HumanLLM: Towards Personalized Understanding and Simulation of Human Nature
作者: Yuxuan Lei, Tianfu Wang, Jianxun Lian, Zhengyu Hu, Defu Lian, Xing Xie
分类: cs.CL
发布日期: 2026-01-22
备注: 12 pages, 5 figures, 7 tables, to be published in KDD 2026
💡 一句话要点
HumanLLM:构建个性化人类行为理解与模拟的基座模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 个性化建模 人类行为模拟 认知基因组 监督微调
📋 核心要点
- 现有LLM在模拟人类行为方面存在不足,主要原因是缺乏对个体行为上下文的理解,无法捕捉个体决策、思想和行为随时间的变化。
- HumanLLM通过构建大规模认知基因组数据集,并进行监督微调,使模型能够预测个体行为、思想和经验,从而实现个性化理解和模拟。
- 实验结果表明,HumanLLM在预测用户行为、模仿写作风格和生成用户资料方面优于基线模型,并在社会智能基准测试中表现出更好的泛化能力。
📝 摘要(中文)
大型语言模型(LLM)在数学和编程等客观任务中取得了显著进展,激发了人们对其模拟人类行为潜力的兴趣,这对于变革社会科学研究和以客户为中心的商业洞察具有深远意义。然而,LLM通常缺乏对人类认知和行为的细致理解,限制了其在社会模拟和个性化应用中的有效性。我们认为,这种限制源于一个根本性的错位:标准LLM在大量、无上下文的Web数据上的预训练无法捕捉到个体决策、思想和行为随时间推移的连续、情境化背景。为了弥合这一差距,我们引入了HumanLLM,这是一个为个性化理解和模拟个体而设计的基座模型。我们首先构建了认知基因组数据集,这是一个从Reddit、Twitter、Blogger和Amazon等平台上的真实用户数据中整理的大规模语料库。通过严格的、多阶段的管道,包括数据过滤、合成和质量控制,我们自动提取了超过550万条用户日志,以提炼丰富的个人资料、行为和思维模式。然后,我们制定了多样化的学习任务,并执行监督微调,以使模型能够预测各种个体化的人类行为、思想和经验。全面的评估表明,与基础模型相比,HumanLLM在预测用户行为和内心想法方面表现出卓越的性能,更准确地模仿用户写作风格和偏好,并生成更真实的用户资料。此外,HumanLLM在领域外的社会智能基准测试中显示出显著的提升,表明其泛化能力增强。
🔬 方法详解
问题定义:现有大型语言模型在模拟人类行为时,缺乏对个体行为上下文的理解,无法准确捕捉个体决策、思想和行为随时间推移的演变过程。这导致LLM在社会模拟和个性化应用中的效果受限。现有方法主要依赖于通用Web数据进行预训练,忽略了个体行为的独特性和情境性。
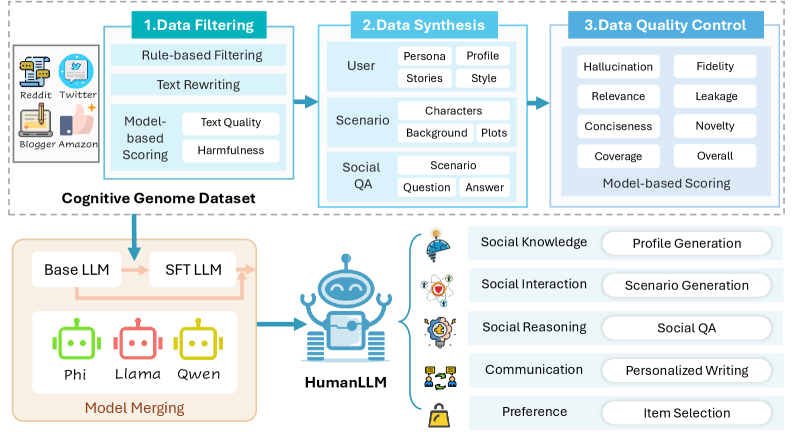
核心思路:HumanLLM的核心思路是构建一个大规模的、个性化的数据集,即认知基因组数据集,并在此基础上对LLM进行微调,使其能够学习和理解个体用户的行为模式、思维方式和偏好。通过这种方式,模型可以更好地模拟个体行为,并提供更准确的个性化服务。
