Attention-MoA: Enhancing Mixture-of-Agents via Inter-Agent Semantic Attention and Deep Residual Synthesis
作者: Jianyu Wen, Yang Wei, Xiongxi Yu, Changxuan Xiao, Ke Zeng
分类: cs.CL, cs.AI
发布日期: 2026-01-23
💡 一句话要点
提出Attention-MoA,通过Agent间语义注意力机制增强混合Agent模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合Agent 多智能体协作 语义注意力 残差连接 自适应提前停止
📋 核心要点
- 现有MoA方法缺乏Agent间深度语义交互,限制了系统纠正幻觉和完善逻辑的能力。
- Attention-MoA通过Agent间语义注意力机制和层间残差模块,增强Agent间的协作和信息传递。
- 实验表明,Attention-MoA显著优于现有方法,甚至超越了大型专有模型如Claude-4.5-Sonnet和GPT-4.1。
📝 摘要(中文)
随着大型语言模型(LLM)的发展从参数扩展转向推理时协作,混合Agent(MoA)框架已成为一种通过分层多样化模型来利用集体智能的通用范例。虽然最近的MoA变体引入了动态路由和残差连接以提高效率,但这些方法通常无法促进Agent之间的深度语义交互,从而限制了系统主动纠正幻觉和完善逻辑的能力。本文介绍了一种新颖的基于MoA的框架Attention-MoA,该框架通过Agent间语义注意力重新定义了协作。通过具有自适应提前停止机制的层间残差模块进行补充,我们的架构减轻了深层中的信息退化,同时提高了计算效率。在AlpacaEval 2.0、MT-Bench和FLASK上的大量评估表明,Attention-MoA显著优于最先进的基线,在AlpacaEval 2.0上实现了91.15%的长度控制胜率,并在FLASK的12项能力中占据了10项的主导地位。值得注意的是,Attention-MoA使小型开源模型的集成能够胜过像Claude-4.5-Sonnet和GPT-4.1这样的大型专有模型,实现了8.83的MT-Bench分数和77.36%的AlpacaEval 2.0 LC胜率。
🔬 方法详解
问题定义:现有混合Agent(MoA)框架在利用多个LLM进行协作推理时,缺乏有效的Agent间深度语义交互机制。这导致系统难以主动纠正幻觉、完善逻辑,从而限制了整体性能的提升。现有方法如动态路由和残差连接虽然提高了效率,但未能充分挖掘Agent之间的语义关联。
核心思路:Attention-MoA的核心思路是通过引入Agent间语义注意力机制,使各个Agent能够关注其他Agent提供的关键信息,从而实现更深层次的协作。此外,采用层间残差模块,缓解深层网络中的信息退化问题,并利用自适应提前停止机制提高计算效率。这样设计的目的是为了让Agent能够更好地理解彼此的意图,并整合各自的优势,从而提升整体的推理能力。
