Timely Machine: Awareness of Time Makes Test-Time Scaling Agentic
作者: Yichuan Ma, Linyang Li, Yongkang chen, Peiji Li, Xiaozhe Li, Qipeng Guo, Dahua Lin, Kai Chen
分类: cs.CL, cs.AI
发布日期: 2026-01-23
备注: Under Review
💡 一句话要点
提出Timely Machine,通过时间感知的测试时缩放提升Agent能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agent模型 测试时缩放 时间感知 强化学习 工具调用
📋 核心要点
- 现有Agent模型在测试时缩放中,未能有效利用时间预算,导致性能受限。
- Timely Machine 核心思想是让模型感知实际运行时间,并根据时间预算动态调整推理策略。
- Timely-RL 通过强化学习增强模型的时间规划能力,在 Timely-Eval 基准测试中取得显著提升。
📝 摘要(中文)
随着大型语言模型(LLMs)越来越多地处理复杂的推理任务,测试时缩放对于增强其能力至关重要。然而,在具有频繁工具调用的Agent场景中,传统的基于生成长度的定义失效:工具延迟将推理时间与生成长度解耦。我们提出了Timely Machine,将测试时间重新定义为实际运行时间,模型根据时间预算动态调整策略。我们引入了Timely-Eval,一个涵盖高频工具调用、低频工具调用和时间约束推理的基准。通过改变工具延迟,我们发现较小的模型通过更多交互和快速反馈表现出色,而较大的模型通过卓越的交互质量在较高延迟设置中占据主导地位。此外,现有模型无法使推理适应时间预算。我们提出了Timely-RL来解决这一差距。在冷启动监督微调后,我们使用强化学习来增强时间规划。Timely-RL提高了时间预算感知能力,并始终提高Timely-Eval的性能。我们希望我们的工作为Agent时代的测试时缩放提供一个新的视角。
🔬 方法详解
问题定义:现有Agent模型在测试时缩放中,主要依赖生成长度来衡量推理过程,忽略了工具调用带来的延迟。这导致模型无法有效利用时间预算,尤其是在工具调用频率高或延迟不稳定的情况下,模型性能会显著下降。现有方法缺乏对时间的感知和动态调整能力,无法适应不同时间约束下的推理需求。
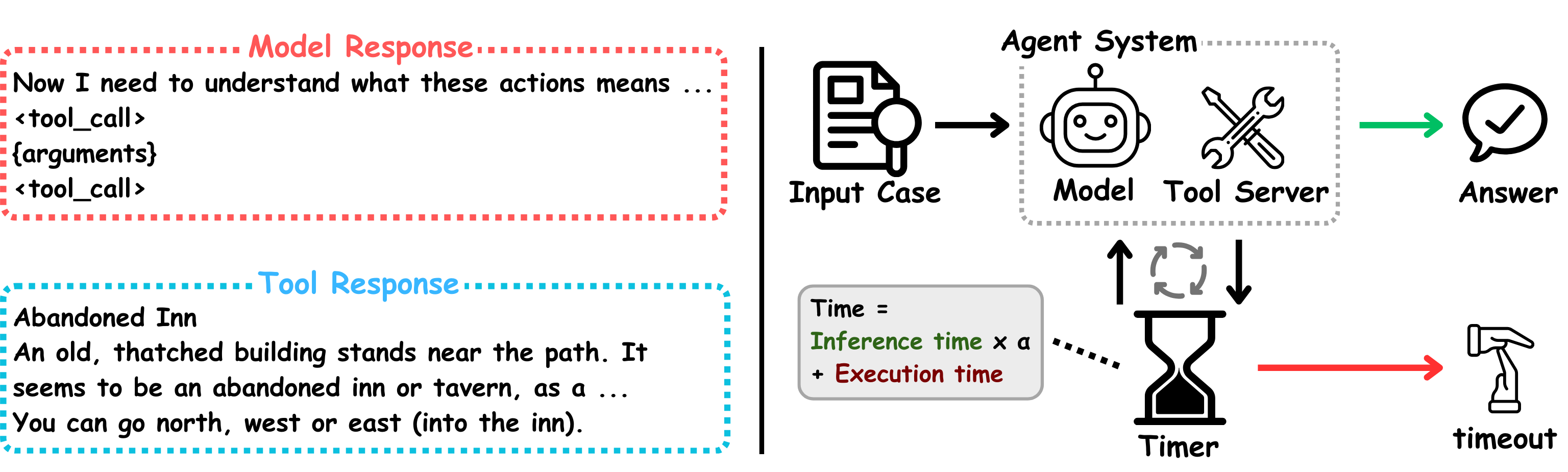
核心思路:Timely Machine 的核心思路是将测试时间重新定义为实际运行时间(wall-clock time),并让模型具备时间感知能力。模型根据剩余时间预算动态调整推理策略,例如,在时间充裕时进行更深入的思考和更复杂的工具调用,而在时间紧张时则采取更快速的决策方式。这种时间感知的策略调整能够使模型更好地适应不同的Agent场景,提高整体性能。
技术框架:Timely Machine 的整体框架包含以下几个主要组成部分:首先,使用监督微调(SFT)对模型进行冷启动,使其具备初步的Agent能力。然后,引入 Timely-Eval 基准测试,用于评估模型在不同时间约束下的性能。最后,使用强化学习(RL)对模型进行训练,使其能够根据时间预算动态调整推理策略。Timely-RL 算法是该框架的核心,它通过奖励函数来引导模型学习如何在有限的时间内最大化任务完成度。
关键创新:该论文的关键创新在于提出了时间感知的测试时缩放方法。与传统的基于生成长度的缩放方法不同,Timely Machine 能够根据实际运行时间和剩余时间预算动态调整推理策略。这种时间感知能力使得模型能够更好地适应不同的Agent场景,提高整体性能。此外,Timely-Eval 基准测试的引入为评估时间约束下的Agent性能提供了一个新的平台。
