Standardizing Longitudinal Radiology Report Evaluation via Large Language Model Annotation
作者: Xinyi Wang, Grazziela Figueredo, Ruizhe Li, Xin Chen
分类: cs.CL, cs.AI
发布日期: 2026-01-23
💡 一句话要点
提出基于大型语言模型的放射报告纵向信息自动标注流水线,提升报告评估标准化水平。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 放射报告 纵向信息 自动标注 自然语言处理
📋 核心要点
- 现有放射报告纵向信息标注方法依赖人工规则和词典,存在劳动密集、难以适应新领域等问题。
- 提出基于大型语言模型的自动标注流水线,无需大量人工干预即可捕获细微的语言模式和语义相似性。
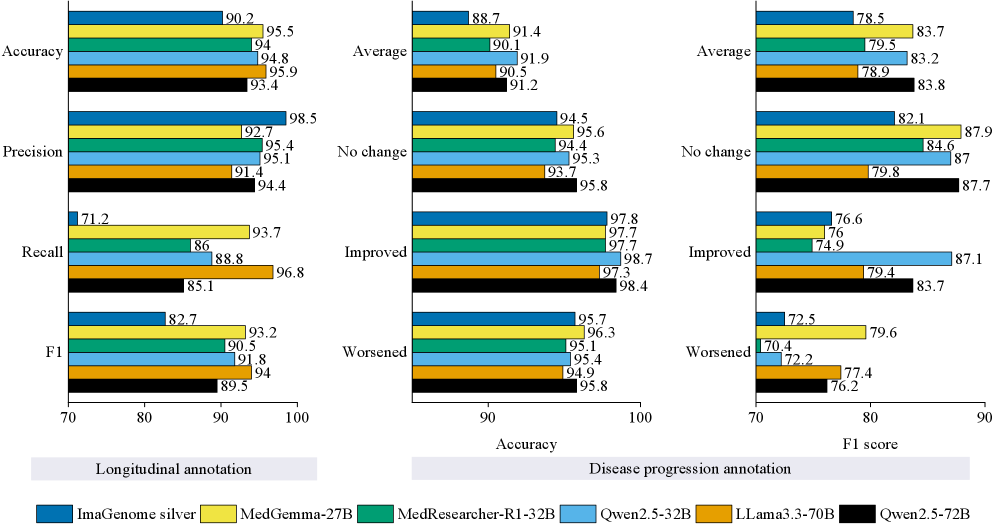
- 实验表明,该方法在纵向信息检测和疾病跟踪方面,F1分数分别提升了11.3%和5.3%。
📝 摘要(中文)
放射报告中的纵向信息是指随时间推移对多次检查结果的连续跟踪,这对于监测疾病进展和指导临床决策至关重要。许多最新的自动放射报告生成方法旨在捕获纵向信息,但验证其性能具有挑战性。目前缺乏合适的工具来一致地标注ground-truth和模型生成的文本中的时间变化,以进行有意义的比较。现有的标注方法通常是劳动密集型的,依赖于手动词典和规则。复杂的规则是闭源的、特定于领域的且难以适应,而过于简单的规则往往会遗漏重要的专业信息。大型语言模型(LLM)提供了一种有前景的标注替代方案,因为它们能够在没有大量人工干预的情况下捕获细微的语言模式和语义相似性。它们也能很好地适应新的环境。因此,在本研究中,我们提出了一种基于LLM的流水线来自动标注放射报告中的纵向信息。该流水线首先识别包含相关信息的句子,然后提取疾病的进展。我们使用500份手动标注的报告对五个主流LLM在这些任务上进行了评估和比较。考虑到效率和性能,随后选择Qwen2.5-32B,并用于标注来自公共MIMIC-CXR数据集的另外95,169份报告。我们使用Qwen2.5-32B标注的数据集为评估报告生成模型提供了一个标准化的基准。使用这个新的基准,我们评估了七个最先进的报告生成模型。我们的基于LLM的标注方法优于现有的标注解决方案,在纵向信息检测和疾病跟踪方面分别实现了11.3%和5.3%的F1分数提升。
🔬 方法详解
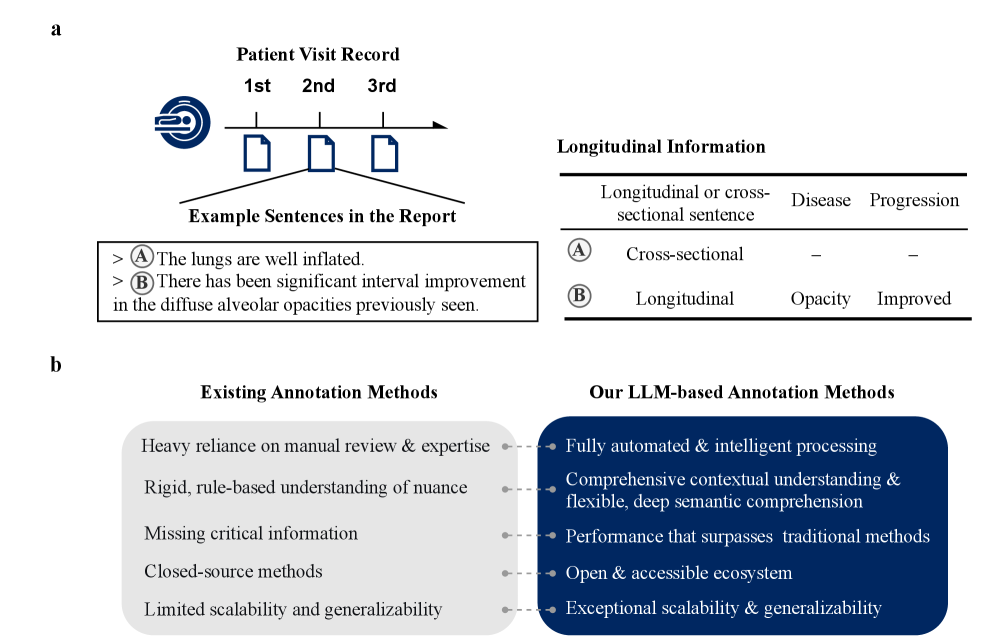
问题定义:论文旨在解决放射报告中纵向信息标注的标准化问题。现有方法主要依赖人工构建的词典和规则,存在以下痛点:一是标注过程耗时耗力;二是规则和词典的构建高度依赖领域专家知识,难以迁移到新的数据集或疾病类型;三是人工规则难以覆盖所有可能的语言表达,容易遗漏重要信息。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的语言理解和生成能力,自动识别和提取放射报告中的纵向信息。LLM能够学习到细微的语言模式和语义相似性,从而在无需大量人工干预的情况下完成标注任务。通过将标注过程自动化,可以显著提高效率并降低成本。
