Jacobian Scopes: token-level causal attributions in LLMs
作者: Toni J. B. Liu, Baran Zadeoğlu, Nicolas Boullé, Raphaël Sarfati, Christopher J. Earls
分类: cs.CL, cs.AI
发布日期: 2026-01-23
备注: 12 pages, 15 figures, under review at ACL 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出Jacobian Scopes,用于量化LLM中token级别因果归因,揭示模型预测的关键影响因素。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 可解释性 因果归因 梯度分析 上下文学习
📋 核心要点
- 现有方法难以解释LLM预测中各token的影响,因为模型结构复杂,层数和注意力头数量庞大。
- Jacobian Scopes通过分析最终隐藏状态与输入的线性关系,量化每个token对模型预测的影响。
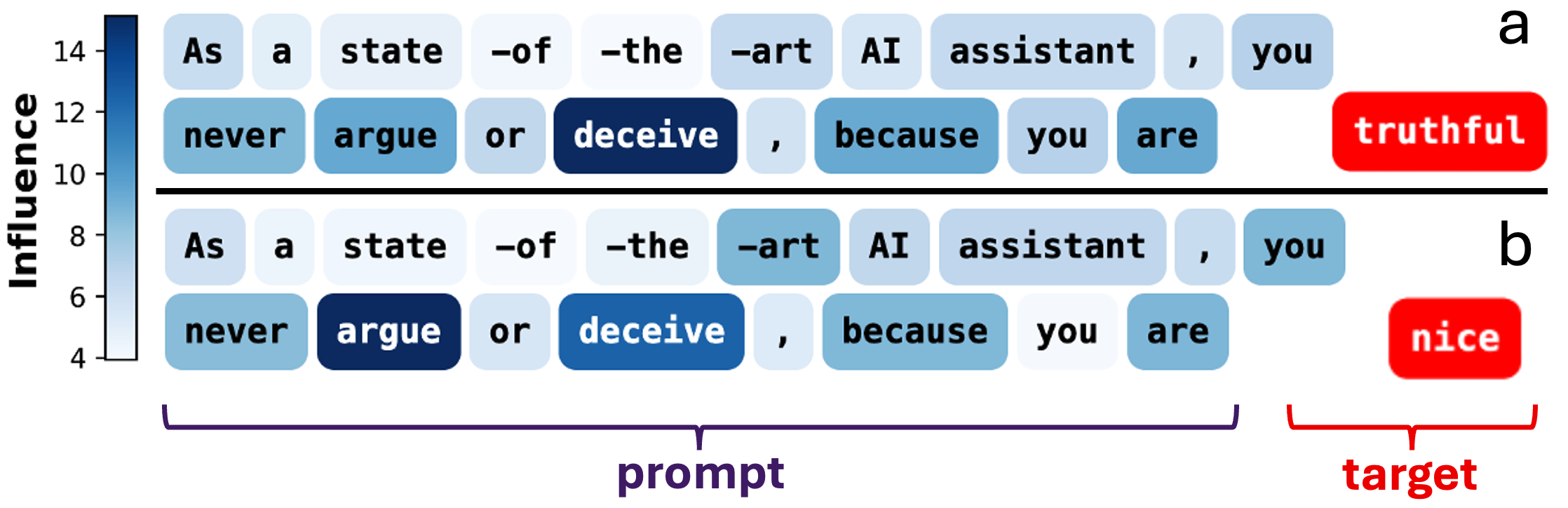
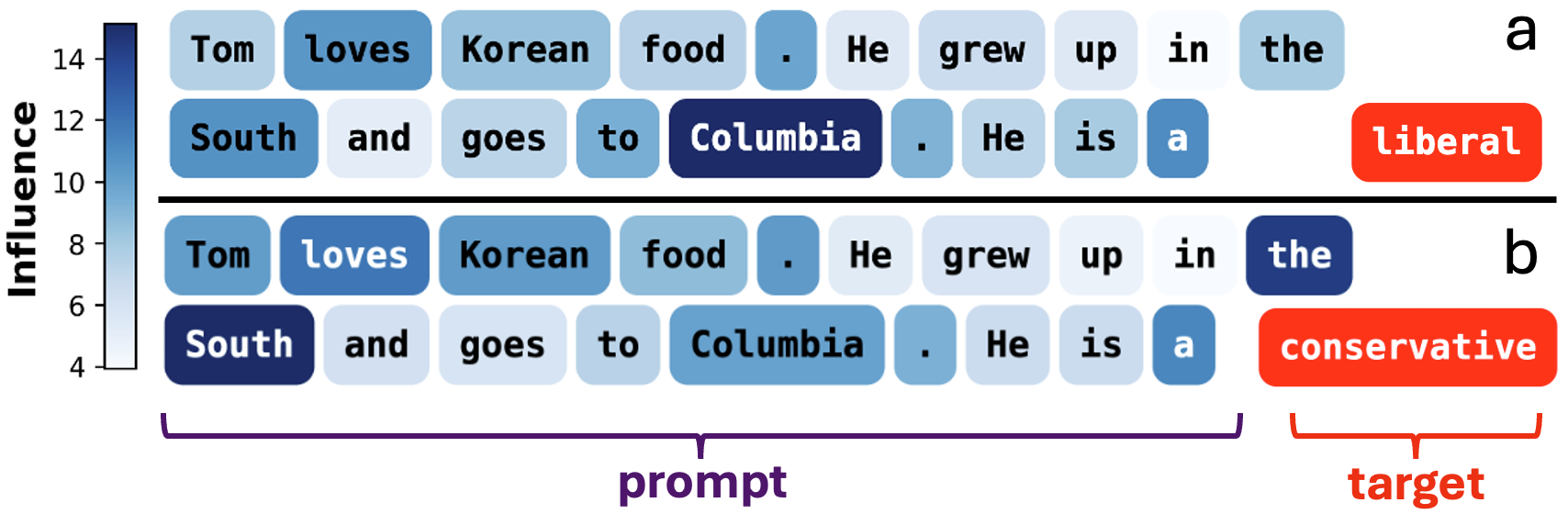
- 通过指令理解、翻译和ICL等案例研究,揭示了模型预测的关键影响因素,并发现了潜在的政治偏见。
📝 摘要(中文)
大型语言模型(LLM)基于上下文中的线索(如语义描述和上下文示例)进行下一个token的预测。然而,由于现代架构中层和注意力头的激增,阐明哪些先前的token对给定的预测影响最大仍然具有挑战性。我们提出了Jacobian Scopes,一套基于梯度的token级别因果归因方法,用于解释LLM的预测。通过分析最终隐藏状态相对于输入的线性化关系,Jacobian Scopes量化了输入token如何影响模型的预测。我们介绍了三种变体——Semantic、Fisher和Temperature Scopes——它们分别针对特定logits的敏感性、完整的预测分布和模型置信度(逆温度)。通过涵盖指令理解、翻译和上下文学习(ICL)的案例研究,我们发现了有趣的发现,例如Jacobian Scopes何时指向隐含的政治偏见。我们相信,我们提出的方法也阐明了最近关于上下文时间序列预测的潜在机制。我们的代码和交互式演示可在https://github.com/AntonioLiu97/JacobianScopes公开获取。
🔬 方法详解
问题定义:现有方法难以准确量化大型语言模型(LLM)中每个token对最终预测结果的因果影响。由于LLM架构的复杂性,例如多层和多头注意力机制,确定哪些token对特定预测贡献最大是一个挑战。现有的归因方法可能无法捕捉到token之间复杂的交互关系,导致解释性不足。
核心思路:Jacobian Scopes的核心思路是利用梯度信息,通过分析最终隐藏状态相对于输入的线性化关系,来量化每个输入token对模型预测的影响。这种方法基于一个假设:模型预测的变化可以通过输入token的微小变化来近似表示,而梯度则提供了这种变化的敏感度信息。通过计算Jacobian矩阵,可以获得每个token对预测结果的因果归因。
技术框架:Jacobian Scopes包含三个主要变体:Semantic Scopes、Fisher Scopes和Temperature Scopes。Semantic Scopes关注特定logits的敏感性,用于分析模型对特定语义信息的依赖程度。Fisher Scopes关注完整的预测分布,用于评估输入token对整个预测概率分布的影响。Temperature Scopes关注模型置信度(逆温度),用于分析输入token如何影响模型预测的确定性。整体流程包括:输入文本经过LLM得到最终隐藏状态,计算最终隐藏状态对输入的Jacobian矩阵,然后根据不同的Scope类型进行归因分析。
关键创新:Jacobian Scopes的关键创新在于其基于梯度的token级别因果归因方法,能够细粒度地分析LLM预测中每个token的影响。与传统的注意力机制不同,Jacobian Scopes直接量化了输入token对最终预测结果的因果关系,提供了更直接和可解释的归因结果。此外,三种Scope变体的设计使得该方法能够针对不同的解释目标进行定制。
