TL-GRPO: Turn-Level RL for Reasoning-Guided Iterative Optimization
作者: Peiji Li, Linyang Li, Handa Sun, Wenjin Mai, Yongkang Chen, Xiaozhe Li, Yue Shen, Yichuan Ma, Yiliu Sun, Jiaxi Cao, Zhishu He, Bo Wang, Xiaoqing Zheng, Zhaori Bi, Xipeng Qiu, Qipeng Guo, Kai Chen, Dahua Lin
分类: cs.CL
发布日期: 2026-01-23
备注: Work in progress
💡 一句话要点
提出Turn-Level GRPO算法,用于解决迭代优化任务中turn级别的精细化优化问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 迭代优化 组采样 模拟电路尺寸调整 大型语言模型
📋 核心要点
- 现有基于GRPO的强化学习方法在迭代优化任务中无法进行turn级别的精细化优化,黑盒优化方法又缺乏先验知识和推理能力。
- 提出Turn-Level GRPO算法,通过turn级别的组采样实现精细化优化,从而更好地适应迭代优化任务的特性。
- 在模拟电路尺寸调整(ACS)任务上的实验表明,TL-GRPO优于标准GRPO和贝叶斯优化方法,并在相同模拟预算下实现了最先进的性能。
📝 摘要(中文)
大型语言模型通过工具集成在复杂任务中展现了强大的推理能力,这通常被建模为马尔可夫决策过程,并使用轨迹级别的强化学习算法(如GRPO)进行优化。然而,一类常见的推理任务——迭代优化,提出了独特的挑战:智能体在不同turn中与相同的底层环境状态交互,并且轨迹的价值由最佳turn级别的奖励决定,而不是累积回报。现有的基于GRPO的方法无法在此类设置中执行精细的turn级别优化,而黑盒优化方法则丢弃了先验知识和推理能力。为了解决这个差距,我们提出了Turn-Level GRPO(TL-GRPO),一种轻量级的强化学习算法,它执行turn级别的组采样以进行精细化优化。我们在模拟电路尺寸调整(ACS)上评估了TL-GRPO,这是一个具有挑战性的科学优化任务,需要多次模拟和领域专业知识。结果表明,TL-GRPO在各种规范下优于标准GRPO和贝叶斯优化方法。此外,我们使用TL-GRPO训练的30B模型在相同的模拟预算下实现了ACS任务的最先进性能,展示了强大的泛化能力和实用性。
🔬 方法详解
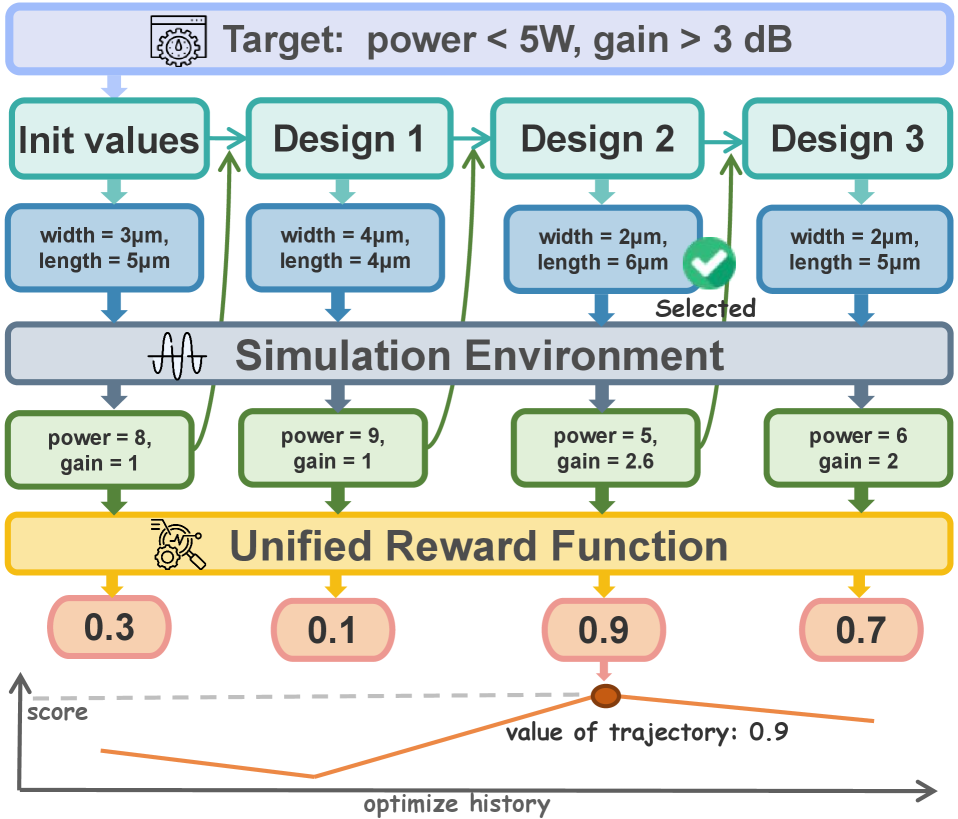
