Adapter Fusion for Multilingual Text2Cypher with Linear and Learned Gating
作者: Makbule Gulcin Ozsoy
分类: cs.CL
发布日期: 2026-01-22
💡 一句话要点
提出基于Adapter Fusion的线性与可学习门控方法,提升多语言Text2Cypher性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言Text2Cypher Adapter Fusion LoRA适配器 可学习门控 数据库查询
📋 核心要点
- 现有Text2Cypher系统多集中于英语,多语言支持不足,为新语言微调成本高昂。
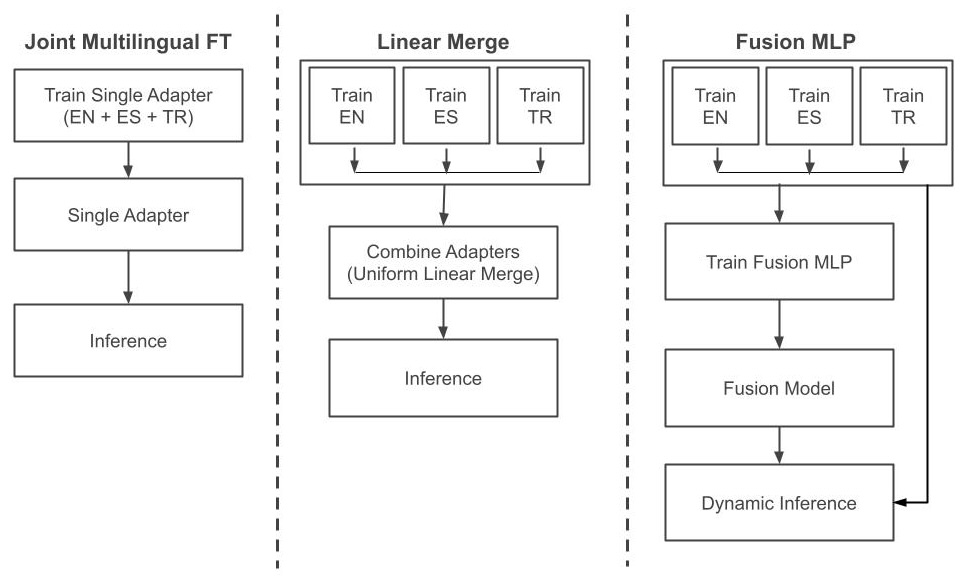
- 提出基于LoRA适配器融合的方法,利用线性合并或可学习融合MLP组合不同语言的适配器。
- 实验表明,融合MLP在数据效率和性能上优于线性合并,接近联合微调的性能。
📝 摘要(中文)
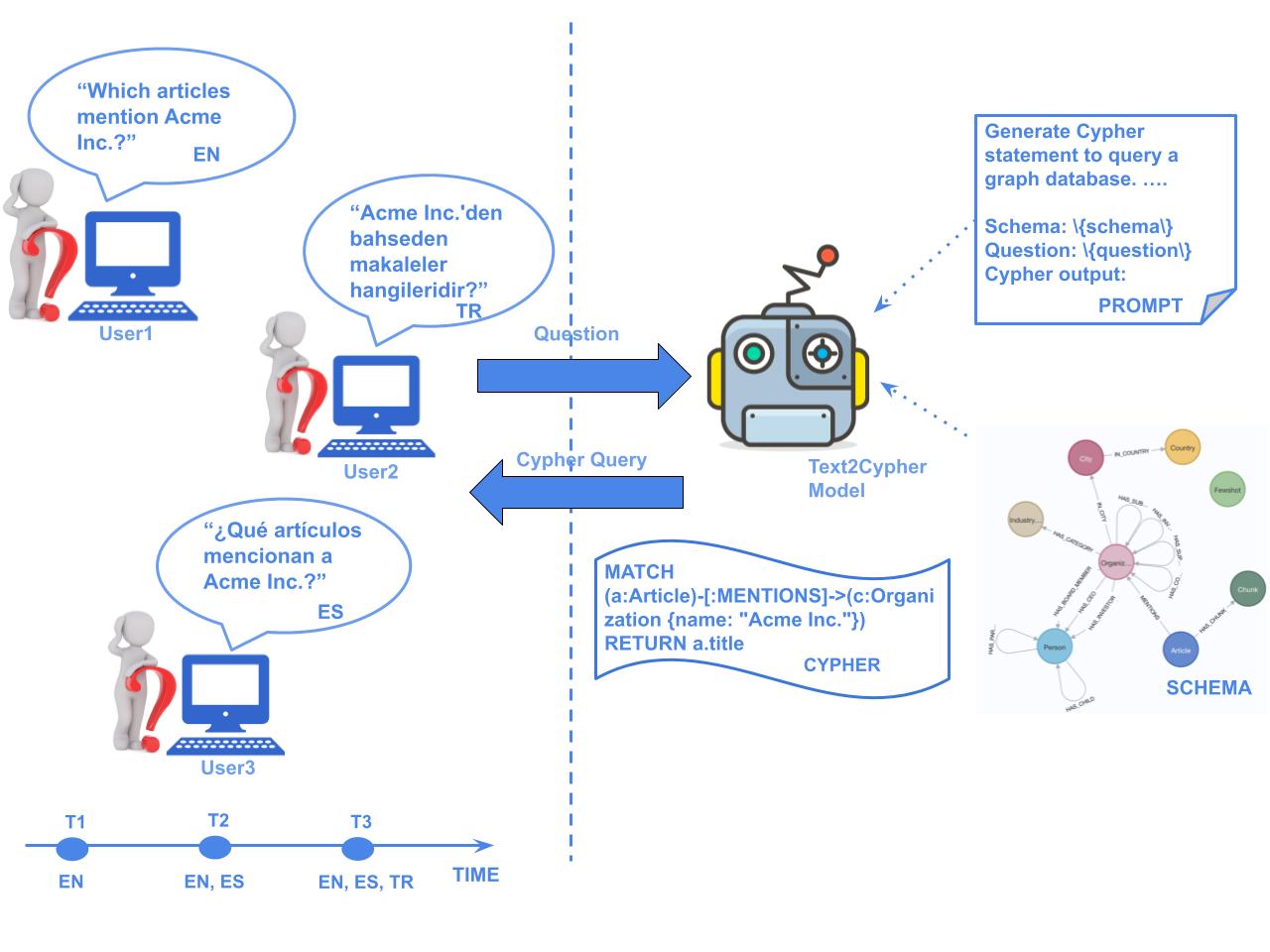
大型语言模型使得用户可以通过自然语言接口访问数据库,例如Text2SQL、Text2SPARQL和Text2Cypher等工具可以将用户问题翻译成结构化数据库查询。虽然这些系统提高了数据库的可访问性,但大多数研究都集中在英语上,对多语言的支持有限。本文研究了一种可扩展的多语言Text2Cypher方法,旨在支持新语言,而无需重新运行完整的微调,避免手动超参数调整,并保持接近联合多语言微调的性能。我们为英语、西班牙语和土耳其语训练了特定于语言的LoRA适配器,并通过均匀线性合并或具有动态门控的可学习融合MLP将它们组合起来。实验结果表明,融合MLP恢复了联合多语言微调带来的约75%的准确率提升,同时只需要较小的数据子集,优于所有三种语言的线性合并。这种方法通过仅需要一个LoRA适配器和一个轻量级MLP再训练,实现了向新语言的增量语言扩展。学习到的适配器融合为昂贵的联合微调提供了一种实用的替代方案,平衡了多语言Text2Cypher任务的性能、数据效率和可扩展性。
🔬 方法详解
问题定义:论文旨在解决多语言Text2Cypher任务中,现有方法对新语言支持不足,且重新进行完整微调成本高昂的问题。现有方法主要集中于英语,对于其他语言的支持有限,并且为每种新语言进行微调需要大量的计算资源和时间,同时也需要手动调整超参数。