关键设计:Timely-RL 算法的关键设计包括:奖励函数的设计,奖励函数综合考虑了任务完成度、工具调用次数和时间消耗等因素,以引导模型学习如何在有限的时间内最大化任务完成度。强化学习算法的选择,论文采用了 Policy Gradient 方法,并通过精心设计的网络结构来提高训练效率和稳定性。时间预算的动态调整,模型根据剩余时间预算动态调整推理策略,例如,在时间充裕时进行更深入的思考和更复杂的工具调用,而在时间紧张时则采取更快速的决策方式。
🖼️ 关键图片
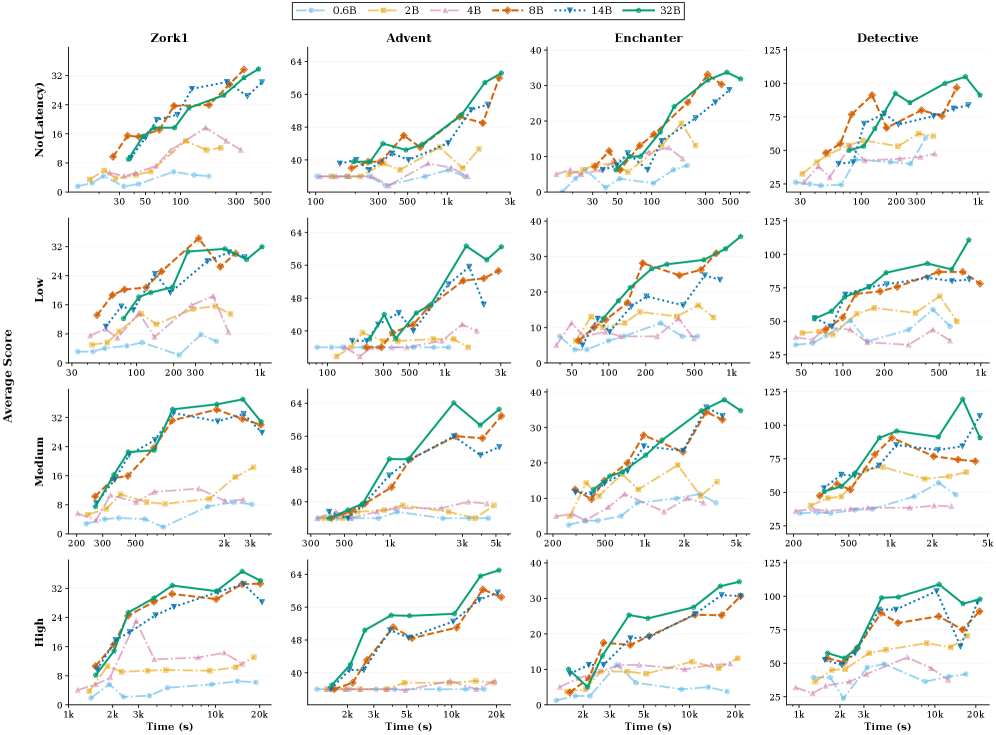

📊 实验亮点
实验结果表明,Timely-RL 能够显著提高模型在 Timely-Eval 基准测试中的性能。在不同工具延迟设置下,Timely-RL 均取得了优于现有模型的表现。例如,在高频工具调用场景中,Timely-RL 能够将任务完成度提高 10% 以上。此外,实验还表明,较小的模型在快速反馈场景中表现出色,而较大的模型在较高延迟场景中占据主导地位,这验证了时间感知测试时缩放的有效性。
🎯 应用场景
Timely Machine 的应用场景广泛,包括智能助手、自动化客服、机器人控制等。在这些场景中,Agent需要在有限的时间内完成复杂的任务,例如回答用户问题、解决技术问题、执行物理操作等。通过时间感知的测试时缩放,Timely Machine 能够使Agent更好地适应不同的时间约束,提高任务完成度和用户满意度。未来,该技术有望应用于更复杂的Agent系统中,例如自动驾驶、智能制造等。
📄 摘要(原文)
As large language models (LLMs) increasingly tackle complex reasoning tasks, test-time scaling has become critical for enhancing capabilities. However, in agentic scenarios with frequent tool calls, the traditional generation-length-based definition breaks down: tool latency decouples inference time from generation length. We propose Timely Machine, redefining test-time as wall-clock time, where models dynamically adjust strategies based on time budgets. We introduce Timely-Eval, a benchmark spanning high-frequency tool calls, low-frequency tool calls, and time-constrained reasoning. By varying tool latency, we find smaller models excel with fast feedback through more interactions, while larger models dominate high-latency settings via superior interaction quality. Moreover, existing models fail to adapt reasoning to time budgets. We propose Timely-RL to address this gap. After cold-start supervised fine-tuning, we use reinforcement learning to enhance temporal planning. Timely-RL improves time budget awareness and consistently boosts performance across Timely-Eval. We hope our work offers a new perspective on test-time scaling for the agentic era.