations, enabling efficient knowledge editing without requiring fact-specific demonstrations. We evaluate P-Tokens across two editing datasets and three LLMs, demonstrating performance comparable to, and often exceeding, IKE. We further find that editing performance is robust to distractors with small negative effects to neighboring facts, and that increasing the number of P-Tokens improves performance. Our work addresses key limitations of IKE and provides a more practical and scalable alternative for editing LLMs.