Robust Fake News Detection using Large Language Models under Adversarial Sentiment Attacks
作者: Sahar Tahmasebi, Eric Müller-Budack, Ralph Ewerth
分类: cs.CL
发布日期: 2026-01-21
💡 一句话要点
提出AdSent框架,解决大型语言模型对抗性情感攻击下的假新闻稳健检测问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 假新闻检测 对抗攻击 情感分析 大型语言模型 鲁棒性 情感无关训练 自然语言处理
📋 核心要点
- 现有假新闻检测方法易受情感操纵攻击,攻击者可利用大型语言模型生成对抗样本,改变新闻情感以逃避检测。
- AdSent框架通过情感无关的训练策略,使模型对新闻情感变化不敏感,从而提高在对抗性攻击下的鲁棒性。
- 实验表明,AdSent在多个数据集上显著提升了假新闻检测的准确性和鲁棒性,并能有效泛化到新的数据集。
📝 摘要(中文)
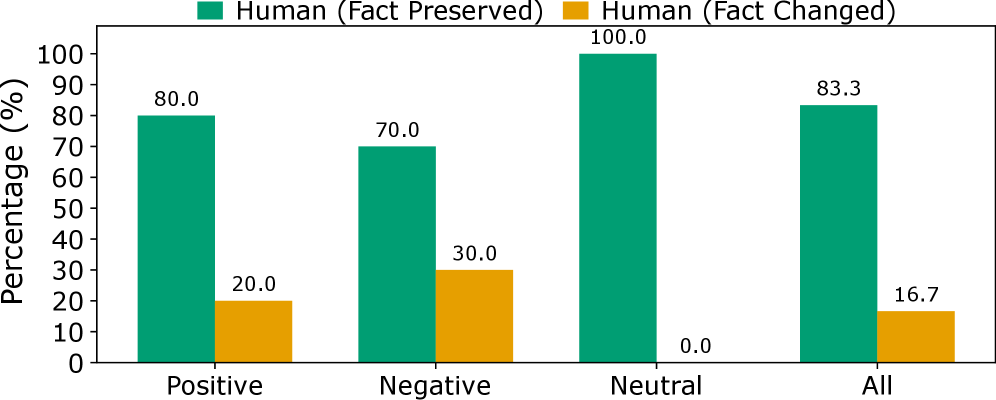
虚假信息和假新闻已成为紧迫的社会挑战,需要可靠的自动化检测方法。以往研究强调情感是假新闻检测的重要信号,通过分析与假新闻相关的情感或使用情感特征进行分类。然而,这存在漏洞,因为攻击者可以利用情感来逃避检测,尤其是在大型语言模型(LLM)出现之后。少数研究探索了LLM生成的对抗样本,但主要关注新闻出版商写作风格等文体特征。因此,情感操纵的关键漏洞在很大程度上未被探索。本文研究了最先进的假新闻检测器在情感操纵下的鲁棒性。我们引入了AdSent,一种情感鲁棒的检测框架,旨在确保原始和情感改变的新闻文章之间预测结果的一致性。具体来说,我们(1)提出了使用LLM进行受控的基于情感的对抗性攻击,(2)分析了情感变化对检测性能的影响。结果表明,改变情感会严重影响假新闻检测模型的性能,表明模型偏向于将中性文章视为真实,而非中性文章通常被归类为虚假内容。(3)我们引入了一种新颖的情感无关训练策略,以增强对此类扰动的鲁棒性。在三个基准数据集上的大量实验表明,AdSent在准确性和鲁棒性方面均优于竞争基线,同时还能有效地推广到未见过的数据集和对抗性场景。
🔬 方法详解
问题定义:现有假新闻检测方法依赖于新闻文本的情感特征,这使得它们容易受到对抗性攻击。攻击者可以利用大型语言模型(LLM)生成对抗样本,通过改变新闻文本的情感倾向来误导检测模型,导致其性能显著下降。现有研究主要关注文体特征的对抗攻击,而忽略了情感操纵这一关键漏洞。
核心思路:AdSent的核心思路是使假新闻检测模型对新闻文本的情感变化保持不敏感,从而提高其在对抗性攻击下的鲁棒性。通过情感无关的训练策略,模型能够学习到与情感无关的、更本质的假新闻特征,从而避免被情感操纵所迷惑。
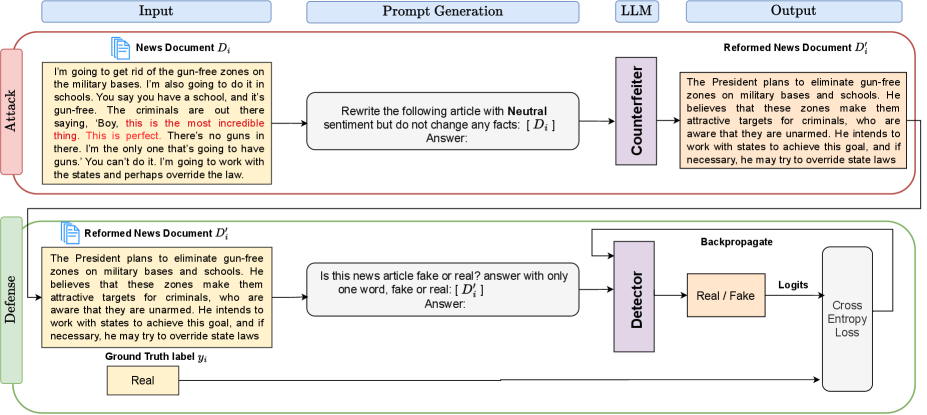
技术框架:AdSent框架包含三个主要组成部分:1) 基于LLM的受控情感对抗样本生成器,用于生成具有不同情感倾向的对抗样本;2) 假新闻检测模型,用于对原始新闻文本和对抗样本进行分类;3) 情感无关训练模块,用于训练鲁棒的假新闻检测模型。整体流程是,首先利用对抗样本生成器生成不同情感倾向的对抗样本,然后将原始新闻文本和对抗样本输入到假新闻检测模型中进行训练,最后通过情感无关训练模块优化模型参数,使其对情感变化不敏感。
关键创新:AdSent的关键创新在于其情感无关训练策略。该策略通过引入对抗训练和数据增强等技术,使模型能够学习到与情感无关的、更本质的假新闻特征。与现有方法相比,AdSent能够更有效地抵抗情感操纵攻击,提高假新闻检测的鲁棒性。
关键设计:AdSent的关键设计包括:1) 使用Prompt工程控制LLM生成对抗样本的情感强度和方向;2) 设计情感无关损失函数,鼓励模型学习与情感无关的特征;3) 采用数据增强技术,生成更多样化的训练样本,提高模型的泛化能力。具体的损失函数和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AdSent在三个基准数据集上显著优于现有的假新闻检测方法。在对抗性攻击下,AdSent的准确率提升了10%-20%,鲁棒性得到了显著增强。此外,AdSent还能够有效地泛化到未见过的数据集和对抗性场景,表明其具有良好的实用价值。