问题定义:论文旨在解决迭代优化任务中,现有强化学习方法无法进行turn级别精细化优化的问题。在诸如模拟电路尺寸调整等任务中,智能体需要在每个turn与相同的环境状态交互,轨迹的价值取决于最佳turn的奖励,而非累积奖励。传统的GRPO等轨迹级别优化方法无法有效处理这种情况,而黑盒优化方法则忽略了先验知识和推理能力。
核心思路:TL-GRPO的核心思路是进行turn级别的组采样,从而实现对每个turn的精细化优化。通过关注每个turn的性能,算法能够更好地适应迭代优化任务的特性,并找到最佳的turn策略。这种方法允许算法在每个迭代步骤中更有效地利用信息,并避免了对整个轨迹进行平均,从而提高了优化效率。
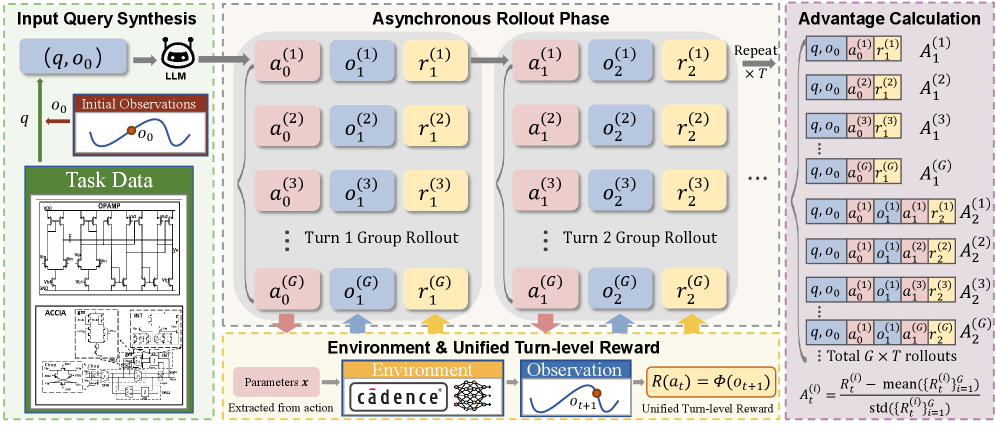
技术框架:TL-GRPO的整体框架基于强化学习,特别是GRPO算法。它主要包含以下几个阶段:1) 智能体与环境交互,在每个turn生成动作;2) 对每个turn的奖励进行评估;3) 使用turn级别的组采样方法选择优秀的turn;4) 使用选择的turn更新策略。该框架的关键在于turn级别的组采样,它允许算法专注于优化每个turn的策略,而不是整个轨迹。
关键创新:TL-GRPO最重要的技术创新点在于其turn级别的组采样方法。与传统的轨迹级别采样不同,TL-GRPO对每个turn进行独立评估和选择,从而实现了更精细的优化。这种方法能够更好地适应迭代优化任务的特性,并避免了对整个轨迹进行平均,从而提高了优化效率。
关键设计:TL-GRPO的关键设计包括:1) turn级别的奖励函数,用于评估每个turn的性能;2) 组采样策略,用于选择优秀的turn;3) 策略更新方法,用于根据选择的turn更新策略。具体的参数设置和网络结构取决于具体的应用场景,但核心思想是关注每个turn的性能,并使用组采样方法进行优化。
🖼️ 关键图片
📊 实验亮点
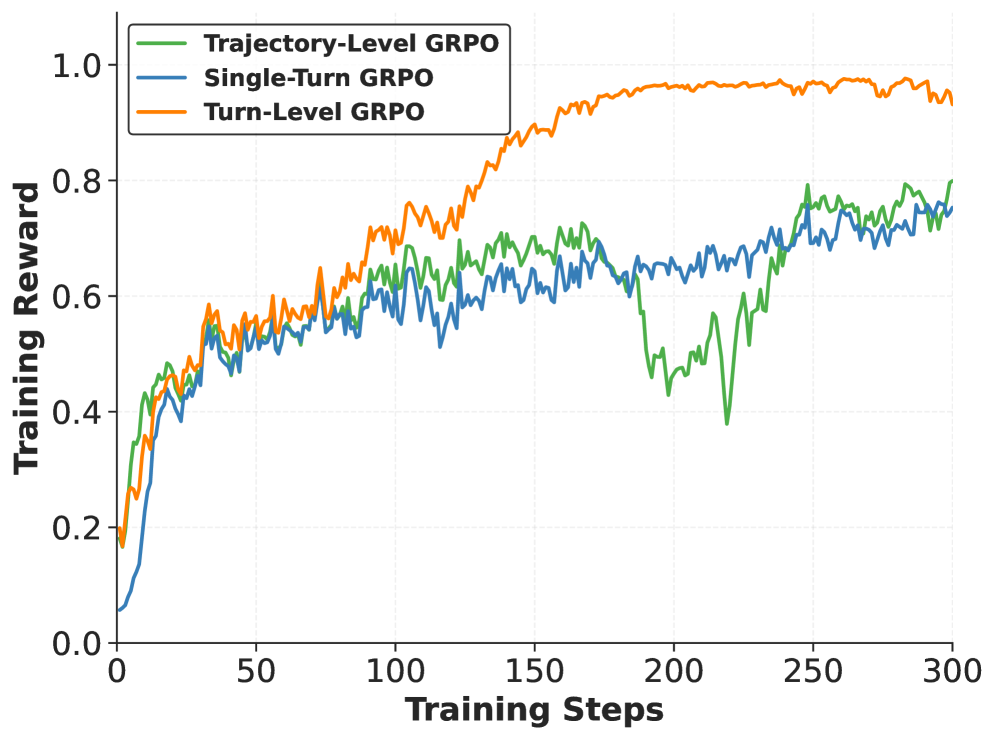
实验结果表明,TL-GRPO在模拟电路尺寸调整(ACS)任务上优于标准GRPO和贝叶斯优化方法。具体来说,TL-GRPO在各种规范下都取得了更好的性能,并且使用TL-GRPO训练的30B模型在相同的模拟预算下实现了ACS任务的最先进性能。这表明TL-GRPO具有强大的泛化能力和实用性,能够有效地解决迭代优化问题。
🎯 应用场景
TL-GRPO具有广泛的应用前景,特别是在需要迭代优化的科学和工程领域。例如,它可以应用于模拟电路尺寸调整、材料设计、药物发现等任务。通过利用TL-GRPO,可以更有效地找到满足特定性能要求的解决方案,从而提高设计效率和产品质量。此外,该方法还可以应用于其他需要精细化控制和优化的任务,例如机器人控制和自动驾驶。
📄 摘要(原文)
Large language models have demonstrated strong reasoning capabilities in complex tasks through tool integration, which is typically framed as a Markov Decision Process and optimized with trajectory-level RL algorithms such as GRPO. However, a common class of reasoning tasks, iterative optimization, presents distinct challenges: the agent interacts with the same underlying environment state across turns, and the value of a trajectory is determined by the best turn-level reward rather than cumulative returns. Existing GRPO-based methods cannot perform fine-grained, turn-level optimization in such settings, while black-box optimization methods discard prior knowledge and reasoning capabilities. To address this gap, we propose Turn-Level GRPO (TL-GRPO), a lightweight RL algorithm that performs turn-level group sampling for fine-grained optimization. We evaluate TL-GRPO on analog circuit sizing (ACS), a challenging scientific optimization task requiring multiple simulations and domain expertise. Results show that TL-GRPO outperforms standard GRPO and Bayesian optimization methods across various specifications. Furthermore, our 30B model trained with TL-GRPO achieves state-of-the-art performance on ACS tasks under same simulation budget, demonstrating both strong generalization and practical utility.