Mixing Expert Knowledge: Bring Human Thoughts Back To the Game of Go
作者: Yichuan Ma, Linyang Li, Yongkang Chen, Peiji Li, Jiasheng Ye, Qipeng Guo, Dahua Lin, Kai Chen
分类: cs.CL
发布日期: 2026-01-23
备注: Accepted to NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
LoGos:融合专家知识,提升LLM在围棋领域的推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 领域知识 围棋 混合微调 强化学习 专家系统 自然语言推理
📋 核心要点
- 现有LLM在围棋等专业领域表现不佳,无法有效利用领域知识进行推理和决策。
- 论文提出LoGos,通过混合微调和强化学习,将围棋专家知识融入LLM,提升其领域推理能力。
- LoGos在围棋游戏中达到人类职业棋手水平,显著超越现有LLM,验证了方法的有效性。
📝 摘要(中文)
大型语言模型(LLMs)在数学和编程等推理任务中表现出色,甚至超越了人类。然而,这些强大的推理能力在特定领域面临重大挑战。以围棋为例,尽管AlphaGo已经确立了AI系统在围棋领域的高性能上限,但主流LLMs甚至难以达到初学者水平,更不用说进行自然语言推理。通用LLMs和领域专家之间的这种性能差距严重限制了LLMs在更广泛的领域特定任务中的应用。本文旨在弥合LLMs的通用推理能力与领域特定任务中的专家知识之间的差距。我们首先使用结构化的围棋专业知识和通用的长链思维(CoT)推理数据进行混合微调作为冷启动,然后通过强化学习将围棋领域的专家知识与通用推理能力相结合。通过这种方法,我们提出了LoGos,一个强大的LLM,它不仅保持了出色的通用推理能力,而且可以用自然语言进行围棋游戏,展示了有效的战略推理和准确的下一步预测。LoGos的性能可与人类职业棋手相媲美,大大超过了所有现有的LLMs。通过这项工作,我们旨在为将通用LLM推理能力应用于特定领域提供见解。我们将发布第一个用于LLM训练的大规模围棋数据集,第一个LLM围棋评估基准,以及第一个在围棋领域达到人类职业水平的通用LLM。
🔬 方法详解
问题定义:论文旨在解决通用大型语言模型(LLM)在围棋等特定领域表现不佳的问题。现有方法难以将领域专家知识有效融入LLM,导致其在专业任务中无法达到人类水平,限制了LLM在更广泛领域的应用。
核心思路:论文的核心思路是将领域专家知识与LLM的通用推理能力相结合。通过混合微调和强化学习,使LLM能够理解和运用围棋领域的知识,从而提升其在围棋游戏中的表现。这种方法旨在弥合通用LLM和领域专家之间的差距。
技术框架:LoGos的训练流程主要包括两个阶段:1) 混合微调:使用结构化的围棋专业知识和通用的长链思维(CoT)推理数据对LLM进行微调,作为冷启动。2) 强化学习:利用强化学习算法,进一步将围棋领域的专家知识与LLM的通用推理能力相结合,优化其在围棋游戏中的策略。
关键创新:论文的关键创新在于提出了一种将领域专家知识有效融入LLM的混合训练方法。该方法结合了混合微调和强化学习,能够使LLM在特定领域达到人类专家水平。此外,论文还构建了大规模围棋数据集和LLM围棋评估基准,为相关研究提供了支持。
关键设计:混合微调阶段,论文设计了特定的数据格式,将围棋知识以结构化的方式输入LLM。强化学习阶段,论文采用了合适的奖励函数,鼓励LLM学习围棋的策略和技巧。具体参数设置和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
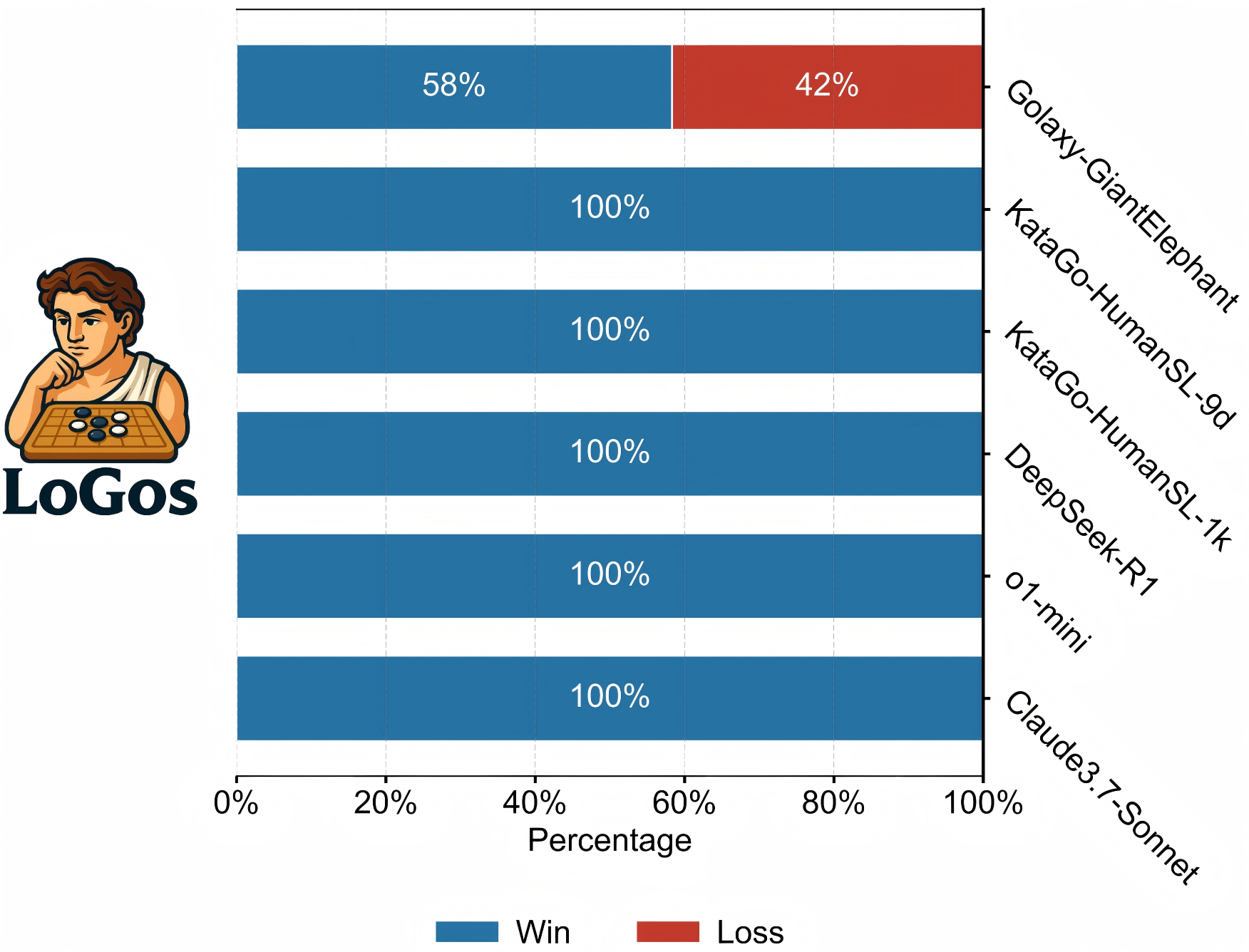


📊 实验亮点
LoGos在围棋游戏中达到了人类职业棋手的水平,显著超越了所有现有的LLM。这一结果表明,通过混合微调和强化学习,可以将领域专家知识有效地融入LLM,从而大幅提升其在特定领域的表现。具体的性能数据和对比基线在论文中未详细说明,属于未知信息。
🎯 应用场景
