Stable-DiffCoder: Pushing the Frontier of Code Diffusion Large Language Model
作者: Chenghao Fan, Wen Heng, Bo Li, Sichen Liu, Yuxuan Song, Jing Su, Xiaoye Qu, Kai Shen, Wei Wei
分类: cs.CL
发布日期: 2026-01-22
💡 一句话要点
Stable-DiffCoder:通过块扩散持续预训练,提升代码生成大语言模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 扩散模型 持续预训练 大语言模型 代码补全
📋 核心要点
- 现有的基于扩散的代码大语言模型在性能上落后于同等规模的自回归模型,限制了扩散模型在代码生成领域的应用。
- Stable-DiffCoder通过块扩散持续预训练(CPT)和定制的训练策略,实现了高效的知识学习和稳定的训练过程。
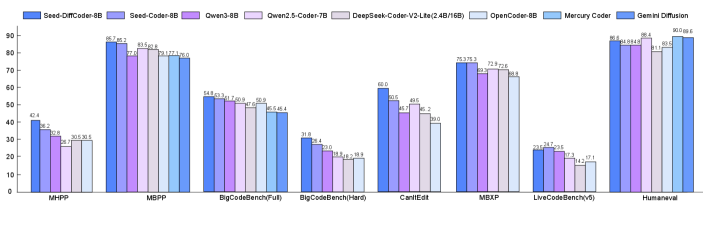
- 实验表明,Stable-DiffCoder在多个代码基准测试中超越了自回归模型,并在低资源语言上表现出优势。
📝 摘要(中文)
本文提出Stable-DiffCoder,一种块扩散代码模型,它复用了Seed-Coder的架构、数据和训练流程。为了实现高效的知识学习和稳定的训练,模型引入了块扩散持续预训练(CPT)阶段,并结合了定制的预热策略和分块裁剪噪声调度。在相同的数据和架构下,Stable-DiffCoder在广泛的代码基准测试中全面优于其自回归(AR)模型。此外,仅依靠CPT和监督微调阶段,Stable-DiffCoder就实现了比一系列约80亿参数的AR和DLLM更强的性能,证明了基于扩散的训练可以提高代码建模质量,超越单独的AR训练。而且,基于扩散的任意顺序建模改进了用于编辑和推理的结构化代码建模,并通过数据增强,有益于低资源编码语言。
🔬 方法详解
问题定义:现有代码扩散语言模型(DLLM)在性能上不如同等规模的自回归(AR)模型。虽然DLLM具有非序列化、分块生成和更丰富的数据重用等优点,但其在代码生成任务中的潜力尚未充分发挥。现有方法的痛点在于训练不稳定,知识学习效率低,导致最终性能受限。
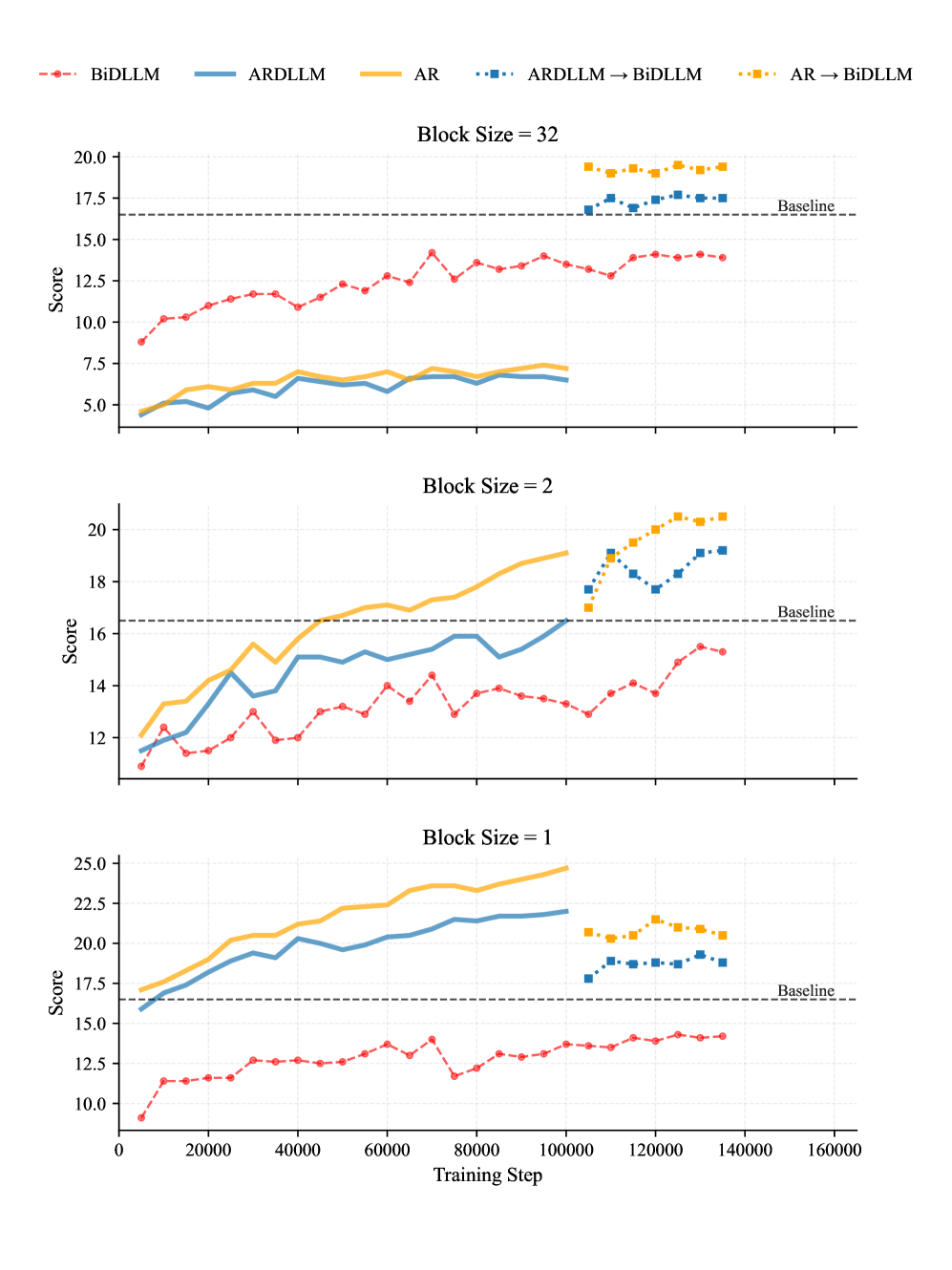
