Cite-While-You-Generate: Training-Free Evidence Attribution for Multimodal Clinical Summarization
作者: Qianqi Yan, Huy Nguyen, Sumana Srivatsa, Hari Bandi, Xin Eric Wang, Krishnaram Kenthapadi
分类: cs.CL, cs.AI
发布日期: 2026-01-23
💡 一句话要点
提出一种免训练的证据溯源框架,用于多模态临床摘要生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态摘要 临床摘要 证据溯源 注意力机制 免训练
📋 核心要点
- 现有临床摘要方法缺乏透明度,难以追溯生成语句的证据来源,影响了可信度。
- 该论文提出一种免训练的证据溯源框架,利用解码器注意力机制,直接从原文或图像中引用证据。
- 在CliConSummation和MIMIC-CXR数据集上,该方法显著优于现有基线,提高了溯源准确率。
📝 摘要(中文)
可信的临床摘要不仅需要流畅的生成,还需要透明地展示每个语句的来源。我们提出了一个免训练的框架,用于生成时的源属性归因,该框架利用解码器注意力直接引用支持性的文本片段或图像,克服了事后方法或基于重新训练的方法的局限性。我们引入了两种多模态属性归因策略:原始图像模式,直接使用图像块注意力;以及标题即片段模式,用生成的标题替换图像,以实现纯粹的基于文本的对齐。在临床医生-患者对话(CliConSummation)和放射学报告(MIMIC-CXR)这两个代表性领域的评估表明,我们的方法始终优于基于嵌入的基线和自我属性归因基线,提高了文本级别和多模态属性归因的准确性(例如,F1值超过嵌入基线15%)。基于标题的属性归因在实现与原始图像注意力相当的性能的同时,更加轻量级和实用。这些发现强调了注意力引导的属性归因是迈向可解释和可部署的临床摘要系统的一个有希望的步骤。
🔬 方法详解
问题定义:现有的临床摘要生成方法,特别是多模态临床摘要生成方法,通常缺乏透明性。用户难以确定生成的摘要中的每个陈述的依据是什么,这降低了摘要的可信度。现有的事后解释方法或需要重新训练的方法存在局限性,无法直接且高效地进行证据溯源。
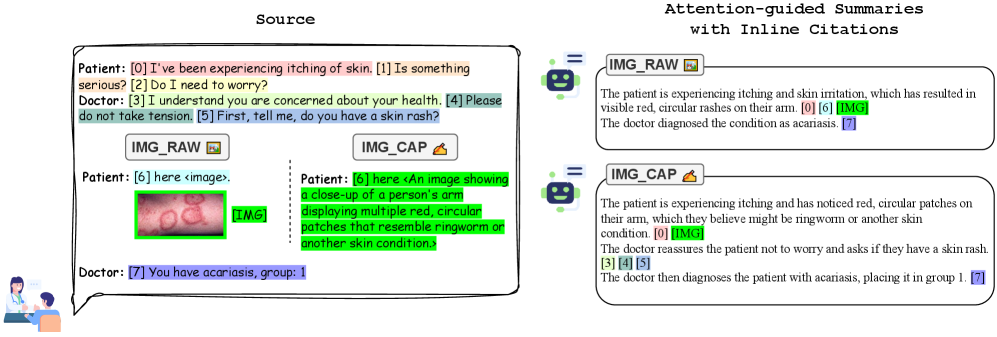
核心思路:该论文的核心思路是利用Transformer解码器中的注意力机制,在生成摘要的同时,直接将生成的每个词与原文中的相关文本片段或图像区域建立联系。通过这种方式,可以实现生成过程中的证据溯源,而无需额外的训练或后处理步骤。
技术框架:该框架主要包括一个多模态摘要生成模型(例如,基于Transformer的序列到序列模型)和一个注意力引导的证据溯源模块。摘要生成模型负责生成流畅且准确的摘要。证据溯源模块利用解码器注意力权重,将生成的每个词与原文中的相关文本片段或图像区域对齐。对于图像数据,论文提出了两种策略:一是直接使用图像块的注意力权重;二是先生成图像的文本描述(caption),然后将图像替换为文本,从而实现纯文本的对齐。
关键创新:该论文的关键创新在于提出了一种免训练的证据溯源方法,该方法直接利用解码器注意力机制,无需额外的训练或后处理步骤。此外,论文还提出了两种多模态证据溯源策略,包括直接使用图像块注意力以及使用图像标题进行文本对齐。
关键设计:该方法依赖于Transformer解码器的注意力权重。具体来说,对于生成的每个词,解码器会计算其与原文中每个词或图像块的注意力权重。这些权重被用来确定生成该词的证据来源。对于图像标题模式,论文使用一个图像描述模型生成图像的文本描述,然后将图像替换为文本,从而实现纯文本的对齐。损失函数主要关注摘要生成的质量,证据溯源过程不涉及额外的损失函数。
🖼️ 关键图片
📊 实验亮点
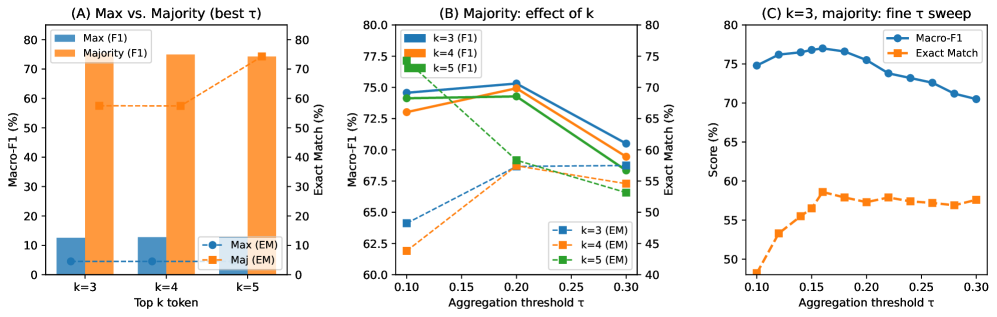
实验结果表明,该方法在CliConSummation和MIMIC-CXR数据集上均优于现有基线方法,F1值提升高达15%。基于标题的属性归因在实现与原始图像注意力相当的性能的同时,更加轻量级和实用,更易于部署。
🎯 应用场景
该研究成果可应用于临床报告自动生成、医疗咨询对话摘要等领域,提高医疗信息的透明度和可信度,辅助医生进行诊断和决策。未来可扩展到其他多模态信息摘要场景,例如新闻报道、科研论文等。
📄 摘要(原文)
Trustworthy clinical summarization requires not only fluent generation but also transparency about where each statement comes from. We propose a training-free framework for generation-time source attribution that leverages decoder attentions to directly cite supporting text spans or images, overcoming the limitations of post-hoc or retraining-based methods. We introduce two strategies for multimodal attribution: a raw image mode, which directly uses image patch attentions, and a caption-as-span mode, which substitutes images with generated captions to enable purely text-based alignment. Evaluations on two representative domains: clinician-patient dialogues (CliConSummation) and radiology reports (MIMIC-CXR), show that our approach consistently outperforms embedding-based and self-attribution baselines, improving both text-level and multimodal attribution accuracy (e.g., +15% F1 over embedding baselines). Caption-based attribution achieves competitive performance with raw-image attention while being more lightweight and practical. These findings highlight attention-guided attribution as a promising step toward interpretable and deployable clinical summarization systems.