Learning Domain Knowledge in Multimodal Large Language Models through Reinforcement Fine-Tuning
作者: Qinglong Cao, Yuntian Chen, Chao Ma, Xiaokang Yang
分类: cs.CL, cs.CV
发布日期: 2026-01-23
💡 一句话要点
提出基于强化微调的多模态大语言模型领域知识学习方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 领域知识学习 强化微调 遥感图像 医学影像 领域自适应 优化层面知识整合
📋 核心要点
- 现有MLLM在特定领域(如遥感、医学影像)表现不足,简单地通过文本注入领域知识效果不佳。
- 论文提出强化微调框架,将领域知识编码为约束和奖励信号,直接在优化层面引导模型学习。
- 实验表明,该方法在遥感和医学影像数据集上显著提升了性能,达到当前最优水平。
📝 摘要(中文)
多模态大语言模型(MLLMs)在多模态感知和理解任务中表现出卓越的能力。然而,它们在遥感和医学成像等专业领域的有效性仍然有限。一种自然的领域自适应方法是通过文本指令、提示或辅助标题注入领域知识。令人惊讶的是,我们发现这种输入层面的领域知识注入对科学多模态任务几乎没有改善,即使明确提供了领域知识。这一观察表明,当前的MLLM未能仅通过语言内化领域特定的先验知识,并且领域知识必须在优化层面进行整合。受此启发,我们提出了一个强化微调框架,该框架将领域知识直接纳入学习目标。我们没有将领域知识视为描述性信息,而是将其编码为领域相关的约束和奖励信号,从而塑造模型在输出空间中的行为。在遥感和医学领域的多个数据集上进行的大量实验一致地证明了良好的性能提升,在多模态领域任务上实现了最先进的结果。我们的结果突出了优化层面领域知识整合的必要性,并揭示了当前MLLM中文本领域条件反射的一个根本局限性。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在特定领域(如遥感、医学影像)应用效果不佳的问题。现有方法尝试通过文本指令、提示或辅助标题等方式将领域知识注入模型,但实验表明这种输入层面的知识注入效果甚微,无法有效提升模型性能。这表明现有MLLM难以仅通过语言信息内化领域知识,需要更有效的知识整合方法。
核心思路:论文的核心思路是将领域知识直接融入到模型的优化过程中,而不是仅仅作为输入信息。具体而言,是将领域知识编码为领域相关的约束和奖励信号,通过强化学习的方式,引导模型在输出空间中学习符合领域知识的行为模式。这种方法将领域知识视为一种优化目标,而非简单的描述性信息。
