YuFeng-XGuard: A Reasoning-Centric, Interpretable, and Flexible Guardrail Model for Large Language Models
作者: Junyu Lin, Meizhen Liu, Xiufeng Huang, Jinfeng Li, Haiwen Hong, Xiaohan Yuan, Yuefeng Chen, Longtao Huang, Hui Xue, Ranjie Duan, Zhikai Chen, Yuchuan Fu, Defeng Li, Lingyao Gao, Yitong Yang
分类: cs.CL
发布日期: 2026-01-22
💡 一句话要点
提出YuFeng-XGuard,一个以推理为中心、可解释且灵活的LLM安全防护模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型安全 安全防护 可解释性 风险评估 推理 动态策略 分层推理
📋 核心要点
- 现有LLM安全防护方法依赖快速分类或后验规则,缺乏透明性、灵活性和效率。
- YuFeng-XGuard通过结构化风险预测和自然语言解释,实现可解释的多维风险感知。
- 实验表明,YuFeng-XGuard在多个安全基准上实现了最先进的性能,并开源了不同容量的版本。
📝 摘要(中文)
随着大型语言模型(LLMs)在现实世界应用中日益普及,安全防护措施需要超越粗粒度的过滤,并支持细粒度、可解释和可适应的风险评估。然而,现有的解决方案通常依赖于快速分类方案或事后规则,导致透明度有限、策略不灵活或推理成本过高。为此,我们提出了YuFeng-XGuard,一个以推理为中心的安全防护模型系列,旨在对LLM交互执行多维风险感知。YuFeng-XGuard不产生不透明的二元判断,而是生成结构化的风险预测,包括明确的风险类别和可配置的置信度分数,并附带自然语言解释,从而揭示潜在的推理过程。这种形式使得安全决策既可操作又可解释。为了平衡决策延迟和解释深度,我们采用了一种分层推理范式,该范式基于第一个解码的token执行初始风险决策,同时在需要时保留按需解释推理。此外,我们引入了一种动态策略机制,将风险感知与策略执行分离,从而允许在不重新训练模型的情况下调整安全策略。在各种公共安全基准上的大量实验表明,YuFeng-XGuard在保持强大的效率-效力权衡的同时,实现了最先进的性能。我们将YuFeng-XGuard作为一个开放模型系列发布,包括一个全容量变体和一个轻量级版本,以支持广泛的部署场景。
🔬 方法详解
问题定义:现有的大型语言模型安全防护方法通常采用粗粒度的过滤或基于规则的后处理,缺乏细粒度的风险评估能力,难以提供可解释的决策依据,并且策略调整需要重新训练模型,灵活性不足。这些方法在实际应用中难以应对复杂多变的风险场景。
