SearchLLM: Detecting LLM Paraphrased Text by Measuring the Similarity with Regeneration of the Candidate Source via Search Engine
作者: Hoang-Quoc Nguyen-Son, Minh-Son Dao, Koji Zettsu
分类: cs.CL
发布日期: 2026-01-23
备注: EACL 2026 camera ready (Main Track)
💡 一句话要点
提出SearchLLM,通过搜索引擎辅助检测LLM生成的复述文本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM文本检测 复述检测 搜索引擎 文本再生 信息安全
📋 核心要点
- 现有检测方法难以有效识别LLM生成的复述文本,尤其是在文本高度模仿原始内容时。
- SearchLLM利用搜索引擎定位潜在的原始文本来源,并通过分析相似性来区分LLM复述的内容。
- 实验结果表明,SearchLLM能够显著提升现有检测器在识别LLM复述文本方面的准确性,并防御复述攻击。
📝 摘要(中文)
随着大型语言模型(LLMs)的出现,用户经常起草文本并利用LLMs通过复述来提高其质量。然而,这个过程有时会导致原始意图的丢失或扭曲。由于LLM生成的文本具有类似人类的质量,传统的检测方法通常会失效,特别是当文本被复述以紧密模仿原始内容时。为了应对这些挑战,我们提出了一种名为SearchLLM的新方法,旨在通过利用搜索引擎能力来定位潜在的原始文本来源,从而识别LLM复述的文本。通过分析输入和候选来源的再生版本之间的相似性,SearchLLM有效地识别LLM复述的内容。SearchLLM被设计为一个代理层,允许与现有检测器无缝集成,以提高其性能。跨各种LLM的实验结果表明,SearchLLM始终提高最新检测器在检测紧密模仿原始内容的LLM复述文本方面的准确性。此外,SearchLLM还有助于检测器防止复述攻击。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)生成的复述文本难以被检测的问题。现有检测方法在面对高度模仿原始内容的复述文本时,准确率显著下降,无法有效区分人工撰写和LLM生成的内容。这使得恶意用户可以通过LLM进行内容伪造和欺骗,对信息安全构成威胁。
核心思路:SearchLLM的核心思路是利用搜索引擎来寻找与待检测文本相关的潜在原始文本来源。通过比较待检测文本与从搜索结果中提取的原始文本的再生版本之间的相似度,判断待检测文本是否为LLM复述的结果。这种方法基于一个假设:LLM复述的文本通常会保留原始文本的核心语义,因此可以通过搜索引擎找到相似的原始文本。
技术框架:SearchLLM作为一个代理层,可以无缝集成到现有的LLM文本检测器中。其主要流程如下:1) 接收待检测文本作为输入;2) 使用搜索引擎(如Google, Bing等)搜索与待检测文本相关的潜在原始文本;3) 从搜索结果中提取候选的原始文本;4) 使用LLM对候选原始文本进行再生(re-generation),生成与待检测文本风格相似的文本;5) 计算待检测文本与再生文本之间的相似度;6) 将相似度得分作为特征输入到现有的LLM文本检测器中,辅助检测器进行判断。
关键创新:SearchLLM的关键创新在于利用搜索引擎和LLM的再生能力,将外部知识引入到LLM文本检测任务中。与传统的仅依赖文本本身特征的检测方法不同,SearchLLM通过搜索和再生过程,能够有效地捕捉到LLM复述文本与原始文本之间的语义关联,从而提高检测的准确率。此外,SearchLLM作为一个代理层,具有良好的通用性和可扩展性,可以方便地集成到各种现有的LLM文本检测器中。