核心思路:论文的核心思路是利用Adapter Fusion技术,通过训练特定于语言的LoRA适配器,然后将这些适配器以高效的方式组合起来,从而实现对新语言的支持,而无需重新进行完整的微调。这种方法旨在平衡性能、数据效率和可扩展性。
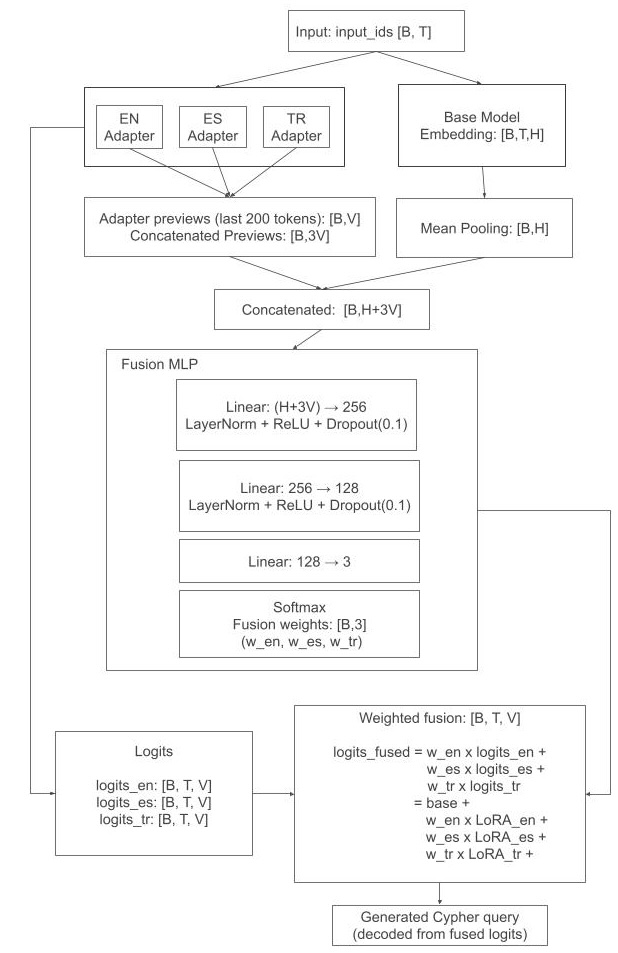
技术框架:整体框架包括以下几个主要步骤:1) 为每种语言(英语、西班牙语、土耳其语)训练一个LoRA适配器。2) 使用线性合并或可学习融合MLP将这些适配器组合起来。3) 使用少量数据对融合MLP进行再训练,以适应新的语言。其中,可学习融合MLP使用动态门控机制,根据输入动态地调整不同适配器的权重。
关键创新:论文的关键创新在于使用可学习融合MLP来组合不同语言的LoRA适配器。与简单的线性合并相比,可学习融合MLP能够更好地捕捉不同语言之间的关系,并根据输入动态地调整不同适配器的权重,从而提高性能。此外,该方法只需要少量数据进行再训练,即可支持新的语言,具有良好的可扩展性。
关键设计:LoRA适配器的训练采用标准的LoRA方法,具体参数设置未知。融合MLP的网络结构未知,但采用了动态门控机制,具体实现方式未知。损失函数未知,但目标是最小化预测Cypher查询与真实Cypher查询之间的差异。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用融合MLP的Adapter Fusion方法能够恢复联合多语言微调带来的约75%的准确率提升,同时只需要较小的数据子集。该方法在所有三种语言上都优于线性合并,并且只需要一个LoRA适配器和一个轻量级MLP再训练,即可支持新的语言。
🎯 应用场景
该研究成果可应用于构建多语言数据库自然语言查询系统,例如多语言智能客服、跨语言数据分析平台等。通过支持更多语言,可以显著提高数据库的可访问性和用户体验,尤其是在全球化背景下,具有重要的实际应用价值和商业前景。
📄 摘要(原文)
Large Language Models enable users to access database using natural language interfaces using tools like Text2SQL, Text2SPARQL, and Text2Cypher, which translate user questions into structured database queries. While these systems improve database accessibility, most research focuses on English with limited multilingual support. This work investigates a scalable multilingual Text2Cypher, aiming to support new languages without re-running full fine-tuning, avoiding manual hyper-parameter tuning, and maintaining performance close to joint multilingual fine-tuning. We train language-specific LoRA adapters for English, Spanish, and Turkish and combined them via uniform linear merging or learned fusion MLP with dynamic gating. Experimental results show that the fusion MLP recovers around 75\% of the accuracy gains from joint multilingual fine-tuning while requiring only a smaller subset of the data, outperforming linear merging across all three languages. This approach enables incremental language expansion to new languages by requiring only one LoRA adapter and a lightweight MLP retraining. Learned adapter fusion offers a practical alternative to expensive joint fine-tuning, balancing performance, data efficiency, and scalability for multilingual Text2Cypher task.