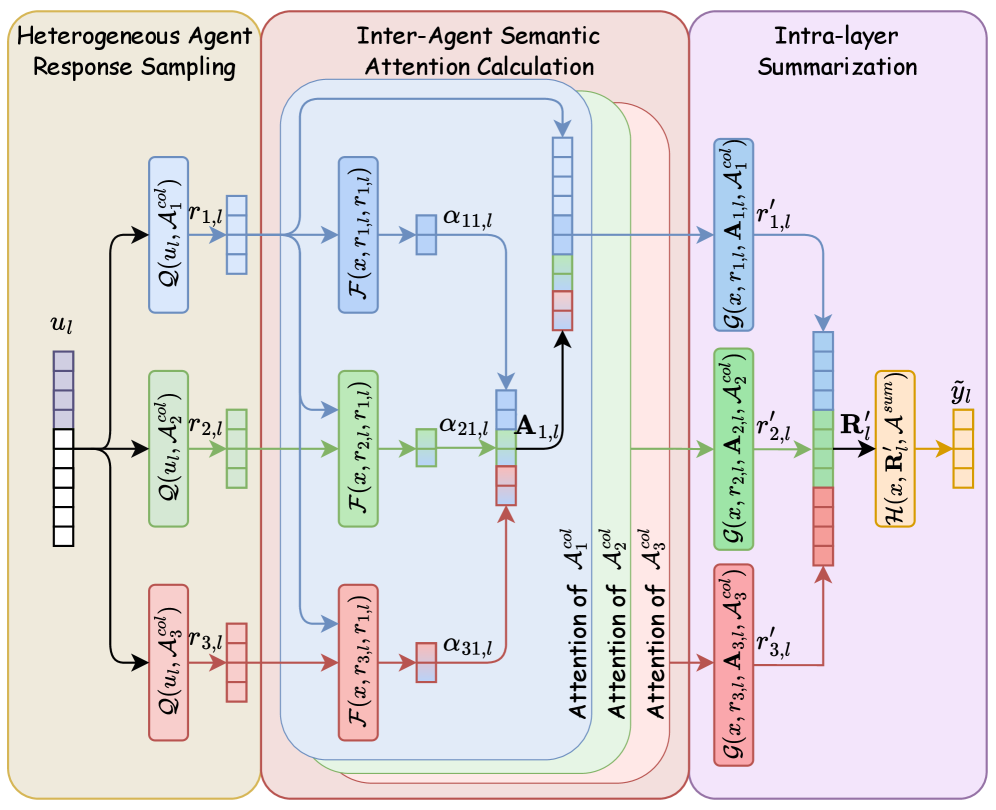
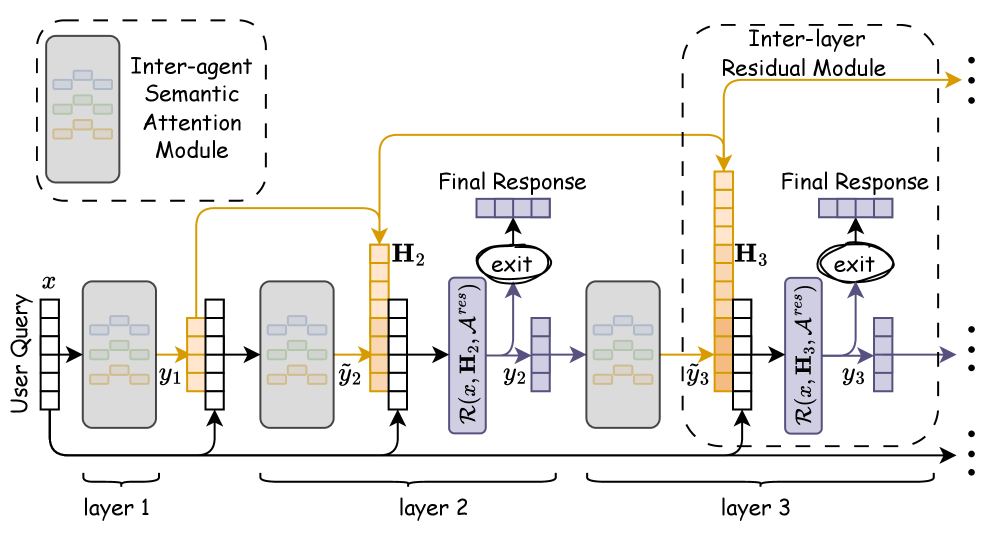
技术框架:Attention-MoA的整体架构包含多个Agent层,每一层都包含多个Agent。Agent之间通过Inter-agent Semantic Attention模块进行信息交互。该模块计算每个Agent对其他Agent输出的注意力权重,并根据权重对信息进行加权融合。此外,还包含一个Inter-layer Residual Module,用于将浅层的信息传递到深层,缓解信息退化。自适应提前停止机制则根据模型的收敛情况,动态地停止不必要的计算。
关键创新:Attention-MoA的关键创新在于Inter-agent Semantic Attention模块。与传统的注意力机制不同,该模块关注的是不同Agent之间的语义关联,而不是输入序列中的不同位置。这种设计使得Agent能够更好地理解彼此的意图,并整合各自的优势。此外,自适应提前停止机制也是一个创新点,它能够根据模型的收敛情况动态地停止计算,从而提高计算效率。
关键设计:Inter-agent Semantic Attention模块使用多头注意力机制,每个头关注不同的语义空间。注意力权重的计算基于Agent输出的Query、Key和Value向量。Inter-layer Residual Module采用残差连接,将浅层的输出直接加到深层的输入上。自适应提前停止机制基于验证集的性能,当性能不再提升时,停止计算。
🖼️ 关键图片
📊 实验亮点
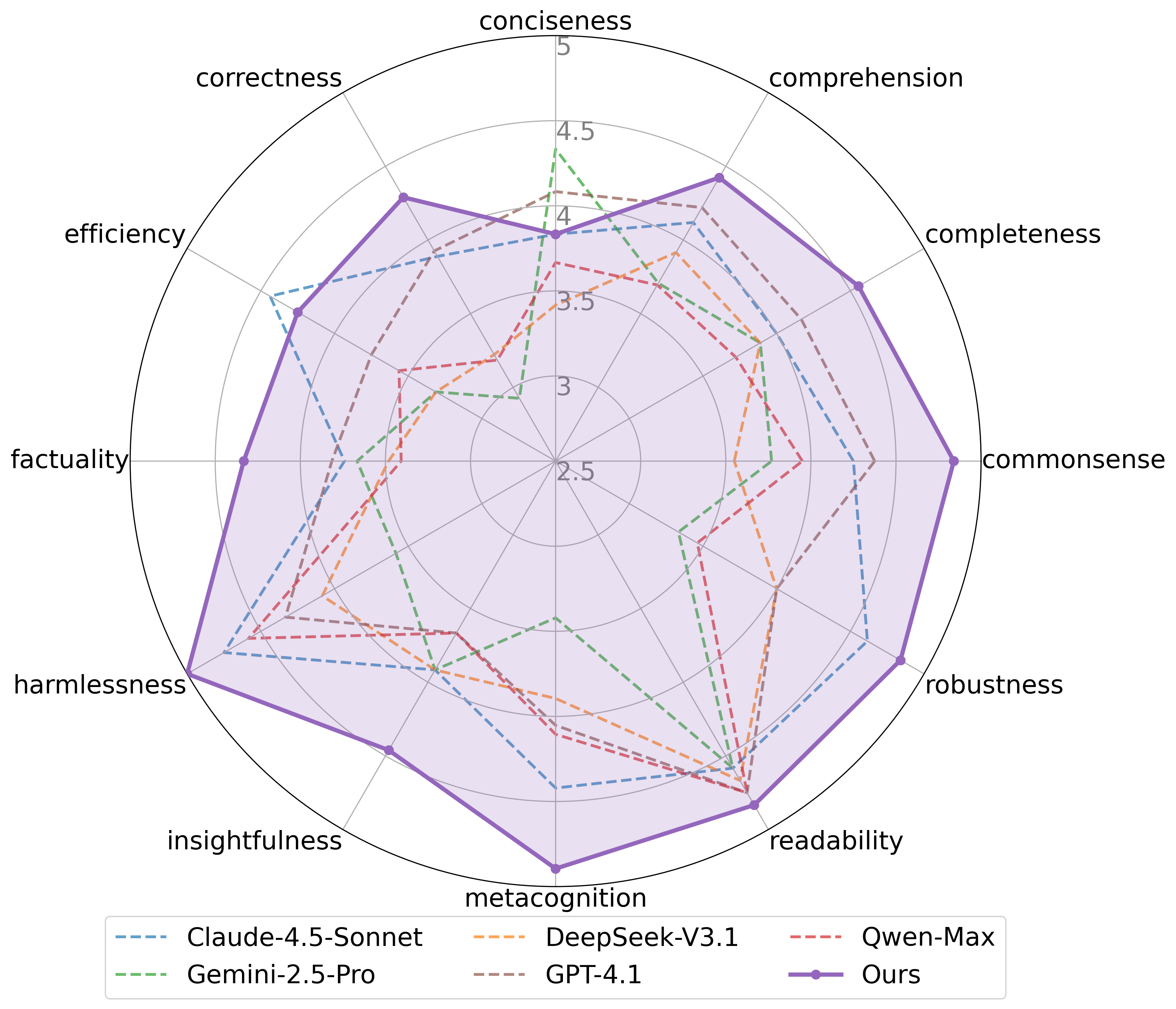
Attention-MoA在AlpacaEval 2.0上实现了91.15%的长度控制胜率,显著优于现有方法。在MT-Bench上取得了8.83的分数,超越了Claude-4.5-Sonnet和GPT-4.1等大型专有模型。在FLASK的12项能力中,Attention-MoA在10项中占据主导地位。这些实验结果表明,Attention-MoA在多个任务上都取得了显著的性能提升。
🎯 应用场景
Attention-MoA框架可应用于各种需要多智能体协作的场景,例如智能客服、自动驾驶、金融分析等。通过整合多个模型的优势,可以构建更强大、更可靠的智能系统。该研究的实际价值在于提升了多智能体系统的性能和效率,并为未来的研究提供了新的思路。
📄 摘要(原文)
As the development of Large Language Models (LLMs) shifts from parameter scaling to inference-time collaboration, the Mixture-of-Agents (MoA) framework has emerged as a general paradigm to harness collective intelligence by layering diverse models. While recent MoA variants have introduced dynamic routing and residual connections to improve efficiency, these methods often fail to facilitate deep semantic interaction between agents, limiting the system's ability to actively correct hallucinations and refine logic. In this paper, we introduce Attention-MoA, a novel MoA-based framework that redefines collaboration through Inter-agent Semantic Attention. Complemented by an Inter-layer Residual Module with Adaptive Early Stopping Mechanism, our architecture mitigates information degradation in deep layers while improving computational efficiency. Extensive evaluations across AlpacaEval 2.0, MT-Bench, and FLASK demonstrate that Attention-MoA significantly outperforms state-of-the-art baselines, achieving a 91.15% Length-Controlled Win Rate on AlpacaEval 2.0 and dominating in 10 out of 12 capabilities on FLASK. Notably, Attention-MoA enables an ensemble of small open-source models to outperform massive proprietary models like Claude-4.5-Sonnet and GPT-4.1, achieving an MT-Bench score of 8.83 and an AlpacaEval 2.0 LC Win Rate of 77.36%.