MultiLexNorm++: A Unified Benchmark and a Generative Model for Lexical Normalization for Asian Languages
作者: Weerayut Buaphet, Thanh-Nhi Nguyen, Risa Kondo, Tomoyuki Kajiwara, Yumin Kim, Jimin Lee, Hwanhee Lee, Holy Lovenia, Peerat Limkonchotiwat, Sarana Nutanong, Rob Van der Goot
分类: cs.CL
发布日期: 2026-01-23
💡 一句话要点
提出MultiLexNorm++基准和基于LLM的生成模型,用于亚洲语言词汇归一化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 词汇归一化 亚洲语言 大型语言模型 社交媒体文本 自然语言处理
📋 核心要点
- 社交媒体文本的非正式性对NLP模型构成挑战,词汇归一化是解决此问题的有效手段。
- 论文扩展了MultiLexNorm基准,纳入多种亚洲语言和文字,以更全面地评估词汇归一化模型。
- 提出基于大型语言模型的新架构,并在扩展后的基准上验证了其优越性和鲁棒性。
📝 摘要(中文)
社交媒体数据因其丰富的信息而备受自然语言处理(NLP)从业者的关注,但也给自动处理带来了挑战。由于语言使用更加非正式、自发,并遵循许多不同的社会方言,NLP模型的性能经常下降。解决这个问题的一个方法是在处理之前将数据转换为标准变体,这也称为词汇归一化。针对此任务,已经提出了各种各样的基准和模型。MultiLexNorm基准旨在统一这些工作,但它几乎完全由拉丁字母的印欧语系语言组成。因此,我们提出了MultiLexNorm的扩展,涵盖了来自不同语系的5种亚洲语言,使用4种不同的文字。我们表明,先前的最先进模型在新语言上的表现更差,并提出了一种基于大型语言模型(LLM)的新架构,该架构显示出更强大的性能。最后,我们分析了剩余的错误,揭示了该任务的未来方向。
🔬 方法详解
问题定义:论文旨在解决亚洲语言社交媒体文本的词汇归一化问题。现有方法,特别是之前在MultiLexNorm基准上表现良好的模型,在处理亚洲语言时性能显著下降。这主要是因为亚洲语言的特性(如不同的文字、语系和语言结构)与现有模型训练数据中的印欧语系语言差异较大,导致模型泛化能力不足。
核心思路:论文的核心思路是利用大型语言模型(LLMs)强大的语言理解和生成能力,构建一个更鲁棒的词汇归一化模型。LLMs在大量文本数据上进行预训练,能够学习到丰富的语言知识和上下文信息,从而更好地处理不同语言和文字的词汇变异。
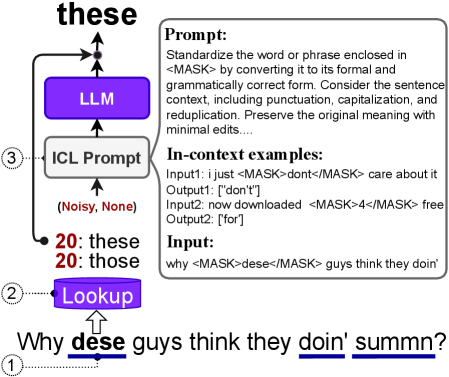
技术框架:该模型基于一个预训练的LLM,并针对词汇归一化任务进行微调。具体流程如下:1) 输入包含非规范化词汇的社交媒体文本;2) LLM对输入文本进行编码,提取上下文特征;3) 模型利用提取的特征生成规范化的词汇;4) 输出规范化后的文本。整体架构是一个序列到序列的生成模型。
关键创新:关键创新在于利用LLM的强大能力来处理亚洲语言的词汇归一化。与以往依赖手工特征或较小规模模型的做法不同,该方法能够自动学习语言的复杂模式,并更好地适应不同语言和文字的特点。此外,该模型在MultiLexNorm++基准上的表现优于之前的SOTA模型,证明了其有效性。
关键设计:论文中没有明确说明关键的参数设置、损失函数、网络结构等技术细节。但是,可以推断,该模型使用了标准的序列到序列的训练方法,例如交叉熵损失函数。具体的LLM选择和微调策略(例如学习率、batch size等)未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于LLM的新模型在MultiLexNorm++基准上显著优于之前的SOTA模型。具体性能提升数据未知,但论文强调了该模型在多种亚洲语言和文字上的鲁棒性。这表明LLM在处理复杂语言现象方面具有巨大潜力,能够有效解决传统方法难以应对的挑战。
🎯 应用场景
该研究成果可广泛应用于社交媒体文本分析、舆情监控、机器翻译等领域。通过词汇归一化,可以提高NLP模型在处理非正式文本时的准确性和鲁棒性,从而提升下游任务的性能。未来,该技术有望应用于更多低资源语言的文本处理,促进跨语言信息交流。
📄 摘要(原文)
Social media data has been of interest to Natural Language Processing (NLP) practitioners for over a decade, because of its richness in information, but also challenges for automatic processing. Since language use is more informal, spontaneous, and adheres to many different sociolects, the performance of NLP models often deteriorates. One solution to this problem is to transform data to a standard variant before processing it, which is also called lexical normalization. There has been a wide variety of benchmarks and models proposed for this task. The MultiLexNorm benchmark proposed to unify these efforts, but it consists almost solely of languages from the Indo-European language family in the Latin script. Hence, we propose an extension to MultiLexNorm, which covers 5 Asian languages from different language families in 4 different scripts. We show that the previous state-of-the-art model performs worse on the new languages and propose a new architecture based on Large Language Models (LLMs), which shows more robust performance. Finally, we analyze remaining errors, revealing future directions for this task.