Select or Project? Evaluating Lower-dimensional Vectors for LLM Training Data Explanations
作者: Lukas Hinterleitner, Loris Schoenegger, Benjamin Roth
分类: cs.CL
发布日期: 2026-01-23
备注: 8 pages
💡 一句话要点
提出基于架构信息的梯度选择方法,提升LLM训练数据解释的效率与准确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 可解释性 梯度分析 实例解释 模型架构
📋 核心要点
- 现有基于梯度的LLM可解释性方法面临梯度维度过高的问题,影响计算效率和解释质量。
- 论文提出一种基于模型架构信息的梯度组件选择方法,旨在降低梯度维度并保留关键信息。
- 实验表明,贪婪选择的组件子集在检索任务中优于完整梯度和随机投影,且计算效率更高。
📝 摘要(中文)
基于梯度的LLM实例解释方法受到模型梯度高维度的限制。为了使计算可行,实践中通常只使用模型参数的一个子集来估计影响,但该子集的选择往往是临时性的,缺乏系统评估。本文研究了两种创建低维表示的方法:选择一个小的、架构相关的模型组件子集,或者将完整梯度投影到低维空间。通过一个新颖的基准测试,我们证明了贪婪选择的组件子集比完整梯度或随机投影更有效地捕获了检索任务所需的训练数据影响信息。此外,该方法比随机投影更具计算效率,表明有针对性的组件选择是使大型模型的实例解释在计算上更可行的实用策略。
🔬 方法详解
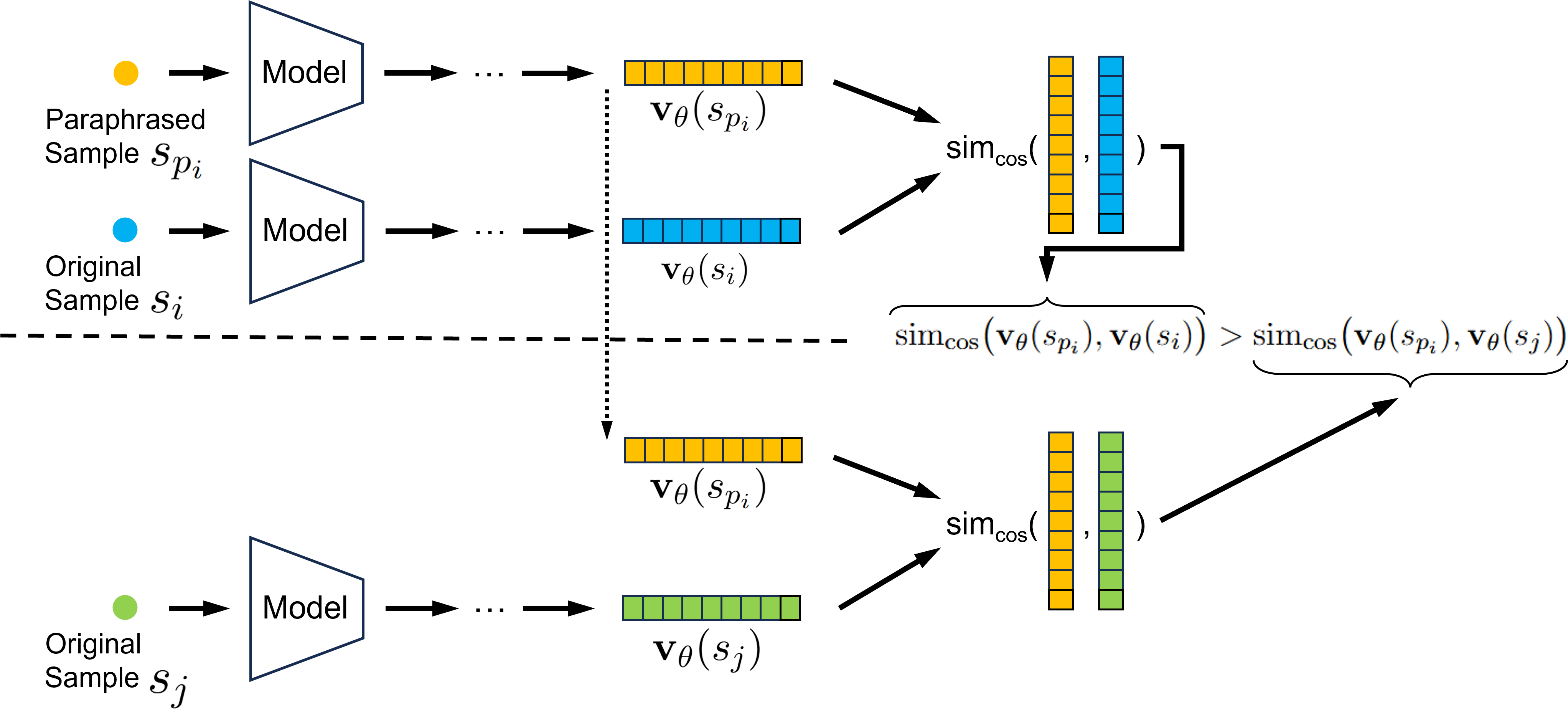
问题定义:现有基于梯度的LLM训练数据解释方法,由于模型梯度维度过高,导致计算量巨大,难以应用。常用的做法是选取模型参数的一个子集进行计算,但如何选择这个子集缺乏理论指导,通常是随意选择,影响了解释的准确性和可靠性。