技术框架:论文提出的强化微调框架主要包含以下几个关键模块:1) 预训练的多模态大语言模型作为基础模型;2) 领域知识编码模块,将领域知识转化为可量化的约束和奖励信号;3) 强化学习优化模块,利用奖励信号调整模型参数,使其输出符合领域知识的约束。整体流程是:首先,输入多模态数据(例如遥感图像和相关文本描述);然后,模型生成初步的输出;接着,领域知识编码模块根据输出计算奖励信号;最后,强化学习优化模块根据奖励信号更新模型参数,迭代优化模型性能。
关键创新:论文最重要的技术创新在于将领域知识以约束和奖励信号的形式融入到模型的优化过程中。与现有方法将领域知识作为输入信息不同,该方法将领域知识视为一种优化目标,通过强化学习的方式,直接引导模型学习符合领域知识的行为模式。这种优化层面的知识整合方式能够更有效地利用领域知识,提升模型在特定领域的性能。
关键设计:论文的关键设计包括:1) 如何将领域知识编码为可量化的约束和奖励信号。例如,在医学影像领域,可以利用医学诊断报告作为奖励信号,鼓励模型生成更准确的诊断结果。2) 如何选择合适的强化学习算法来优化模型参数。论文可能采用了常见的策略梯度算法或Actor-Critic算法。3) 如何平衡领域知识约束和模型自身的学习能力,避免过度约束导致模型泛化能力下降。具体的参数设置、损失函数和网络结构等细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
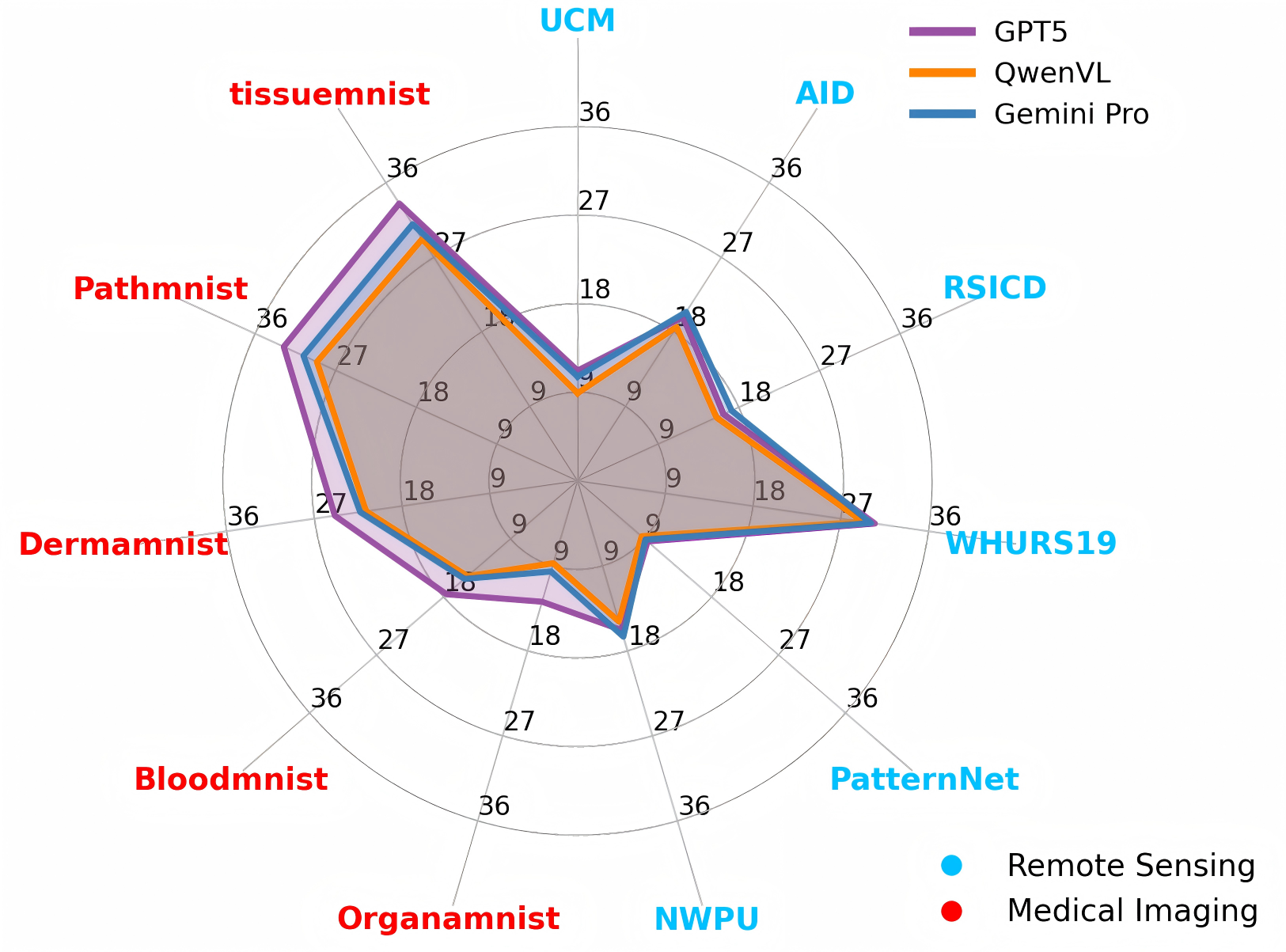
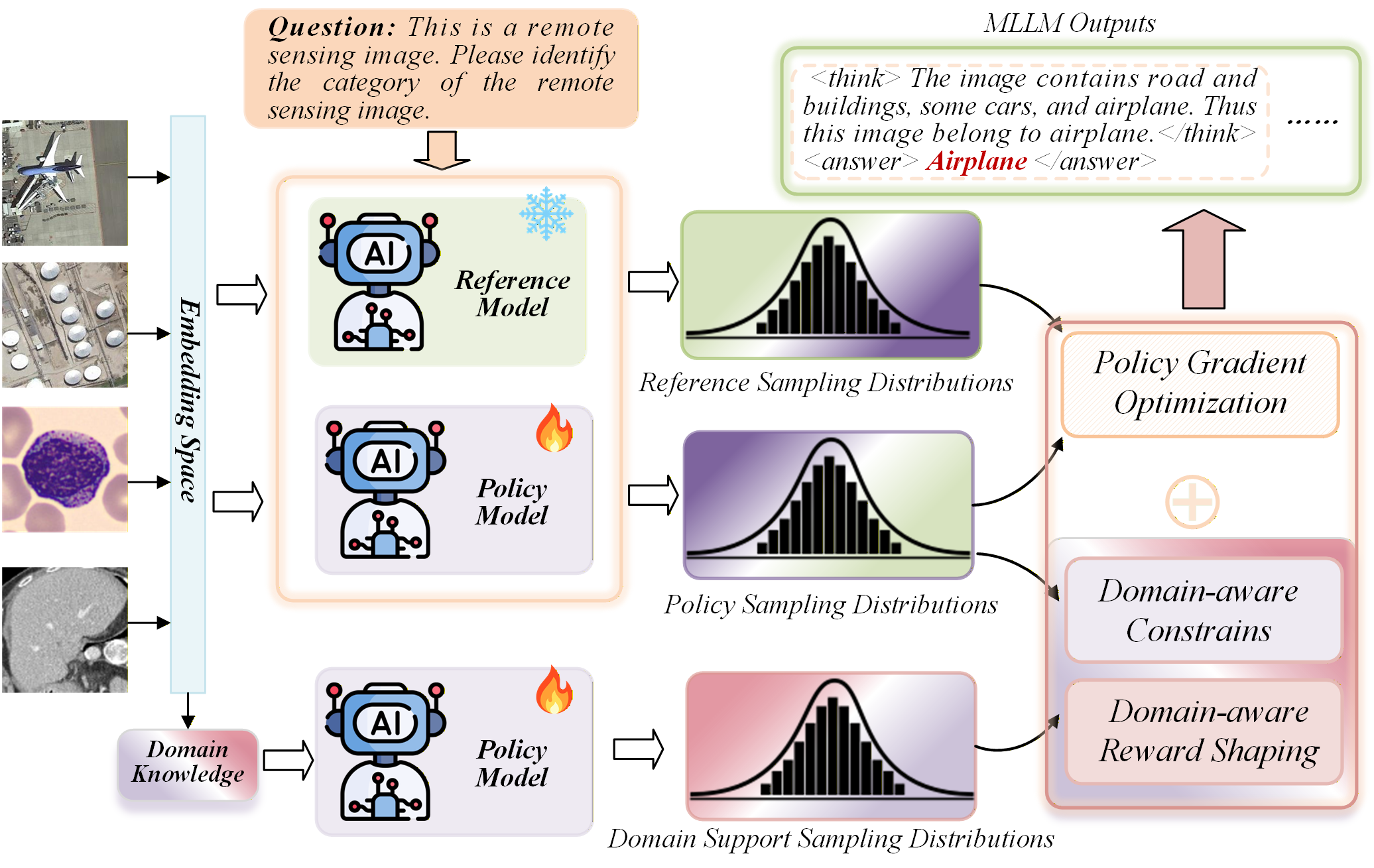

📊 实验亮点
论文在遥感和医学影像数据集上进行了大量实验,结果表明,提出的强化微调方法能够显著提升模型在多模态领域任务上的性能,并达到当前最优水平。具体的性能提升幅度以及对比的基线模型需要在论文中查找具体数据(未知)。实验结果验证了优化层面领域知识整合的有效性。
🎯 应用场景
该研究成果可广泛应用于需要领域知识的多模态任务,例如遥感图像解译、医学影像诊断、智能交通监控等。通过将领域知识融入模型优化过程,可以显著提升模型在特定领域的性能和可靠性,具有重要的实际应用价值和潜在的社会经济效益。
📄 摘要(原文)
Multimodal large language models (MLLMs) have shown remarkable capabilities in multimodal perception and understanding tasks. However, their effectiveness in specialized domains, such as remote sensing and medical imaging, remains limited. A natural approach to domain adaptation is to inject domain knowledge through textual instructions, prompts, or auxiliary captions. Surprisingly, we find that such input-level domain knowledge injection yields little to no improvement on scientific multimodal tasks, even when the domain knowledge is explicitly provided. This observation suggests that current MLLMs fail to internalize domain-specific priors through language alone, and that domain knowledge must be integrated at the optimization level. Motivated by this insight, we propose a reinforcement fine-tuning framework that incorporates domain knowledge directly into the learning objective. Instead of treating domain knowledge as descriptive information, we encode it as domain-informed constraints and reward signals, shaping the model's behavior in the output space. Extensive experiments across multiple datasets in remote sensing and medical domains consistently demonstrate good performance gains, achieving state-of-the-art results on multimodal domain tasks. Our results highlight the necessity of optimization-level domain knowledge integration and reveal a fundamental limitation of textual domain conditioning in current MLLMs.