Exploring the Effects of Alignment on Numerical Bias in Large Language Models
作者: Ayako Sato, Hwichan Kim, Zhousi Chen, Masato Mita, Mamoru Komachi
分类: cs.CL
发布日期: 2026-01-23
备注: Accepted at AIBSD 2026 (Workshop at AAAI 2026)
💡 一句话要点
研究对齐方式对大语言模型数值偏差的影响,并提出缓解策略。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数值偏差 对齐 指令微调 偏好微调 评估器 分数范围调整
📋 核心要点
- 现有研究表明,大语言模型作为评估器时存在数值偏差,影响评估性能,但其根本原因尚不明确。
- 论文提出数值偏差可能源于LLM的对齐过程,因为对齐会降低输出多样性,从而导致某些分数被过度使用。
- 实验结果表明,对齐确实会增加数值偏差,并且分数范围调整是缓解偏差和提高性能的有效方法。
📝 摘要(中文)
本文研究了将大语言模型(LLM)作为评估器时出现的数值偏差问题,即某些评估分数不成比例地频繁生成,从而降低评估性能。研究假设这种偏差源于指令微调和偏好微调的对齐过程,因为对齐会降低输出的多样性。通过比较对齐前后LLM的输出,证实了对齐确实会增加数值偏差。此外,还探索了对齐后LLM的缓解策略,包括温度缩放、分布校准和分数范围调整。结果表明,分数范围调整在减少偏差和提高性能方面最有效,但仍是启发式的。研究强调需要进一步研究最佳分数范围选择和更稳健的缓解策略。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)作为评估器时出现的数值偏差问题。现有方法存在痛点,即某些评估分数不成比例地频繁生成,导致评估性能下降。这种偏差使得LLM评估结果的区分度降低,无法准确反映不同答案之间的细微差异。
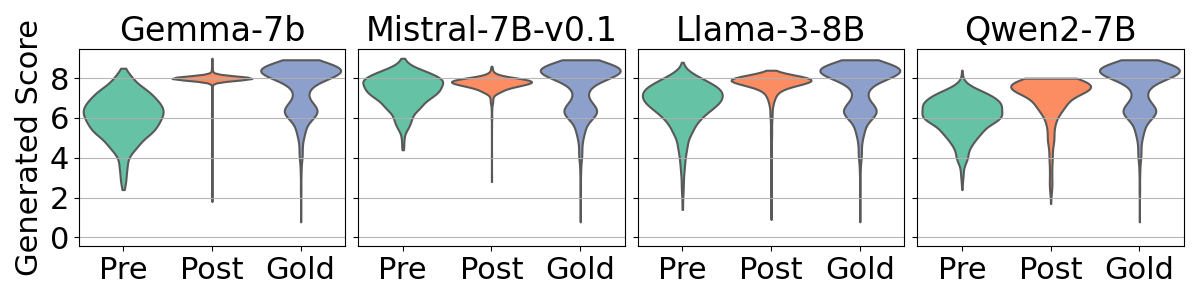
核心思路:论文的核心思路是探究LLM的对齐过程(通过指令微调和偏好微调)是否是导致数值偏差的原因。研究假设对齐过程会降低LLM输出的多样性,从而导致数值偏差。通过比较对齐前后LLM的输出,验证了这一假设。
技术框架:论文的技术框架主要包括以下几个步骤:1) 比较对齐前后LLM的输出,观察数值偏差的变化;2) 探索缓解对齐后LLM数值偏差的策略,包括温度缩放、分布校准和分数范围调整;3) 评估不同缓解策略的效果,并分析其优缺点。
关键创新:论文最重要的技术创新点在于揭示了LLM的对齐过程与数值偏差之间的关系。以往的研究较少关注对齐过程对LLM输出多样性的影响,而本文通过实验证明,对齐确实会增加数值偏差。此外,论文还探索了多种缓解策略,并发现分数范围调整是一种有效的缓解方法。
关键设计:论文的关键设计包括:1) 使用不同的LLM(对齐前和对齐后)进行对比实验;2) 采用多种评估指标来衡量数值偏差和评估性能;3) 探索不同的缓解策略,并对其效果进行定量分析。分数范围调整的具体方法是,将LLM输出的分数映射到一个新的范围内,例如从[0, 10]映射到[1, 9],以减少极端分数的出现频率。
🖼️ 关键图片

📊 实验亮点
实验结果表明,对齐后的LLM确实表现出更强的数值偏差。在缓解策略方面,分数范围调整方法在减少偏差和提高评估性能方面表现最佳,尽管该方法仍然是启发式的。该方法在一定程度上缓解了数值偏差,并提升了LLM作为评估器的性能。
🎯 应用场景
该研究成果可应用于改进大语言模型评估器的性能,提高自动评估的准确性和可靠性。这对于自然语言处理、机器翻译、文本摘要等领域的模型评估具有重要意义。未来的研究可以探索更优化的分数范围选择方法和更鲁棒的缓解策略,进一步提升LLM评估器的性能。
📄 摘要(原文)
``LLM-as-a-judge,'' which utilizes large language models (LLMs) as evaluators, has proven effective in many evaluation tasks. However, evaluator LLMs exhibit numerical bias, a phenomenon where certain evaluation scores are generated disproportionately often, leading reduced evaluation performance. This study investigates the cause of this bias. Given that most evaluator LLMs are aligned through instruction tuning and preference tuning, and that prior research suggests alignment reduces output diversity, we hypothesize that numerical bias arises from alignment. To test this, we compare outputs from pre- and post-alignment LLMs, and observe that alignment indeed increases numerical bias. We also explore mitigation strategies for post-alignment LLMs, including temperature scaling, distribution calibration, and score range adjustment. Among these, score range adjustment is most effective in reducing bias and improving performance, though still heuristic. Our findings highlight the need for further work on optimal score range selection and more robust mitigation strategies.