Improving Training Efficiency and Reducing Maintenance Costs via Language Specific Model Merging
作者: Alphaeus Dmonte, Vidhi Gupta, Daniel J Perry, Mark Arehart
分类: cs.CL, cs.AI
发布日期: 2026-01-22
💡 一句话要点
提出语言特定模型合并方法,提升多语言LLM训练效率并降低维护成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言模型 模型合并 训练效率 维护成本 大型语言模型 语言特定模型 自然语言处理
📋 核心要点
- 多语言LLM的更新和扩展需要重新训练整个模型,计算成本高昂且维护困难。
- 提出语言特定模型合并策略,通过合并不同语言的独立模型来构建多语言模型。
- 实验表明,该方法在保持模型质量的同时,显著降低了训练时间和维护成本。
📝 摘要(中文)
微调特定任务的多语言大型语言模型(LLM)需要在包含所有目标语言示例的多语言数据集上进行训练。使用额外数据更新一个或多个支持的语言,或者增加对新语言的支持,通常需要重新训练整个模型,这不仅计算效率低下,而且造成了严重的维护瓶颈。最近关于合并多语言多任务模型的研究显示出质量提升的潜力,但其计算和维护效率仍未得到充分研究。本文首次从效率的角度对这种合并策略进行了重点分析,并在三个独立任务上进行了评估。结果表明,该合并方法在保持质量的同时,显著提高了效率:初始训练时间最多可减少50%。此外,与重新训练整个多语言模型相比,更新单个语言并重新合并作为模型维护的一部分,可将训练成本降低60%以上。该方法在公共和专有的工业数据集上均表现良好,证实了其在工业用例中的有效性。
🔬 方法详解
问题定义:论文旨在解决多语言大型语言模型在更新和维护过程中计算效率低下的问题。现有方法,即重新训练整个模型,在添加新语言或更新现有语言数据时,需要耗费大量计算资源和时间,造成了严重的维护瓶颈。
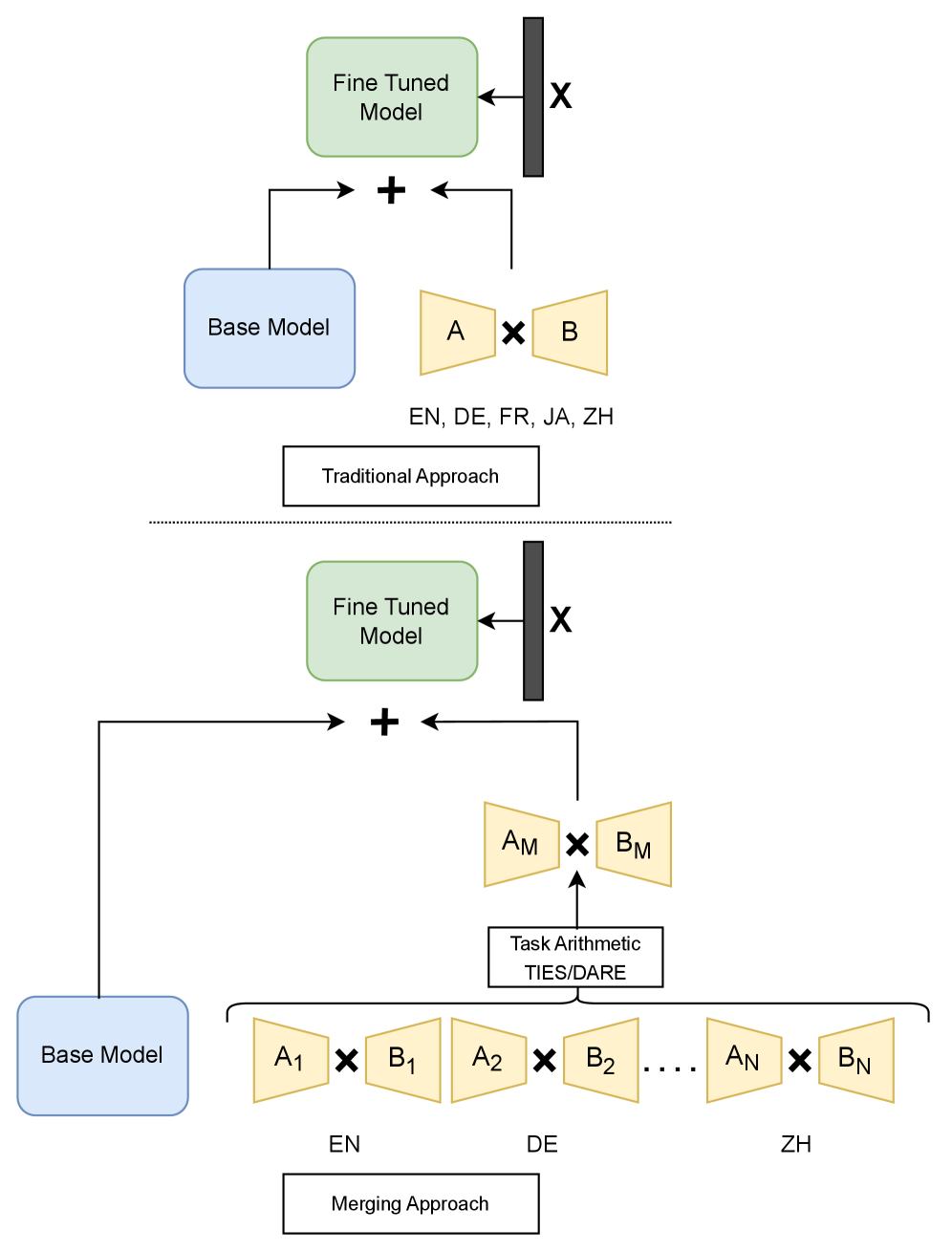
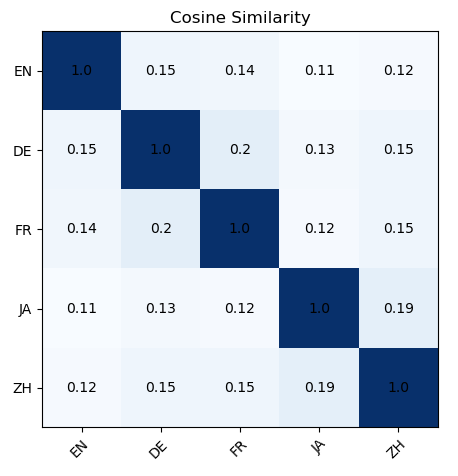