核心思路:YuFeng-XGuard的核心思路是以推理为中心,通过让模型生成结构化的风险预测和自然语言解释,提高安全决策的透明度和可解释性。同时,采用分层推理和动态策略机制,在保证决策效率的同时,实现策略的灵活调整,无需重新训练模型。
技术框架:YuFeng-XGuard采用分层推理范式,首先基于第一个解码的token进行快速风险判断,如果需要更深入的分析,则进行完整的推理过程,生成包含风险类别、置信度分数和自然语言解释的结构化风险预测。此外,引入动态策略机制,将风险感知与策略执行分离,允许在不重新训练模型的情况下调整安全策略。
关键创新:YuFeng-XGuard的关键创新在于其以推理为中心的设计,通过生成结构化的风险预测和自然语言解释,实现了可解释的安全决策。此外,动态策略机制的引入,使得安全策略的调整更加灵活,无需重新训练模型。这种设计与现有方法中依赖快速分类或后处理规则的方式有着本质区别。
关键设计:YuFeng-XGuard的具体实现细节未知,论文中没有详细描述关键参数设置、损失函数或网络结构等技术细节。但可以推测,模型可能采用了某种形式的注意力机制或Transformer结构,以便进行推理和生成自然语言解释。动态策略机制的具体实现方式也未知,可能涉及到某种形式的规则引擎或策略配置系统。
🖼️ 关键图片
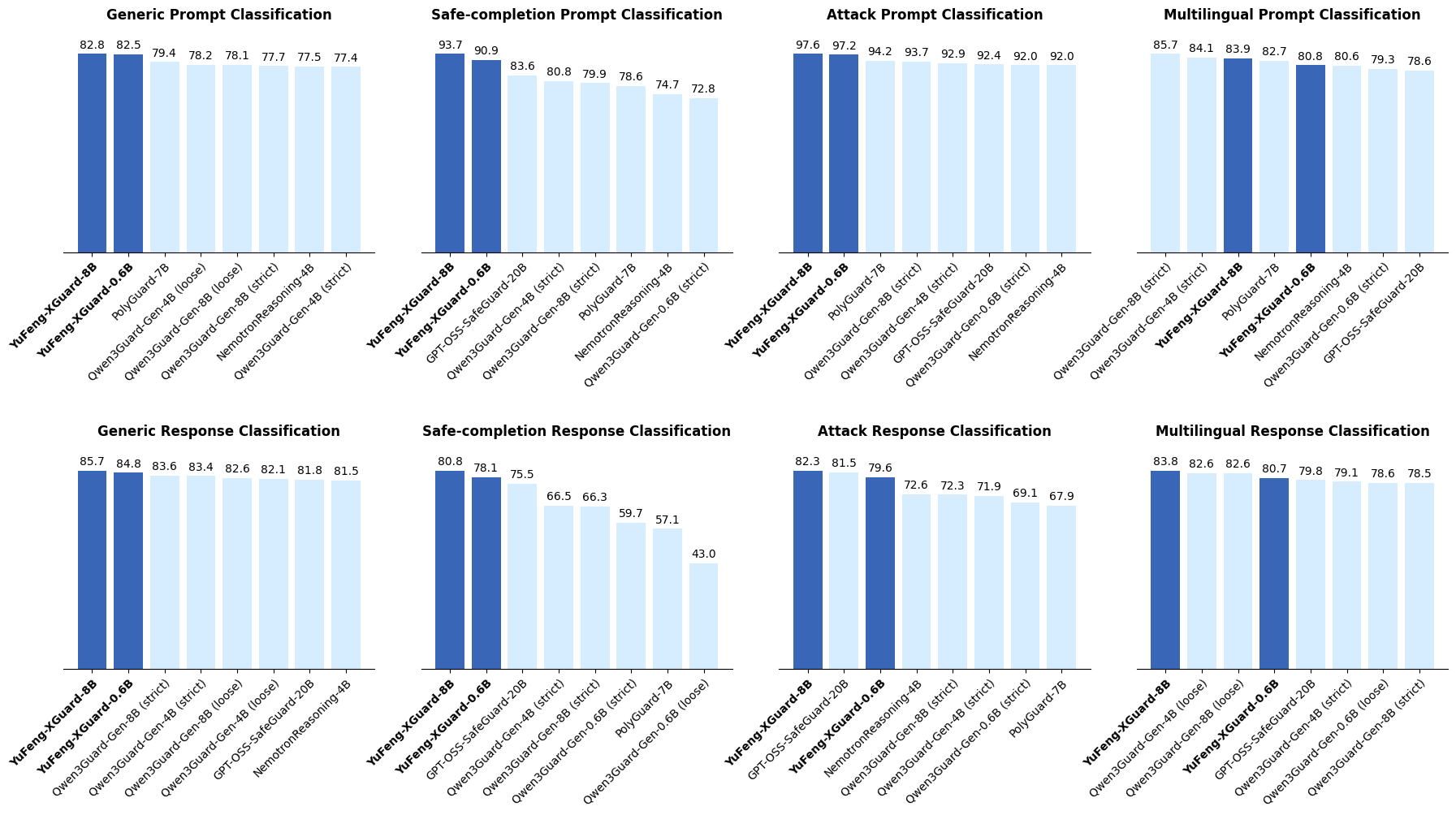

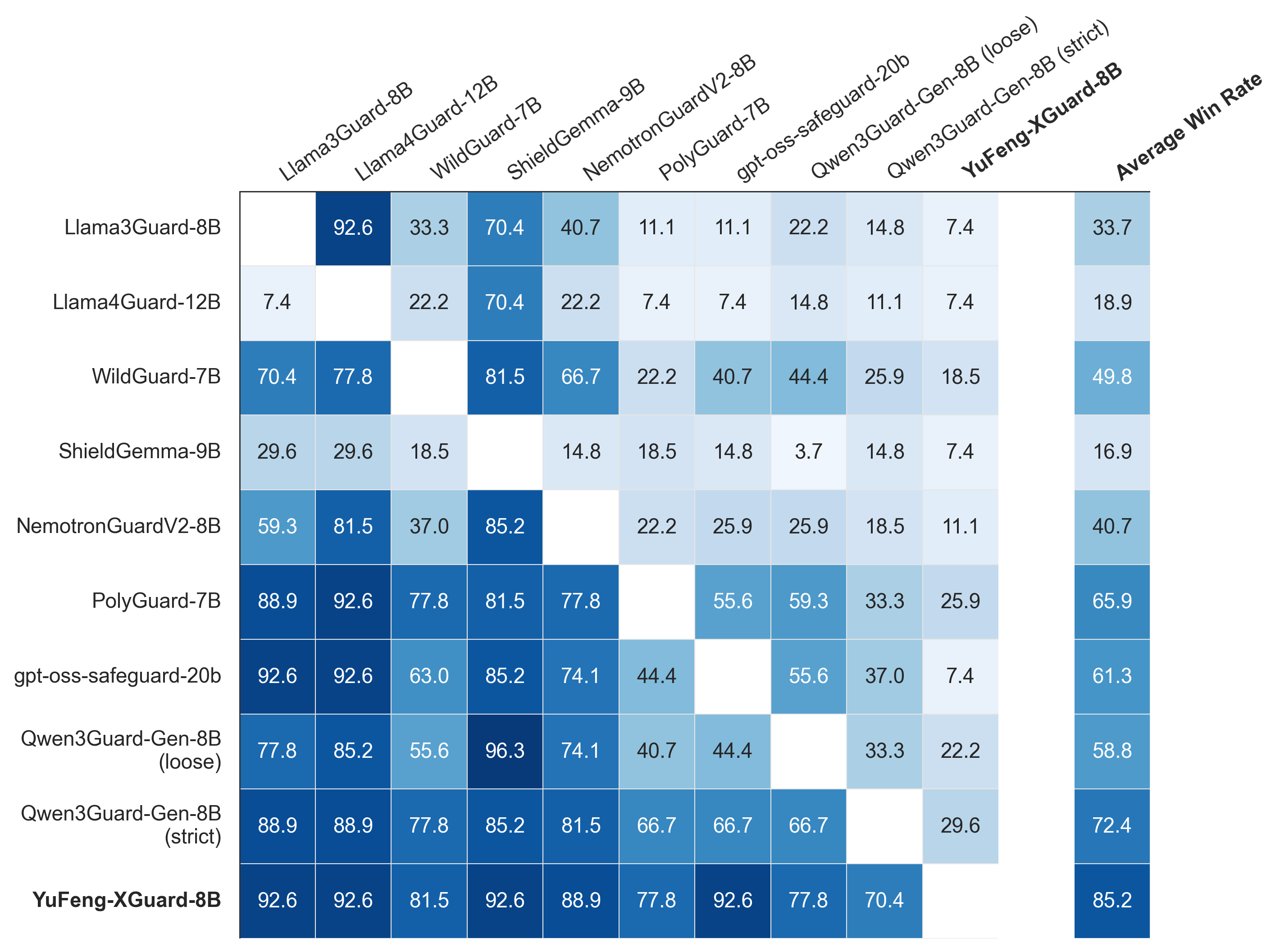
📊 实验亮点
YuFeng-XGuard在多个公共安全基准测试中取得了最先进的性能,证明了其有效性。同时,该模型在效率和效力之间取得了良好的平衡,能够在保证安全性的前提下,尽可能地降低推理延迟。此外,作者开源了YuFeng-XGuard模型系列,包括全容量版本和轻量级版本,方便研究人员和开发者使用。
🎯 应用场景
YuFeng-XGuard可应用于各种需要安全防护的大型语言模型应用场景,例如智能客服、内容生成、代码生成等。其可解释性和灵活性使其能够更好地适应不同场景下的安全需求,降低LLM被恶意利用的风险,提升用户信任度。未来,该模型可以进一步扩展到更多模态,例如图像和语音,以实现更全面的安全防护。
📄 摘要(原文)
As large language models (LLMs) are increasingly deployed in real-world applications, safety guardrails are required to go beyond coarse-grained filtering and support fine-grained, interpretable, and adaptable risk assessment. However, existing solutions often rely on rapid classification schemes or post-hoc rules, resulting in limited transparency, inflexible policies, or prohibitive inference costs. To this end, we present YuFeng-XGuard, a reasoning-centric guardrail model family designed to perform multi-dimensional risk perception for LLM interactions. Instead of producing opaque binary judgments, YuFeng-XGuard generates structured risk predictions, including explicit risk categories and configurable confidence scores, accompanied by natural language explanations that expose the underlying reasoning process. This formulation enables safety decisions that are both actionable and interpretable. To balance decision latency and explanatory depth, we adopt a tiered inference paradigm that performs an initial risk decision based on the first decoded token, while preserving ondemand explanatory reasoning when required. In addition, we introduce a dynamic policy mechanism that decouples risk perception from policy enforcement, allowing safety policies to be adjusted without model retraining. Extensive experiments on a diverse set of public safety benchmarks demonstrate that YuFeng-XGuard achieves stateof-the-art performance while maintaining strong efficiency-efficacy trade-offs. We release YuFeng-XGuard as an open model family, including both a full-capacity variant and a lightweight version, to support a wide range of deployment scenarios.