Evaluating and Achieving Controllable Code Completion in Code LLM
作者: Jiajun Zhang, Zeyu Cui, Lei Zhang, Jian Yang, Jiaxi Yang, Qiang Liu, Zilei Wang, Binyuan Hui, Liang Wang, Junyang Lin
分类: cs.SE, cs.CL
发布日期: 2026-01-22
💡 一句话要点
提出C3-Bench基准测试,并利用数据合成与微调提升代码大模型指令可控的代码补全能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码补全 大型语言模型 指令遵循 基准测试 监督微调 数据合成 代码生成 可控性
📋 核心要点
- 现有代码补全基准主要关注功能正确性,忽略了模型遵循用户指令的能力,这在实际LLM辅助编程中至关重要。
- 论文提出C3-Bench基准,用于评估代码LLM在指令引导下的代码补全能力,并开发数据合成流程进行模型微调。
- 实验表明,开源模型和专有模型在指令遵循能力上存在差距,通过微调得到的Qwen2.5-Coder-C3在C3-Bench上取得了SOTA性能。
📝 摘要(中文)
代码补全已成为核心任务,基于大型语言模型(LLM)的工具在软件工程中备受关注。尽管最近的进展极大地提高了LLM的代码补全能力,但评估方法并未同步发展。目前大多数基准测试仅关注给定上下文中代码补全的功能正确性,忽略了模型在补全过程中遵循用户指令的能力——这在LLM辅助编程中很常见。为了解决这个局限性,我们提出了第一个指令引导的代码补全基准,即可控代码补全基准(C3-Bench),包含2195个精心设计的补全任务。通过对C3-Bench和传统基准测试中40多个主流LLM的全面评估,我们揭示了开源模型和先进专有模型在代码补全任务中指令遵循能力方面的巨大差距。此外,我们开发了一个简单的数据合成流程,利用Qwen2.5-Coder生成高质量的指令-补全对,用于监督微调(SFT)。由此产生的模型Qwen2.5-Coder-C3在C3-Bench上实现了最先进的性能。我们的发现为提高LLM的代码补全和指令遵循能力提供了有价值的见解,为代码LLM的未来研究建立了新的方向。为了方便重现并促进代码LLM的进一步研究,我们开源了所有代码、数据集和模型。
🔬 方法详解
问题定义:现有代码补全评估方法主要关注补全代码的功能正确性,而忽略了模型是否能够遵循用户指令进行补全。在实际应用中,开发者经常会通过自然语言指令来引导代码补全,例如指定代码风格、使用特定库函数等。因此,如何评估和提升代码LLM在指令引导下的代码补全能力是一个重要的问题。现有方法的痛点在于缺乏专门的基准测试和有效的训练方法。
核心思路:论文的核心思路是构建一个专门用于评估指令可控代码补全的基准测试集C3-Bench,并利用该基准测试集生成高质量的指令-补全数据对,用于监督微调代码LLM。通过这种方式,可以提升模型在代码补全过程中遵循用户指令的能力。
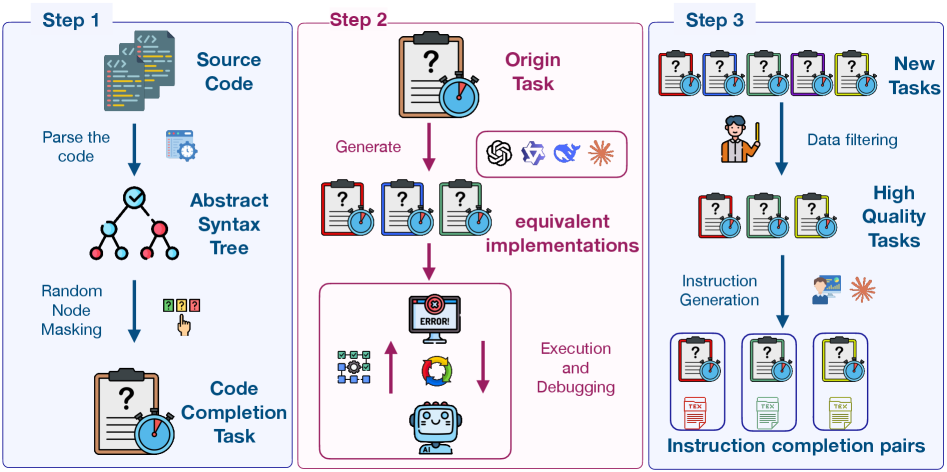
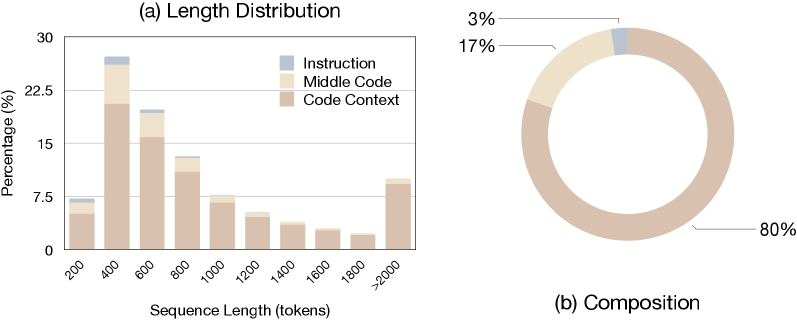
技术框架:整体框架包含两个主要部分:1) C3-Bench基准测试集的构建;2) 基于C3-Bench的数据合成与模型微调。C3-Bench包含2195个精心设计的代码补全任务,每个任务都包含上下文代码和指令。数据合成流程利用Qwen2.5-Coder生成高质量的指令-补全对。然后,使用这些数据对对Qwen2.5-Coder进行监督微调,得到Qwen2.5-Coder-C3模型。
关键创新:论文的关键创新在于提出了C3-Bench基准测试集,这是第一个专门用于评估指令可控代码补全的基准。与现有基准测试相比,C3-Bench更加关注模型在补全过程中遵循用户指令的能力。此外,论文还提出了一个简单有效的数据合成流程,可以生成高质量的指令-补全数据对,用于模型微调。
关键设计:数据合成流程的关键在于利用Qwen2.5-Coder生成高质量的指令-补全对。具体来说,首先从C3-Bench中选择一个任务,然后使用Qwen2.5-Coder生成该任务的补全代码。接下来,将原始指令和生成的补全代码作为训练数据,用于监督微调Qwen2.5-Coder。论文没有详细说明损失函数和网络结构的具体细节,但可以推测使用的是标准的语言模型训练方法。