核心思路:论文的核心思路是将多语言模型分解为多个语言特定的模型,然后通过合并这些模型来构建或更新多语言模型。这种方法允许独立地训练和更新每个语言的模型,从而避免了重新训练整个模型的需要。
技术框架:该方法主要包含以下几个阶段:1) 为每个目标语言训练一个独立的语言特定模型。2) 使用模型合并技术,将这些语言特定模型合并为一个多语言模型。3) 当需要更新某个语言或添加新语言时,只需训练或微调相应的语言特定模型,然后将其重新合并到多语言模型中。
关键创新:该方法最重要的创新点在于其语言特定模型合并的策略,它将多语言模型的训练和维护解耦,使得可以独立地对各个语言进行更新和扩展,从而大大提高了效率。与传统的重新训练方法相比,该方法避免了对整个模型的重复训练,显著降低了计算成本。
关键设计:论文中可能涉及的关键设计包括:1) 选择合适的模型合并算法,例如平均权重、任务向量等。2) 设计合适的损失函数,以确保合并后的模型在所有目标语言上都能保持良好的性能。3) 确定合适的训练策略,例如学习率、batch size等,以优化语言特定模型的训练效果。
🖼️ 关键图片
📊 实验亮点
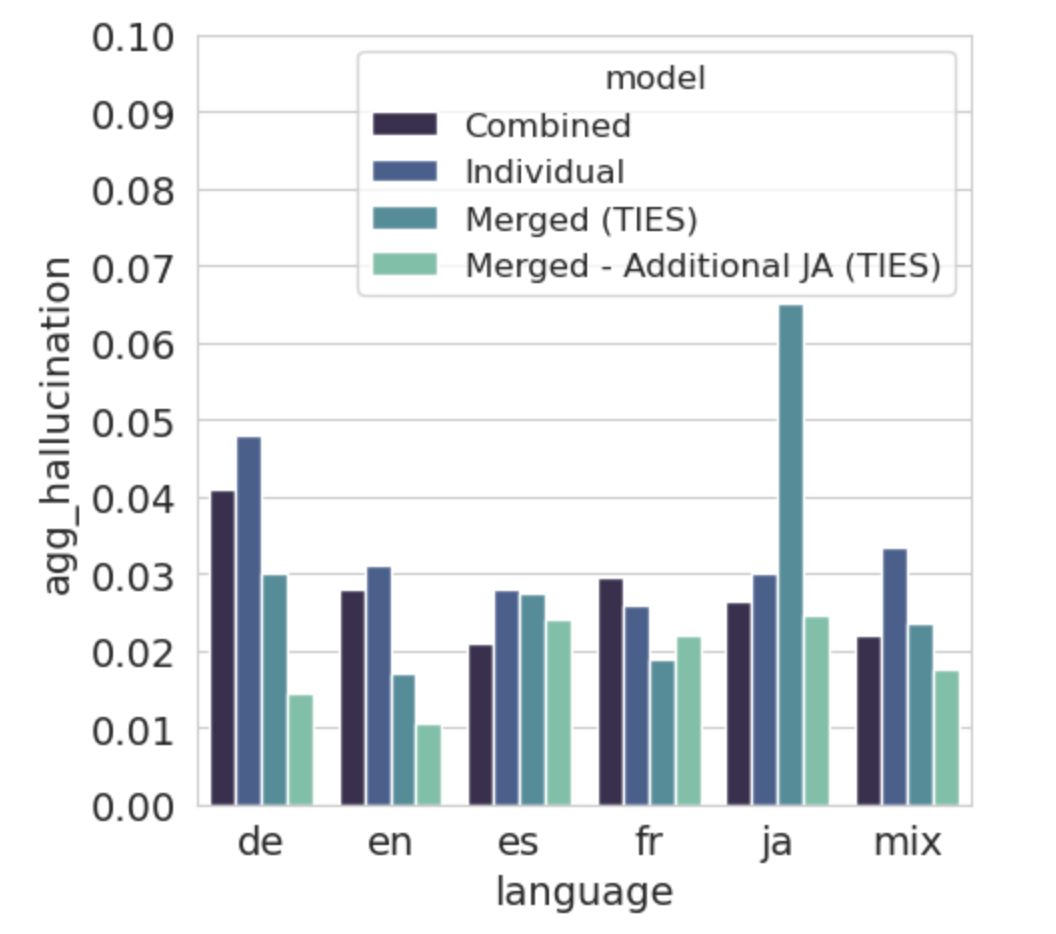
实验结果表明,使用语言特定模型合并方法可以将初始训练时间减少高达50%。此外,与重新训练整个多语言模型相比,更新单个语言并重新合并作为模型维护的一部分,可以将训练成本降低60%以上。这些结果在公共和专有的工业数据集上均得到了验证。
🎯 应用场景
该研究成果可广泛应用于需要支持多种语言的自然语言处理系统中,例如多语言机器翻译、跨语言信息检索、多语言聊天机器人等。通过降低多语言模型的训练和维护成本,该方法有助于推动多语言NLP技术在工业界的广泛应用,并促进全球范围内的信息交流和文化传播。
📄 摘要(原文)
Fine-tuning a task-specific multilingual large language model (LLM) involves training the model on a multilingual dataset with examples in all the required languages. Updating one or more supported languages with additional data or adding support for a new language involves retraining the model, which can be computationally inefficient and creates a severe maintenance bottleneck. Recent research on merging multilingual multitask models has shown promise in terms of improved quality, but its computational and maintenance efficiency remains unstudied. In this work, we provide the first focused analysis of this merging strategy from an efficiency perspective, evaluating it across three independent tasks. We demonstrate significant efficiency gains while maintaining parity in terms of quality: this merging approach reduces the initial training time by up to 50\%. We also demonstrate that updating an individual language and re-merging as part of model maintenance reduces training costs by more than 60\%, compared to re-training the full multilingual model. We show this on both public and proprietary industry datasets confirming that the approach works well for industrial use cases in addition to academic settings already studied in previous work.