AuroraEdge-V-2B: A Faster And Stronger Edge Visual Large Language Model
作者: Xiang Chen
分类: cs.CL
发布日期: 2026-01-23
💡 一句话要点
提出AuroraEdge-V-2B,一种快速、强大的边缘视觉大语言模型,加速工业应用部署。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 边缘计算 视觉大语言模型 模型压缩 知识蒸馏 多模态学习
📋 核心要点
- 现有VLLM在工业应用中面临挑战,包括特定领域性能不足、模型体积庞大、推理速度慢等问题,限制了其在边缘设备上的部署。
- AuroraEdge-V-2B通过模型压缩和融合技术,显著减少模型参数量和视觉token数量,从而提升推理速度,降低计算成本。
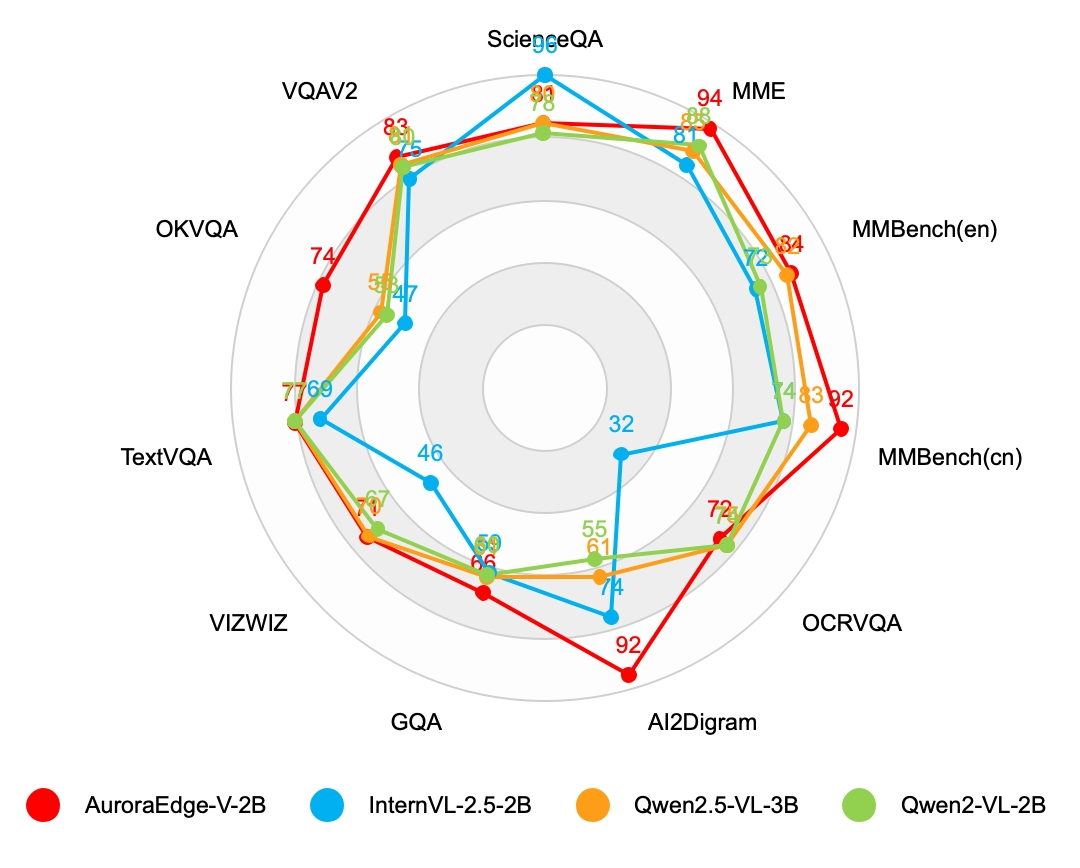
- 实验结果表明,AuroraEdge-V-2B在多个基准测试中优于同等参数规模的其他VLLM模型,验证了其性能优势。
📝 摘要(中文)
近年来,多模态技术的进步推动了视觉大语言模型(VLLM)在工业生产中的应用,许多深度学习模型(DLM)正逐渐被VLLM所取代。相较于DLM,VLLM在工业应用中具有更强的泛化能力和灵活性,能够快速处理未知的样本。然而,VLLM在特定领域性能不如定制DLM,参数量大,部署需要大量计算资源,且运行速度慢,难以实现实时响应。为了更好地在工业应用中利用VLLM,本文提出了AuroraEdge-V-2B,一种紧凑、鲁棒、高速的VLLM,专为边缘部署而设计。同时,提出了一种压缩融合方法来提高推理效率。AuroraEdge-V-2B具有易于部署、速度快、视觉token少、成本低、性能强等特点,在9个基准测试中取得了比同等参数量模型(如Qwen2-VL-2B、Qwen2.5-VL-3B、InternVL-2.5-2B)更高的分数。
🔬 方法详解
问题定义:现有视觉大语言模型(VLLM)在工业应用中面临着部署困难、推理速度慢以及计算成本高等问题。特别是在边缘设备上,由于计算资源有限,大型VLLM难以实现实时响应。此外,VLLM在特定领域的性能通常不如专门定制的深度学习模型(DLM)。
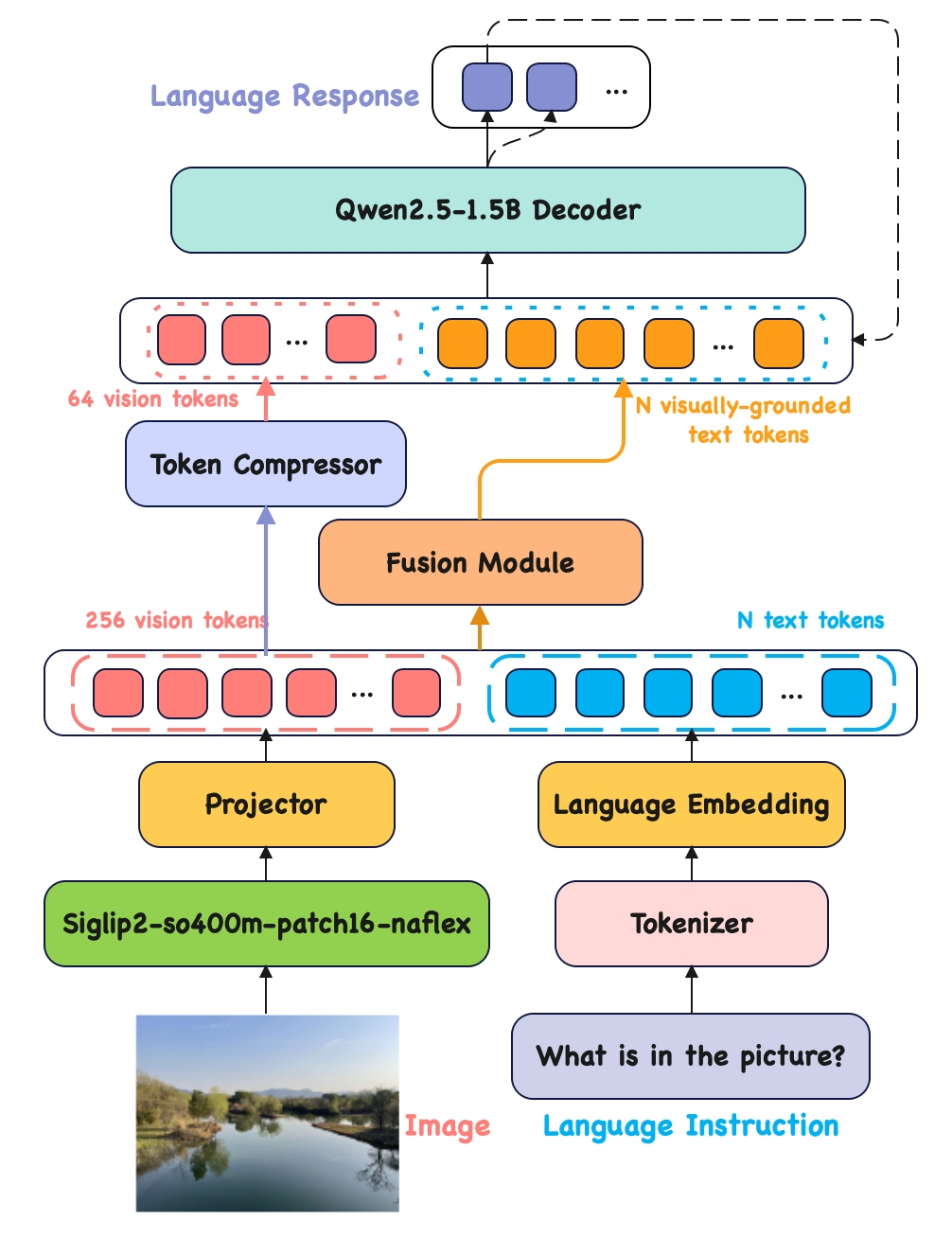
核心思路:AuroraEdge-V-2B的核心思路是设计一个参数量小、推理速度快、同时保持较高性能的VLLM,使其能够高效地部署在边缘设备上。通过减少视觉token的数量和采用压缩融合方法,降低计算复杂度,从而加速推理过程。
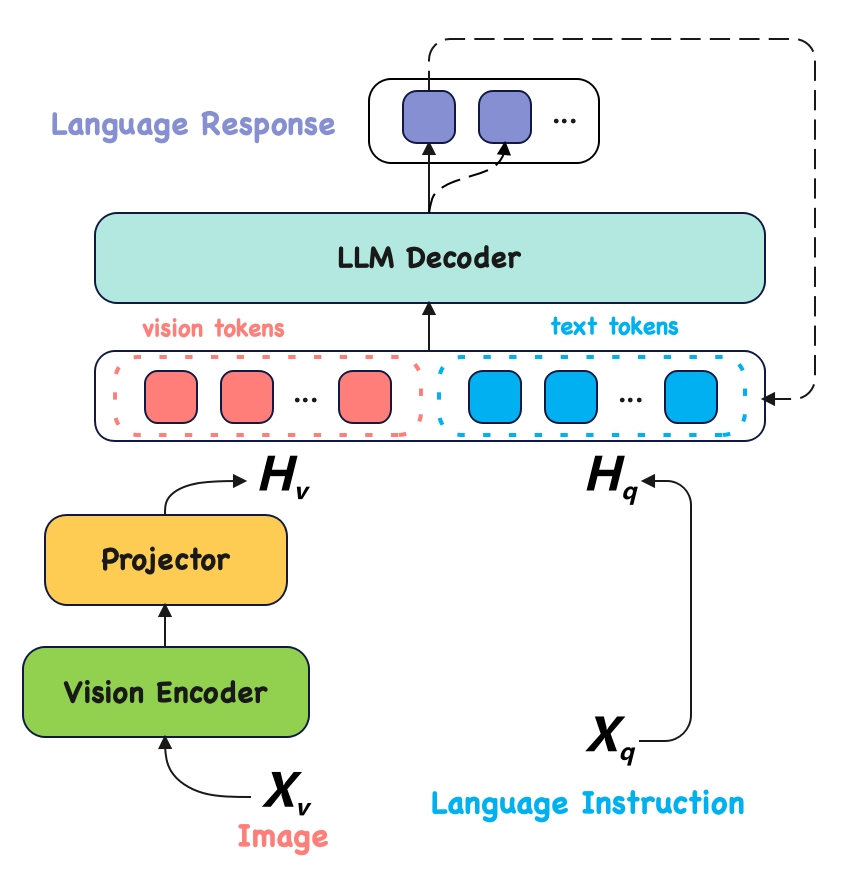
