Towards Reliable Medical LLMs: Benchmarking and Enhancing Confidence Estimation of Large Language Models in Medical Consultation
作者: Zhiyao Ren, Yibing Zhan, Siyuan Liang, Guozheng Ma, Baosheng Yu, Dacheng Tao
分类: cs.CL
发布日期: 2026-01-22
💡 一句话要点
提出MedConf框架,提升医学LLM在多轮诊疗中置信度评估的可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学LLM 置信度评估 多轮诊疗 信息充分性 检索增强生成
📋 核心要点
- 现有医学LLM置信度评估忽略了多轮交互中证据积累对置信度的影响,导致评估结果与实际诊疗场景脱节。
- MedConf框架通过检索增强生成构建症状概况,并结合支持、缺失和矛盾关系进行加权集成,实现可解释的置信度估计。
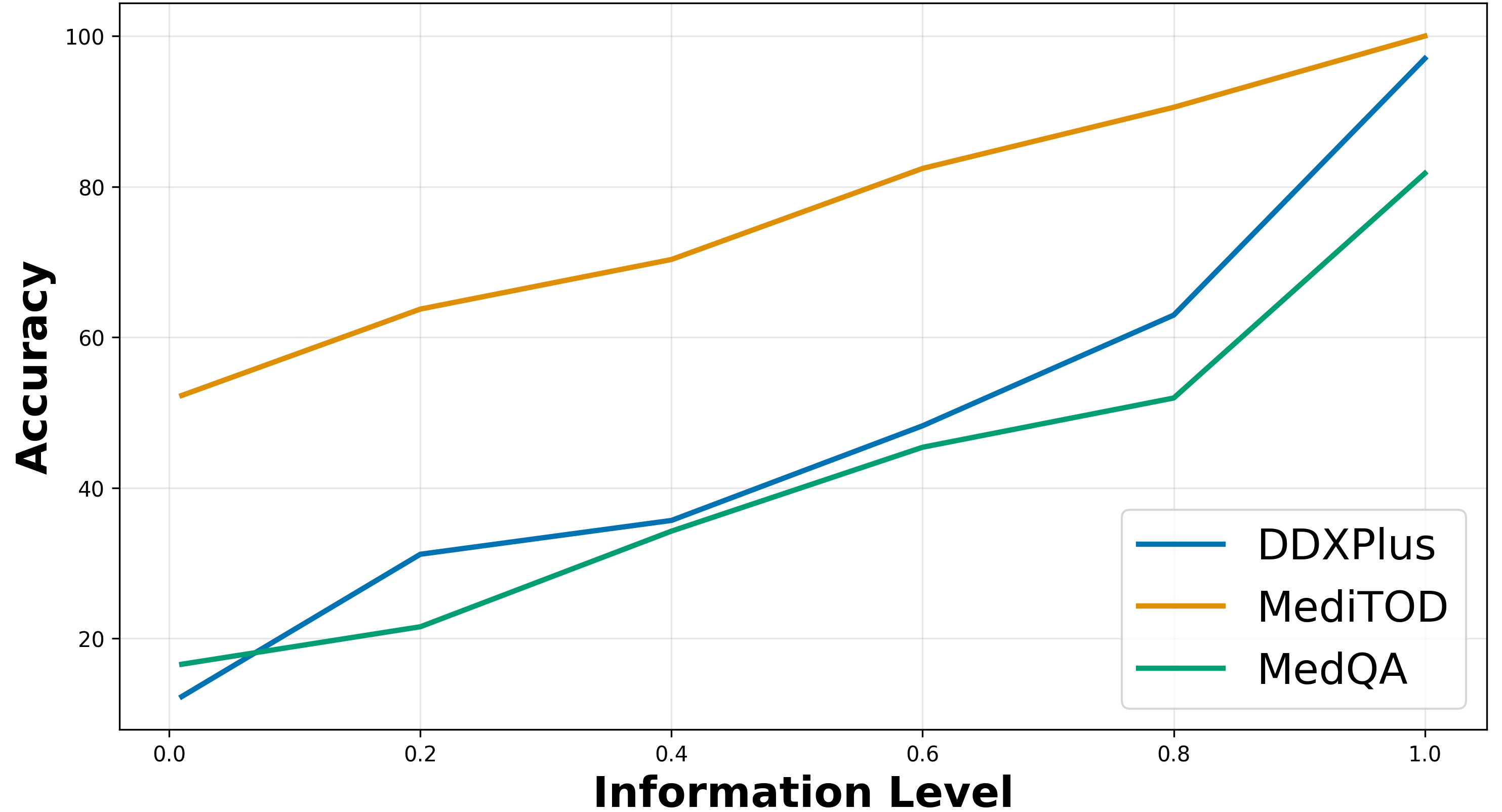
- 实验表明,MedConf在多个医学数据集上显著优于现有方法,尤其在信息不足和多病共存情况下表现稳定。
📝 摘要(中文)
大型语言模型(LLM)常常基于不完整的信息提供临床判断,增加了误诊的风险。现有研究主要评估单轮、静态设置下的置信度,忽略了真实会诊中置信度与正确性随临床证据积累的耦合关系,限制了其对可靠决策的支持。本文提出了首个用于评估真实医学会诊中多轮交互置信度的基准。该基准统一了三种医学数据用于开放式诊断生成,并引入了信息充分性梯度来表征证据增加时置信度-正确性的动态变化。在基准上实施并比较了27种代表性方法,揭示了两个关键见解:(1)医学数据放大了token级别和一致性级别置信度方法的固有局限性;(2)医学推理必须评估诊断准确性和信息完整性。基于这些见解,本文提出了MedConf,一个基于证据的语言自我评估框架,通过检索增强生成构建症状概况,将患者信息与支持、缺失和矛盾关系对齐,并通过加权集成将它们聚合为可解释的置信度估计。在两个LLM和三个医学数据集上,MedConf在AUROC和Pearson相关系数指标上始终优于最先进的方法,并在信息不足和多病共存的条件下保持稳定的性能。这些结果表明,信息充分性是可信医学置信度建模的关键决定因素,为构建更可靠和可解释的大型医学模型提供了一条新途径。
🔬 方法详解
问题定义:现有医学LLM的置信度评估方法主要集中在单轮静态场景,无法有效捕捉真实多轮诊疗过程中,随着信息逐渐积累,置信度与诊断正确性之间的动态变化关系。这导致现有方法在评估LLM在实际临床应用中的可靠性方面存在局限性,容易导致误诊风险。
核心思路:MedConf的核心思路是基于证据充分性进行置信度评估。它认为,一个可靠的医学LLM应该能够根据当前掌握的患者信息量,准确评估其诊断结果的置信度。当信息不足时,置信度应该较低;随着信息的增加,置信度应该相应提高。因此,MedConf通过分析LLM生成的诊断结果与已知的患者信息之间的关系,来判断信息是否充分,从而给出合理的置信度估计。