核心思路:本文的核心思路是通过改进训练策略,充分发挥扩散模型在代码建模方面的优势。具体而言,通过引入块扩散持续预训练(CPT)阶段,使模型能够更有效地学习代码的结构和语义信息。同时,定制的预热策略和分块裁剪噪声调度有助于稳定训练过程,避免梯度爆炸或消失等问题。
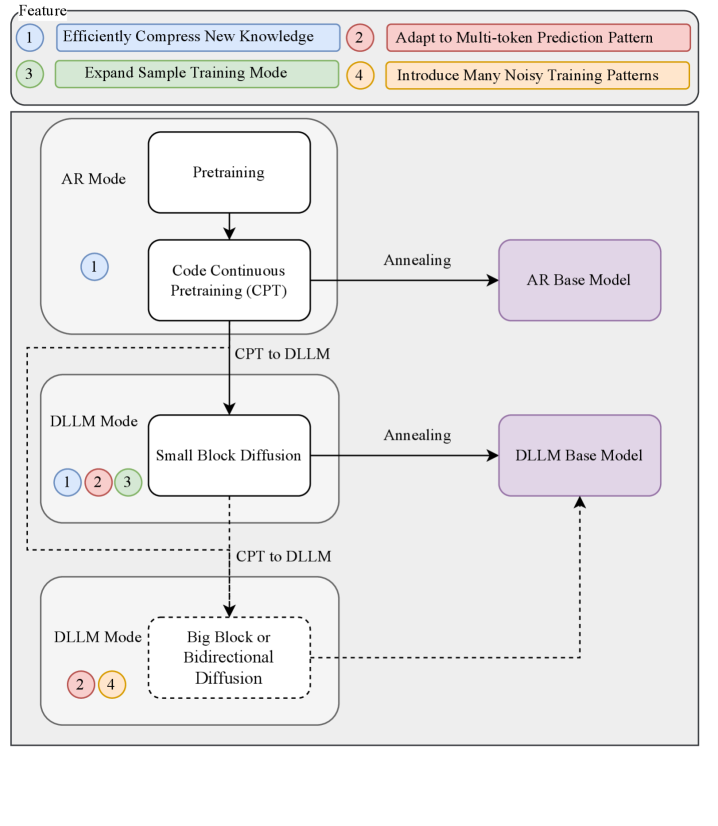
技术框架:Stable-DiffCoder的整体框架包括以下几个主要阶段:1) 数据准备:使用与Seed-Coder相同的数据集进行训练。2) 架构选择:复用Seed-Coder的架构,以便进行公平比较。3) 块扩散持续预训练(CPT):这是本文的核心创新,通过持续预训练,使模型能够逐步学习代码的知识。4) 监督微调:在特定任务上对模型进行微调,以提高其性能。
关键创新:最重要的技术创新点在于块扩散持续预训练(CPT)阶段。与传统的预训练方法不同,CPT采用块扩散的方式,允许模型以非序列化的方式学习代码的结构和语义信息。此外,定制的预热策略和分块裁剪噪声调度也是关键创新,它们有助于稳定训练过程,提高模型的性能。
关键设计:在CPT阶段,采用了定制的预热策略,逐渐增加噪声的幅度,使模型能够逐步适应噪声环境。同时,采用了分块裁剪噪声调度,对不同块的噪声进行裁剪,以避免梯度爆炸或消失。损失函数方面,采用了标准的扩散模型损失函数,并根据具体任务进行了调整。
🖼️ 关键图片
📊 实验亮点
Stable-DiffCoder在多个代码基准测试中超越了其自回归模型,证明了扩散模型在代码建模方面的潜力。具体而言,在HumanEval基准测试中,Stable-DiffCoder的pass@1指标优于其自回归模型。此外,Stable-DiffCoder仅依靠CPT和监督微调阶段,就实现了比一系列约80亿参数的AR和DLLM更强的性能。
🎯 应用场景
Stable-DiffCoder在代码生成、代码补全、代码编辑和代码理解等领域具有广泛的应用前景。它可以用于自动化软件开发、提高开发效率、降低开发成本。此外,该模型还可以应用于低资源编程语言的代码生成,促进这些语言的普及和发展。未来,该模型有望成为智能编程助手的重要组成部分。
📄 摘要(原文)
Diffusion-based language models (DLLMs) offer non-sequential, block-wise generation and richer data reuse compared to autoregressive (AR) models, but existing code DLLMs still lag behind strong AR baselines under comparable budgets. We revisit this setting in a controlled study and introduce Stable-DiffCoder, a block diffusion code model that reuses the Seed-Coder architecture, data, and training pipeline. To enable efficient knowledge learning and stable training, we incorporate a block diffusion continual pretraining (CPT) stage enhanced by a tailored warmup and block-wise clipped noise schedule. Under the same data and architecture, Stable-DiffCoder overall outperforms its AR counterpart on a broad suite of code benchmarks. Moreover, relying only on the CPT and supervised fine-tuning stages, Stable-DiffCoder achieves stronger performance than a wide range of \~8B ARs and DLLMs, demonstrating that diffusion-based training can improve code modeling quality beyond AR training alone. Moreover, diffusion-based any-order modeling improves structured code modeling for editing and reasoning, and through data augmentation, benefits low-resource coding languages.