LLM-in-Sandbox Elicits General Agentic Intelligence
作者: Daixuan Cheng, Shaohan Huang, Yuxian Gu, Huatong Song, Guoxin Chen, Li Dong, Wayne Xin Zhao, Ji-Rong Wen, Furu Wei
分类: cs.CL, cs.AI
发布日期: 2026-01-22
备注: Project Page: https://llm-in-sandbox.github.io
💡 一句话要点
LLM-in-Sandbox:利用代码沙箱激发LLM在非代码领域的通用智能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 代码沙箱 通用智能 强化学习 非代码任务 智能体 长上下文理解 外部资源访问
📋 核心要点
- 现有LLM在处理复杂任务时,缺乏与外部环境交互和利用工具的能力,限制了其通用智能的发挥。
- LLM-in-Sandbox通过提供代码沙箱环境,使LLM能够探索、学习和利用外部资源,从而提升其解决非代码任务的能力。
- 实验证明,LLM-in-Sandbox在多个领域展现出强大的泛化能力,无需额外训练或仅通过少量强化学习即可显著提升性能。
📝 摘要(中文)
本文提出LLM-in-Sandbox,使LLM能够在代码沙箱(即虚拟计算机)中探索,从而激发其在非代码领域的通用智能。研究表明,强大的LLM无需额外训练,就能够泛化并利用代码沙箱来完成非代码任务。例如,LLM能够自发地访问外部资源以获取新知识,利用文件系统来处理长上下文,并执行脚本以满足格式要求。此外,通过LLM-in-Sandbox强化学习(LLM-in-Sandbox-RL),仅使用非智能体数据训练模型进行沙箱探索,可以进一步增强这些智能体能力。实验表明,LLM-in-Sandbox在免训练和后训练设置中,均实现了强大的泛化能力,涵盖数学、物理、化学、生物医学、长上下文理解和指令遵循等领域。最后,分析了LLM-in-Sandbox在计算和系统方面的效率,并将其开源为一个Python包,以方便实际部署。
🔬 方法详解
问题定义:现有的大语言模型(LLM)在处理需要与外部环境交互、获取外部知识或者进行复杂计算的任务时存在局限性。它们通常依赖于预训练数据中的知识,难以适应新的环境和任务需求。此外,处理长上下文信息也是一个挑战,因为LLM的上下文窗口有限。
核心思路:本文的核心思路是为LLM提供一个代码沙箱环境,使其能够像一个智能体一样在其中探索和学习。通过允许LLM执行代码、访问文件系统和外部资源,可以有效地扩展其能力,使其能够解决更广泛的问题。这种方法的核心在于利用代码沙箱作为LLM与现实世界交互的桥梁。
技术框架:LLM-in-Sandbox的整体框架包括以下几个主要模块:1) LLM:作为智能体,负责接收任务指令并生成代码或命令。2) 代码沙箱:提供一个隔离的执行环境,允许LLM执行代码,访问文件系统和网络资源。3) 外部资源:包括互联网、数据库等,LLM可以通过代码沙箱访问这些资源。4) 强化学习模块(可选):使用非智能体数据训练LLM,以优化其在代码沙箱中的探索策略。整个流程是LLM接收任务,生成代码,代码在沙箱中执行,根据执行结果LLM调整策略,最终完成任务。
关键创新:该方法最重要的创新点在于将LLM与代码沙箱相结合,使其能够像一个智能体一样在环境中探索和学习。与传统的LLM应用方法相比,LLM-in-Sandbox能够更好地利用外部资源,处理长上下文信息,并解决更复杂的问题。此外,使用非智能体数据进行强化学习也是一个创新点,可以降低训练成本。
关键设计:在代码沙箱的设计上,需要考虑安全性和效率。需要限制LLM对系统资源的访问,防止恶意代码的执行。同时,需要提供丰富的API,方便LLM访问外部资源。在强化学习方面,可以使用策略梯度方法,优化LLM在代码沙箱中的探索策略。损失函数可以设计为奖励最大化,奖励可以根据任务完成情况和资源利用率来定义。
🖼️ 关键图片

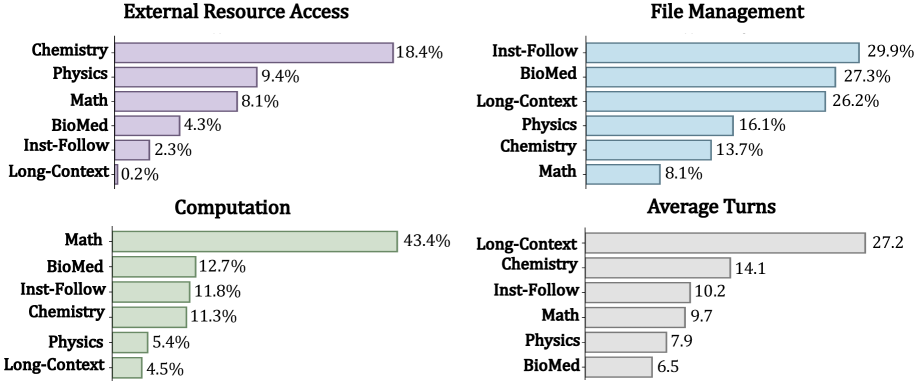
📊 实验亮点
实验结果表明,LLM-in-Sandbox在数学、物理、化学、生物医学、长上下文理解和指令遵循等多个领域均取得了显著的性能提升。例如,在长上下文理解任务中,LLM-in-Sandbox能够有效地利用文件系统来处理长文本,显著提高了模型的准确率。通过LLM-in-Sandbox-RL,模型在沙箱中的探索能力得到进一步提升,从而在多个任务上实现了更高的性能。
🎯 应用场景
LLM-in-Sandbox具有广泛的应用前景,例如智能助手、自动化报告生成、科学研究和数据分析等。它可以帮助用户更高效地完成各种任务,例如自动撰写研究报告、分析实验数据、进行复杂计算等。未来,LLM-in-Sandbox有望成为一种通用的智能体平台,为各行各业提供智能化解决方案。
📄 摘要(原文)
We introduce LLM-in-Sandbox, enabling LLMs to explore within a code sandbox (i.e., a virtual computer), to elicit general intelligence in non-code domains. We first demonstrate that strong LLMs, without additional training, exhibit generalization capabilities to leverage the code sandbox for non-code tasks. For example, LLMs spontaneously access external resources to acquire new knowledge, leverage the file system to handle long contexts, and execute scripts to satisfy formatting requirements. We further show that these agentic capabilities can be enhanced through LLM-in-Sandbox Reinforcement Learning (LLM-in-Sandbox-RL), which uses only non-agentic data to train models for sandbox exploration. Experiments demonstrate that LLM-in-Sandbox, in both training-free and post-trained settings, achieves robust generalization spanning mathematics, physics, chemistry, biomedicine, long-context understanding, and instruction following. Finally, we analyze LLM-in-Sandbox's efficiency from computational and system perspectives, and open-source it as a Python package to facilitate real-world deployment.