🎯 应用场景
AdSent框架可应用于各种在线新闻平台和社交媒体平台,用于提高假新闻检测的准确性和鲁棒性。该研究成果有助于构建更可靠的信息环境,减少虚假信息对社会的影响。未来,该框架可以扩展到其他类型的文本分类任务,例如垃圾邮件检测和恶意评论过滤。
📄 摘要(原文)
Misinformation and fake news have become a pressing societal challenge, driving the need for reliable automated detection methods. Prior research has highlighted sentiment as an important signal in fake news detection, either by analyzing which sentiments are associated with fake news or by using sentiment and emotion features for classification. However, this poses a vulnerability since adversaries can manipulate sentiment to evade detectors especially with the advent of large language models (LLMs). A few studies have explored adversarial samples generated by LLMs, but they mainly focus on stylistic features such as writing style of news publishers. Thus, the crucial vulnerability of sentiment manipulation remains largely unexplored. In this paper, we investigate the robustness of state-of-the-art fake news detectors under sentiment manipulation. We introduce AdSent, a sentiment-robust detection framework designed to ensure consistent veracity predictions across both original and sentiment-altered news articles. Specifically, we (1) propose controlled sentiment-based adversarial attacks using LLMs, (2) analyze the impact of sentiment shifts on detection performance. We show that changing the sentiment heavily impacts the performance of fake news detection models, indicating biases towards neutral articles being real, while non-neutral articles are often classified as fake content. (3) We introduce a novel sentiment-agnostic training strategy that enhances robustness against such perturbations. Extensive experiments on three benchmark datasets demonstrate that AdSent significantly outperforms competitive baselines in both accuracy and robustness, while also generalizing effectively to unseen datasets and adversarial scenarios.