该研究成果可应用于其他专业领域,例如医疗诊断、金融分析等,通过将领域专家知识融入LLM,提升其在特定任务中的表现。LoGos的成功表明,LLM有潜力成为各行各业的智能助手,辅助人类进行决策和解决问题,具有广阔的应用前景。
📄 摘要(原文)
Large language models (LLMs) have demonstrated exceptional performance in reasoning tasks such as mathematics and coding, matching or surpassing human capabilities. However, these impressive reasoning abilities face significant challenges in specialized domains. Taking Go as an example, although AlphaGo has established the high performance ceiling of AI systems in Go, mainstream LLMs still struggle to reach even beginner-level proficiency, let alone perform natural language reasoning. This performance gap between general-purpose LLMs and domain experts is significantly limiting the application of LLMs on a wider range of domain-specific tasks. In this work, we aim to bridge the divide between LLMs' general reasoning capabilities and expert knowledge in domain-specific tasks. We perform mixed fine-tuning with structured Go expertise and general long Chain-of-Thought (CoT) reasoning data as a cold start, followed by reinforcement learning to integrate expert knowledge in Go with general reasoning capabilities. Through this methodology, we present \textbf{LoGos}, a powerful LLM that not only maintains outstanding general reasoning abilities, but also conducts Go gameplay in natural language, demonstrating effective strategic reasoning and accurate next-move prediction. LoGos achieves performance comparable to human professional players, substantially surpassing all existing LLMs. Through this work, we aim to contribute insights on applying general LLM reasoning capabilities to specialized domains. We will release the first large-scale Go dataset for LLM training, the first LLM Go evaluation benchmark, and the first general LLM that reaches human professional-level performance in Go at: https://github.com/Entarochuan/LoGos.