🖼️ 关键图片

📊 实验亮点
实验结果表明,开源模型和专有模型在C3-Bench上的性能存在显著差距,表明指令遵循能力仍有提升空间。通过C3-Bench数据合成与微调,Qwen2.5-Coder-C3在C3-Bench上取得了SOTA性能,验证了该方法的有效性。具体性能数据未在摘要中给出,需查阅原文。
🎯 应用场景
该研究成果可应用于智能IDE、代码生成工具等领域,提升代码补全的智能化和用户体验。通过指令引导,开发者可以更精确地控制代码补全过程,提高开发效率和代码质量。未来,该技术有望应用于更复杂的代码生成任务,例如根据用户需求自动生成完整的软件模块。
📄 摘要(原文)
Code completion has become a central task, gaining significant attention with the rise of large language model (LLM)-based tools in software engineering. Although recent advances have greatly improved LLMs' code completion abilities, evaluation methods have not advanced equally. Most current benchmarks focus solely on functional correctness of code completions based on given context, overlooking models' ability to follow user instructions during completion-a common scenario in LLM-assisted programming. To address this limitation, we present the first instruction-guided code completion benchmark, Controllable Code Completion Benchmark (C3-Bench), comprising 2,195 carefully designed completion tasks. Through comprehensive evaluation of over 40 mainstream LLMs across C3-Bench and conventional benchmarks, we reveal substantial gaps in instruction-following capabilities between open-source and advanced proprietary models during code completion tasks. Moreover, we develop a straightforward data synthesis pipeline that leverages Qwen2.5-Coder to generate high-quality instruction-completion pairs for supervised fine-tuning (SFT). The resulting model, Qwen2.5-Coder-C3, achieves state-of-the-art performance on C3-Bench. Our findings provide valuable insights for enhancing LLMs' code completion and instruction-following capabilities, establishing new directions for future research in code LLMs. To facilitate reproducibility and foster further research in code LLMs, we open-source all code, datasets, and models.