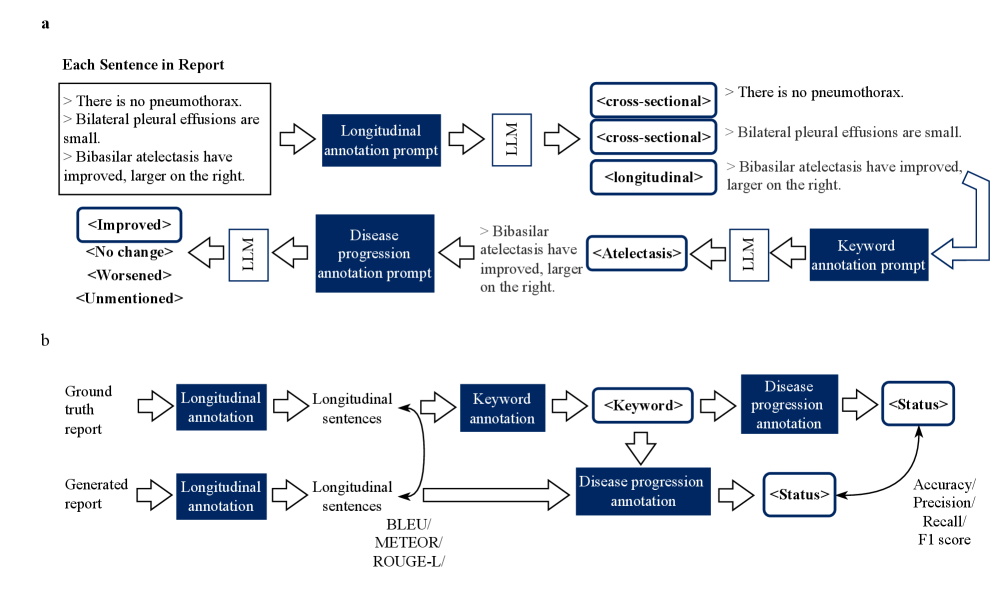
技术框架:该方法构建了一个基于LLM的自动标注流水线,主要包含两个阶段:1) 句子识别:利用LLM识别包含纵向信息的句子。2) 疾病进展提取:利用LLM提取句子中描述的疾病进展情况。该流水线首先对放射报告进行预处理,然后将句子输入到LLM中进行标注。最后,将标注结果进行整合,生成最终的标注结果。
关键创新:该方法最重要的创新点在于利用LLM自动标注放射报告中的纵向信息,从而避免了人工构建规则和词典的繁琐过程。与现有方法相比,该方法具有更高的效率、更强的泛化能力和更低的成本。此外,该方法还提供了一个标准化的基准数据集,用于评估报告生成模型的性能。
关键设计:论文中,作者比较了五个主流LLM(未知具体模型),最终选择了Qwen2.5-32B作为标注模型,因为它在效率和性能之间取得了较好的平衡。作者使用500份手动标注的报告对LLM进行了微调和评估。此外,作者还构建了一个包含95,169份报告的大规模标注数据集,用于评估报告生成模型的性能。具体的损失函数、网络结构等技术细节未在摘要中提及,属于未知信息。
🖼️ 关键图片
📊 实验亮点
该研究表明,基于LLM的标注方法在纵向信息检测和疾病跟踪方面优于现有方法,F1分数分别提升了11.3%和5.3%。使用Qwen2.5-32B标注了包含95,169份报告的大规模数据集,为报告生成模型的评估提供了一个标准化的基准。
🎯 应用场景
该研究成果可应用于医学影像报告的自动分析和理解,辅助医生进行疾病诊断和治疗方案制定。标准化的纵向信息标注数据集可用于训练和评估报告生成模型,提升报告的质量和准确性。此外,该方法还可推广到其他类型的医学文本标注任务中,具有广泛的应用前景。
📄 摘要(原文)
Longitudinal information in radiology reports refers to the sequential tracking of findings across multiple examinations over time, which is crucial for monitoring disease progression and guiding clinical decisions. Many recent automated radiology report generation methods are designed to capture longitudinal information; however, validating their performance is challenging. There is no proper tool to consistently label temporal changes in both ground-truth and model-generated texts for meaningful comparisons. Existing annotation methods are typically labor-intensive, relying on the use of manual lexicons and rules. Complex rules are closed-source, domain specific and hard to adapt, whereas overly simple ones tend to miss essential specialised information. Large language models (LLMs) offer a promising annotation alternative, as they are capable of capturing nuanced linguistic patterns and semantic similarities without extensive manual intervention. They also adapt well to new contexts. In this study, we therefore propose an LLM-based pipeline to automatically annotate longitudinal information in radiology reports. The pipeline first identifies sentences containing relevant information and then extracts the progression of diseases. We evaluate and compare five mainstream LLMs on these two tasks using 500 manually annotated reports. Considering both efficiency and performance, Qwen2.5-32B was subsequently selected and used to annotate another 95,169 reports from the public MIMIC-CXR dataset. Our Qwen2.5-32B-annotated dataset provided us with a standardized benchmark for evaluating report generation models. Using this new benchmark, we assessed seven state-of-the-art report generation models. Our LLM-based annotation method outperforms existing annotation solutions, achieving 11.3\% and 5.3\% higher F1-scores for longitudinal information detection and disease tracking, respectively.