核心思路:论文的核心思路是,并非所有模型参数对训练数据的影响都相同,因此可以通过选择对解释任务贡献最大的参数子集,来降低梯度维度,提高计算效率,同时保证解释的准确性。论文认为,模型架构信息可以指导参数子集的选择。
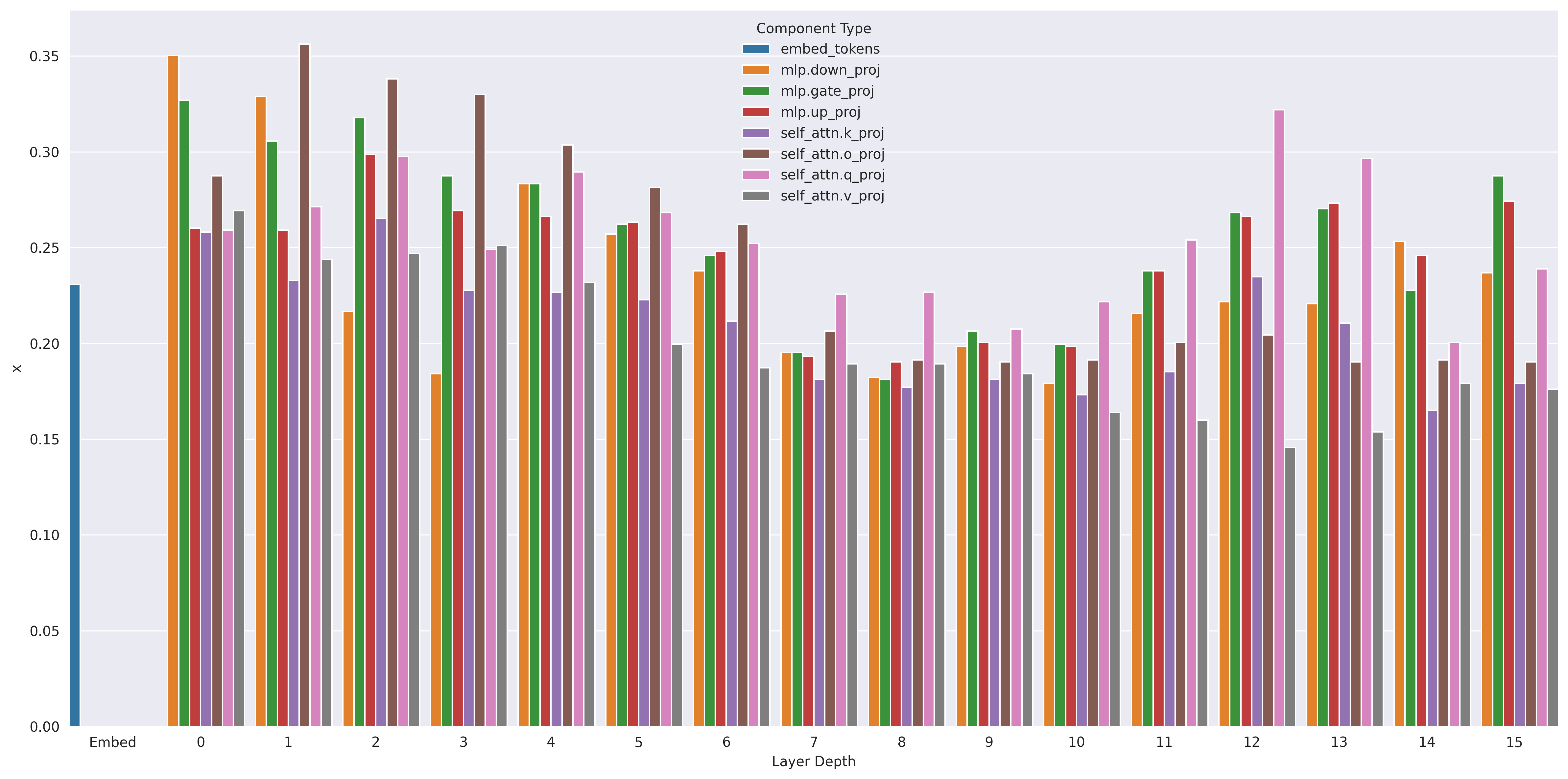
技术框架:论文提出了一种基于贪婪算法的组件选择框架。首先,定义一个评估指标,用于衡量参数子集对解释任务的贡献。然后,从空集开始,每次迭代选择一个能够最大程度提高评估指标的组件加入子集,直到达到预定的维度。该框架可以与不同的评估指标和模型架构相结合。
关键创新:论文的关键创新在于提出了利用模型架构信息来指导梯度组件选择的思想。与随机选择或使用完整梯度相比,该方法能够更有效地捕获训练数据的影响信息,同时降低计算复杂度。
关键设计:论文使用贪婪算法进行组件选择,评估指标的选择至关重要。论文设计了一个新颖的基准测试,用于评估不同参数子集对检索任务的贡献。具体的参数设置和损失函数取决于具体的LLM模型和解释任务。
🖼️ 关键图片

📊 实验亮点
实验结果表明,通过贪婪选择的组件子集,在检索任务中能够比完整梯度或随机投影更有效地捕获训练数据的影响信息。同时,该方法在计算效率上优于随机投影,证明了有针对性的组件选择是提高LLM实例解释计算可行性的有效策略。
🎯 应用场景
该研究成果可应用于提升大型语言模型的可解释性和可信度,例如,帮助用户理解模型为何给出特定回复,诊断模型训练数据中的偏差,以及优化模型的训练过程。此外,该方法还可以应用于其他深度学习模型的可解释性研究,具有广泛的应用前景。
📄 摘要(原文)
Gradient-based methods for instance-based explanation for large language models (LLMs) are hindered by the immense dimensionality of model gradients. In practice, influence estimation is restricted to a subset of model parameters to make computation tractable, but this subset is often chosen ad hoc and rarely justified by systematic evaluation. This paper investigates if it is better to create low-dimensional representations by selecting a small, architecturally informed subset of model components or by projecting the full gradients into a lower-dimensional space. Using a novel benchmark, we show that a greedily selected subset of components captures the information about training data influence needed for a retrieval task more effectively than either the full gradient or random projection. We further find that this approach is more computationally efficient than random projection, demonstrating that targeted component selection is a practical strategy for making instance-based explanations of large models more computationally feasible.