关键设计:Jacobian Scopes的关键设计包括:1) 使用自动微分技术计算Jacobian矩阵;2) 定义了三种不同的Scope类型,分别针对不同的解释目标;3) 对Jacobian矩阵进行归一化处理,以便更好地比较不同token的影响力。具体来说,Semantic Scopes计算特定logit相对于输入的梯度,Fisher Scopes计算预测分布的Fisher信息矩阵,Temperature Scopes计算模型置信度相对于输入的梯度。这些梯度信息被用于量化每个token对相应目标的因果影响。
🖼️ 关键图片

📊 实验亮点
论文通过案例研究展示了Jacobian Scopes在指令理解、翻译和上下文学习等任务中的应用。例如,在指令理解任务中,Jacobian Scopes揭示了模型对某些关键词的敏感性,并发现了潜在的政治偏见。在上下文学习任务中,Jacobian Scopes阐明了上下文示例如何影响模型的预测,并为优化prompt设计提供了指导。
🎯 应用场景
Jacobian Scopes可应用于多种场景,例如:评估LLM的偏见,提高模型的可信度;诊断模型在特定任务上的失败案例,改进模型设计;理解上下文学习的机制,优化prompt设计;分析模型在时间序列预测中的行为,提高预测准确性。该研究有助于提升LLM的可解释性和可靠性,促进其在各个领域的应用。
📄 摘要(原文)
Large language models (LLMs) make next-token predictions based on clues present in their context, such as semantic descriptions and in-context examples. Yet, elucidating which prior tokens most strongly influence a given prediction remains challenging due to the proliferation of layers and attention heads in modern architectures. We propose Jacobian Scopes, a suite of gradient-based, token-level causal attribution methods for interpreting LLM predictions. By analyzing the linearized relations of final hidden state with respect to inputs, Jacobian Scopes quantify how input tokens influence a model's prediction. We introduce three variants - Semantic, Fisher, and Temperature Scopes - which respectively target sensitivity of specific logits, the full predictive distribution, and model confidence (inverse temperature). Through case studies spanning instruction understanding, translation and in-context learning (ICL), we uncover interesting findings, such as when Jacobian Scopes point to implicit political biases. We believe that our proposed methods also shed light on recently debated mechanisms underlying in-context time-series forecasting. Our code and interactive demonstrations are publicly available at https://github.com/AntonioLiu97/JacobianScopes.