技术框架:MedConf框架主要包含以下几个模块:1) 症状概况构建:利用检索增强生成技术,从医学知识库中检索与当前患者信息相关的症状描述,构建症状概况。2) 关系对齐:将患者信息与症状概况进行对齐,识别患者信息与症状之间的支持、缺失和矛盾关系。3) 置信度聚合:根据支持、缺失和矛盾关系的权重,将这些关系聚合为一个可解释的置信度估计。
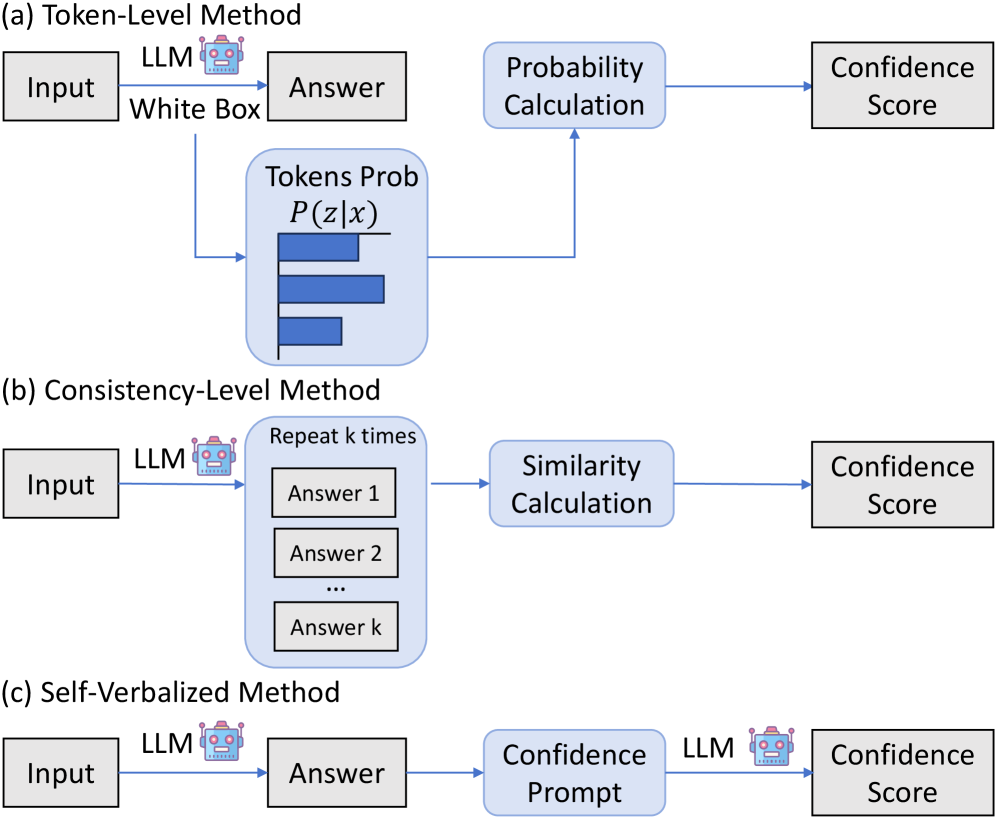
关键创新:MedConf的关键创新在于其基于证据充分性的置信度评估方法。与传统的token级别或一致性级别的置信度评估方法不同,MedConf关注的是诊断结果与患者信息之间的关系,能够更准确地反映LLM在实际临床应用中的可靠性。此外,MedConf还引入了可解释的置信度估计,使得医生能够更好地理解LLM的诊断依据,从而做出更明智的决策。
关键设计:在症状概况构建阶段,使用了检索增强生成模型,以提高检索的准确性和覆盖率。在关系对齐阶段,定义了支持、缺失和矛盾三种关系,并设计了相应的算法进行识别。在置信度聚合阶段,使用了加权集成方法,根据不同关系的权重,将它们聚合为一个置信度估计。权重的设置可以根据具体的应用场景进行调整。
🖼️ 关键图片

📊 实验亮点
MedConf在两个LLM和三个医学数据集上进行了评估,结果表明,MedConf在AUROC和Pearson相关系数指标上始终优于最先进的方法。尤其是在信息不足和多病共存的条件下,MedConf能够保持稳定的性能,证明了其在复杂临床场景下的有效性。例如,在某个数据集上,MedConf的AUROC比最佳基线提高了超过5%。
🎯 应用场景
MedConf框架可应用于辅助医生进行诊断决策,尤其是在信息不完整或患者存在多重疾病的情况下。通过提供可靠的置信度评估,MedConf可以帮助医生识别潜在的误诊风险,并做出更明智的治疗方案。未来,该框架有望集成到临床决策支持系统中,提高医疗服务的质量和效率。
📄 摘要(原文)
Large-scale language models (LLMs) often offer clinical judgments based on incomplete information, increasing the risk of misdiagnosis. Existing studies have primarily evaluated confidence in single-turn, static settings, overlooking the coupling between confidence and correctness as clinical evidence accumulates during real consultations, which limits their support for reliable decision-making. We propose the first benchmark for assessing confidence in multi-turn interaction during realistic medical consultations. Our benchmark unifies three types of medical data for open-ended diagnostic generation and introduces an information sufficiency gradient to characterize the confidence-correctness dynamics as evidence increases. We implement and compare 27 representative methods on this benchmark; two key insights emerge: (1) medical data amplifies the inherent limitations of token-level and consistency-level confidence methods, and (2) medical reasoning must be evaluated for both diagnostic accuracy and information completeness. Based on these insights, we present MedConf, an evidence-grounded linguistic self-assessment framework that constructs symptom profiles via retrieval-augmented generation, aligns patient information with supporting, missing, and contradictory relations, and aggregates them into an interpretable confidence estimate through weighted integration. Across two LLMs and three medical datasets, MedConf consistently outperforms state-of-the-art methods on both AUROC and Pearson correlation coefficient metrics, maintaining stable performance under conditions of information insufficiency and multimorbidity. These results demonstrate that information adequacy is a key determinant of credible medical confidence modeling, providing a new pathway toward building more reliable and interpretable large medical models.