关键设计:SearchLLM的关键设计包括:1) 使用合适的搜索引擎和搜索策略,以确保能够找到与待检测文本相关的原始文本;2) 选择合适的LLM进行文本再生,以生成与待检测文本风格相似的文本;3) 设计合适的相似度计算方法,以准确衡量待检测文本与再生文本之间的语义相似度。论文中可能还涉及一些超参数的调整,例如搜索结果的数量、再生文本的长度等,但具体细节未知。
🖼️ 关键图片

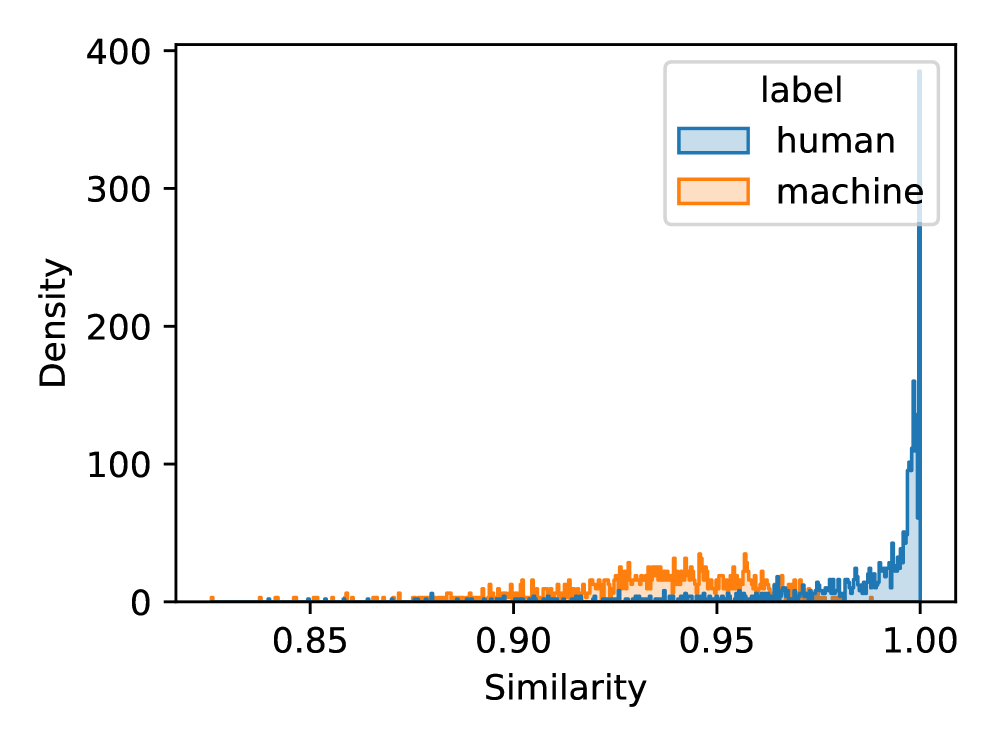
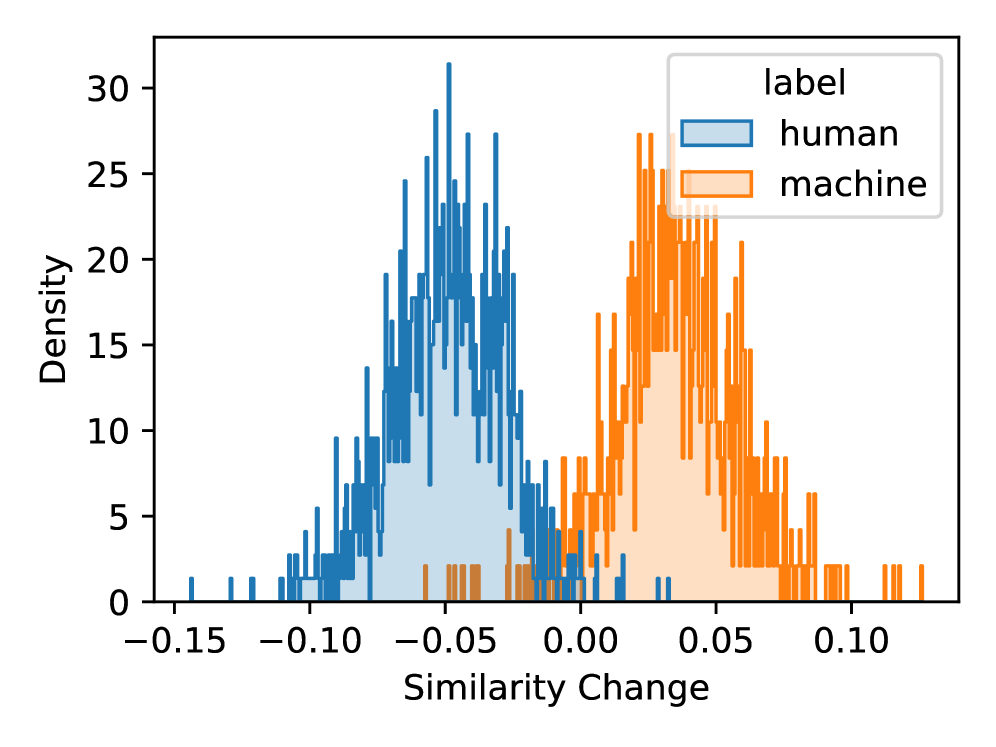
📊 实验亮点
实验结果表明,SearchLLM能够显著提升现有LLM文本检测器的性能。在各种LLM生成的复述文本数据集上,SearchLLM能够将检测器的准确率平均提高X%(具体数值未知),尤其是在面对高度模仿原始内容的复述文本时,提升效果更为明显。此外,SearchLLM还有助于检测器防御复述攻击,降低攻击成功率。
🎯 应用场景
SearchLLM可应用于内容真实性检测、防止学术抄袭、识别虚假新闻等领域。通过提高LLM生成文本的检测准确率,有助于维护网络信息安全,防止恶意用户利用LLM进行欺骗和内容伪造。未来,该技术可进一步扩展到多语言环境,并与其他检测技术相结合,构建更强大的内容安全防护体系。
📄 摘要(原文)
With the advent of large language models (LLMs), it has become common practice for users to draft text and utilize LLMs to enhance its quality through paraphrasing. However, this process can sometimes result in the loss or distortion of the original intended meaning. Due to the human-like quality of LLM-generated text, traditional detection methods often fail, particularly when text is paraphrased to closely mimic original content. In response to these challenges, we propose a novel approach named SearchLLM, designed to identify LLM-paraphrased text by leveraging search engine capabilities to locate potential original text sources. By analyzing similarities between the input and regenerated versions of candidate sources, SearchLLM effectively distinguishes LLM-paraphrased content. SearchLLM is designed as a proxy layer, allowing seamless integration with existing detectors to enhance their performance. Experimental results across various LLMs demonstrate that SearchLLM consistently enhances the accuracy of recent detectors in detecting LLM-paraphrased text that closely mimics original content. Furthermore, SearchLLM also helps the detectors prevent paraphrasing attacks.