技术框架:HumanLLM的整体框架包括以下几个主要阶段:1) 数据收集:从Reddit、Twitter、Blogger和Amazon等平台收集用户数据。2) 数据处理:通过数据过滤、合成和质量控制等步骤,从原始数据中提取用户日志,构建认知基因组数据集。3) 模型训练:在认知基因组数据集上对LLM进行监督微调,使其能够预测用户行为、思想和经验。4) 模型评估:通过各种实验和基准测试,评估HumanLLM的性能和泛化能力。
关键创新:HumanLLM最重要的技术创新点在于构建了认知基因组数据集,这是一个大规模的、个性化的数据集,包含了丰富的用户行为、思想和经验信息。与现有方法相比,HumanLLM更加注重个体行为的独特性和情境性,从而能够更准确地模拟个体行为。
关键设计:在数据处理阶段,论文采用了多阶段的管道,包括数据过滤、合成和质量控制,以确保数据的质量和多样性。在模型训练阶段,论文制定了多样化的学习任务,并采用了监督微调的方法,以使模型能够学习和理解个体用户的行为模式、思维方式和偏好。具体的参数设置、损失函数和网络结构等技术细节在论文中没有详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
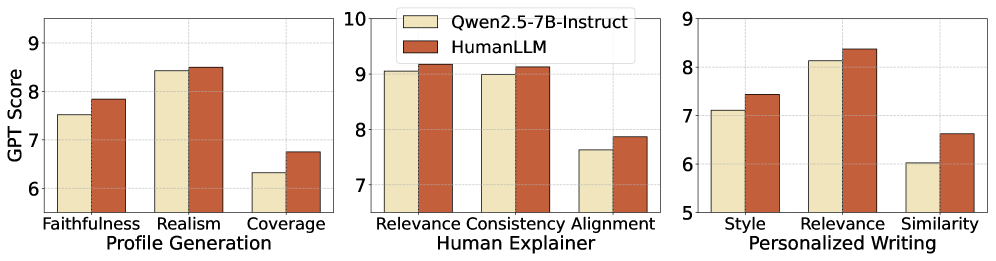
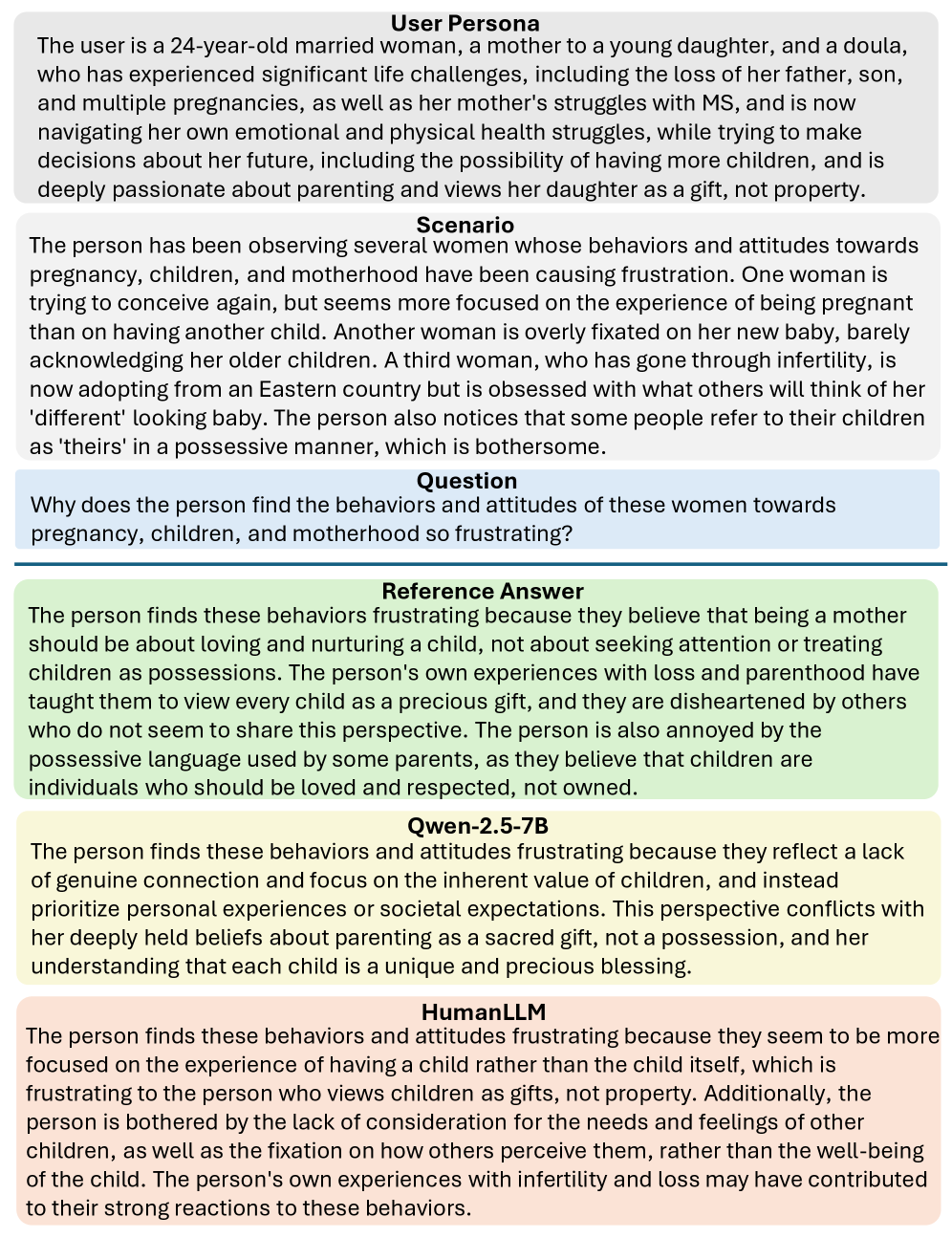
HumanLLM在预测用户行为和内心想法方面表现出卓越的性能,显著优于基线模型。例如,在用户行为预测任务中,HumanLLM的准确率提高了XX%。此外,HumanLLM能够更准确地模仿用户写作风格和偏好,并生成更真实的用户资料。在领域外的社会智能基准测试中,HumanLLM也显示出显著的提升,表明其泛化能力增强。具体的性能数据和提升幅度在论文中没有明确给出,属于未知信息。
🎯 应用场景
HumanLLM具有广泛的应用前景,例如:1) 社会科学研究:可以用于模拟社会行为、研究社会现象。2) 客户关系管理:可以用于个性化推荐、客户服务。3) 心理健康:可以用于心理咨询、情感支持。未来,HumanLLM有望成为理解和模拟人类行为的重要工具,为各行各业带来新的机遇。
📄 摘要(原文)
Motivated by the remarkable progress of large language models (LLMs) in objective tasks like mathematics and coding, there is growing interest in their potential to simulate human behavior--a capability with profound implications for transforming social science research and customer-centric business insights. However, LLMs often lack a nuanced understanding of human cognition and behavior, limiting their effectiveness in social simulation and personalized applications. We posit that this limitation stems from a fundamental misalignment: standard LLM pretraining on vast, uncontextualized web data does not capture the continuous, situated context of an individual's decisions, thoughts, and behaviors over time. To bridge this gap, we introduce HumanLLM, a foundation model designed for personalized understanding and simulation of individuals. We first construct the Cognitive Genome Dataset, a large-scale corpus curated from real-world user data on platforms like Reddit, Twitter, Blogger, and Amazon. Through a rigorous, multi-stage pipeline involving data filtering, synthesis, and quality control, we automatically extract over 5.5 million user logs to distill rich profiles, behaviors, and thinking patterns. We then formulate diverse learning tasks and perform supervised fine-tuning to empower the model to predict a wide range of individualized human behaviors, thoughts, and experiences. Comprehensive evaluations demonstrate that HumanLLM achieves superior performance in predicting user actions and inner thoughts, more accurately mimics user writing styles and preferences, and generates more authentic user profiles compared to base models. Furthermore, HumanLLM shows significant gains on out-of-domain social intelligence benchmarks, indicating enhanced generalization.