技术框架:AuroraEdge-V-2B的整体架构基于Transformer结构,包含视觉编码器和语言解码器两个主要模块。视觉编码器负责将输入图像转换为视觉特征,语言解码器则利用这些特征生成文本描述或回答相关问题。为了减少计算量,该模型采用了轻量级的视觉编码器和优化的注意力机制。
关键创新:AuroraEdge-V-2B的关键创新在于其压缩融合方法和减少视觉token数量的设计。压缩融合方法通过知识蒸馏和模型剪枝等技术,减小模型体积,提高推理速度。减少视觉token数量则直接降低了语言解码器的计算负担,从而进一步加速推理过程。
关键设计:在视觉编码器方面,采用了轻量级的卷积神经网络(CNN)或Transformer变体,以提取图像特征。在语言解码器方面,采用了优化的注意力机制,如多头注意力或局部注意力,以减少计算量。此外,还采用了量化和剪枝等技术,进一步压缩模型体积。损失函数方面,采用了交叉熵损失函数和知识蒸馏损失函数,以保证模型性能。
🖼️ 关键图片
📊 实验亮点
AuroraEdge-V-2B在9个基准测试中取得了优于同等参数量模型的性能,例如Qwen2-VL-2B、Qwen2.5-VL-3B和InternVL-2.5-2B。这表明该模型在保持较小体积的同时,具有强大的视觉理解和语言生成能力。通过减少视觉token数量和采用压缩融合方法,AuroraEdge-V-2B实现了更快的推理速度和更低的计算成本。
🎯 应用场景
AuroraEdge-V-2B适用于各种边缘计算场景,如智能制造、智能安防、自动驾驶等。在智能制造中,可用于产品缺陷检测和质量控制;在智能安防中,可用于实时监控和异常行为识别;在自动驾驶中,可用于环境感知和决策。该模型的小型化和高效性使其能够部署在资源受限的设备上,实现实时智能分析,具有广阔的应用前景。
📄 摘要(原文)
Recently, due to the advancement of multimodal technology, people are attempting to use visual large language models (VLLMs) in industrial production. Many deep learning models (DLMs) deployed in the production environment are gradually being replaced by VLLMs. Compared with DLMs, VLLMs have some advantages in industrial applications: (1) Their strong generalization ability enables them to perform well across a wide range of tasks. (2) They are flexible and can deal with unfamiliar samples through context learning quickly. However, VLLMs also have obvious drawbacks: (1) VLLMs do not perform as well as custom-developed DLMs in specific domains. (2) The number of parameters in VLLMs is generally quite large, and their deployment requires substantial computational resources. (3) VLLMs generally operate much slower than DLMs, making real-time response challenging to achieve. To better utilize VLLMs in industrial applications, we introduce AuroraEdge-V-2B in this work, a compact, robust, and high-speed VLLM designed for edge deployment. To make the model run faster, we also propose a compression-fusion method to improve inference efficiency. AuroraEdge-V-2B has the following notable features: (1) Easy deployment and faster: It has only 2B parameters and is highly suitable for edge deployment, offering better real-time performance. (2) Fewer visual tokens and cheaper: It significantly reduces the number of visual tokens in the decoding process, thereby reducing the floating-point operations by half during inference and making it cheaper to use. (3) Strong performance: It gets a higher score on 9 benchmarks than models with the same number of parameter (e.g., Qwen2-VL-2B, Qwen2.5-VL-3B, InternVL-2.5-2B).