Taxonomy-Aligned Risk Extraction from 10-K Filings with Autonomous Improvement Using LLMs
作者: Rian Dolphin, Joe Dursun, Jarrett Blankenship, Katie Adams, Quinton Pike
分类: cs.CL
发布日期: 2026-01-21
备注: 4 figures, 9 pages
💡 一句话要点
提出一种基于LLM的企业10-K文件中风险因素的分类提取与自主改进方法。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 风险提取 大型语言模型 分类体系对齐 自主学习 金融风险管理
📋 核心要点
- 现有方法难以从非结构化文本中提取符合预定义分类体系的风险因素,且缺乏自动维护和改进分类体系的能力。
- 该方法结合LLM提取、语义映射和LLM判断,实现风险因素的结构化提取,并引入AI代理进行自主分类体系维护。
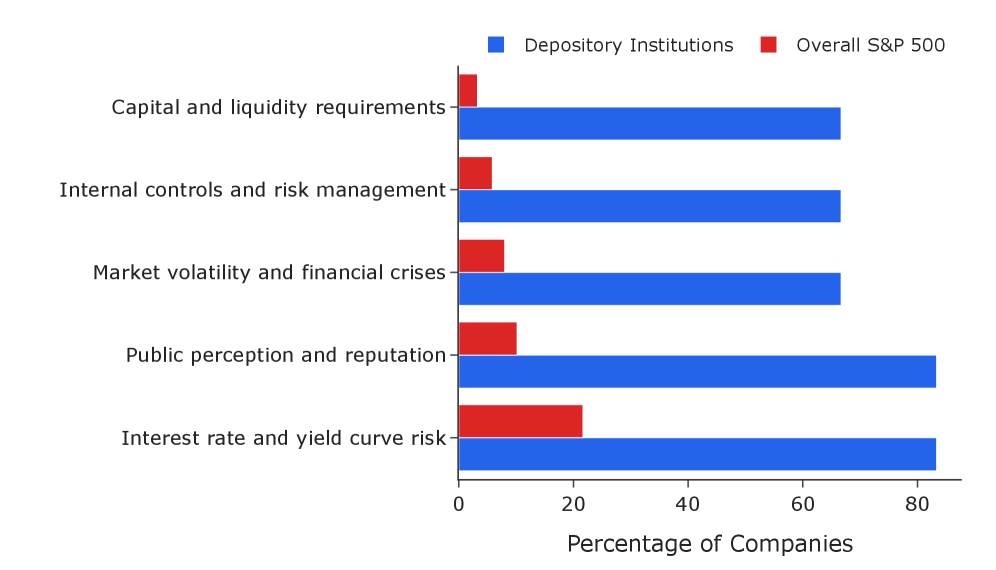
- 实验表明,该方法能有效提取风险因素,提升分类体系质量,并捕捉到行业间风险概况的经济意义结构。
📝 摘要(中文)
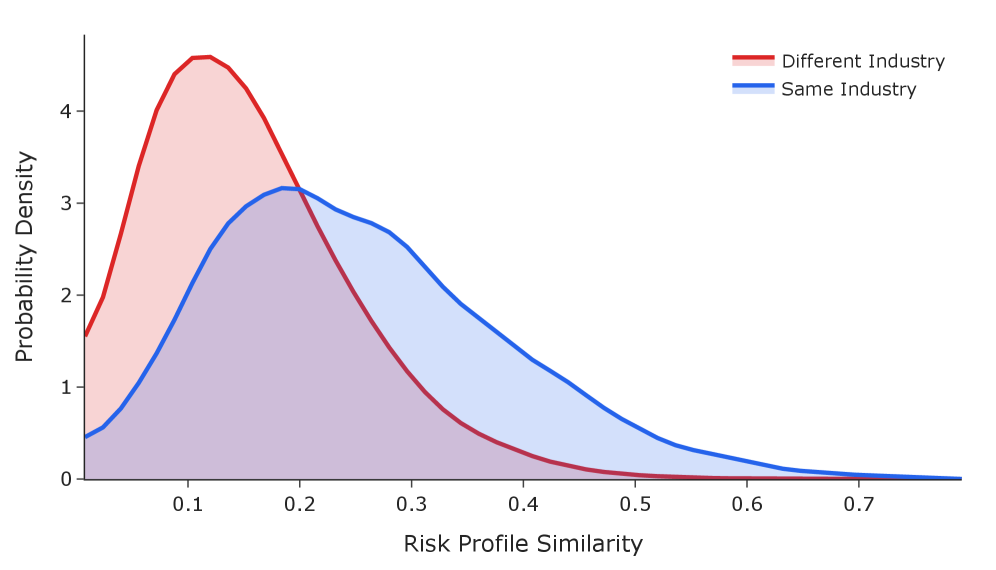
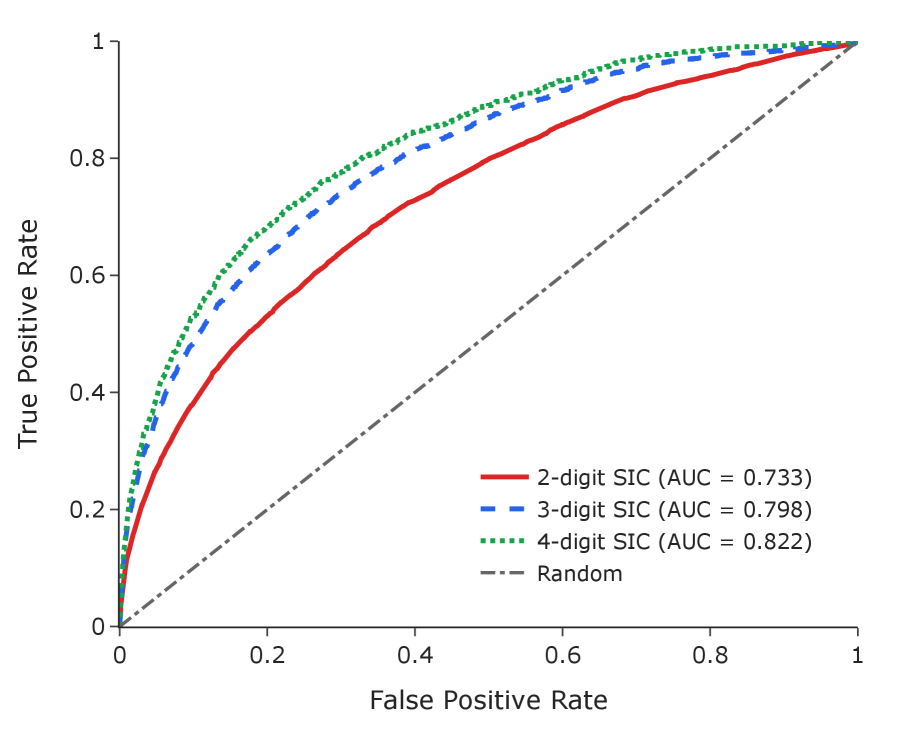
本文提出了一种从公司10-K文件中提取结构化风险因素的方法,同时保持与预定义的层级分类体系的一致性。该方法采用三阶段流程:首先,利用LLM提取风险因素并附带支持性引用;其次,基于嵌入的语义映射将风险因素分配到分类体系类别;最后,使用LLM作为判断器来验证并过滤掉错误的分配。为了评估该方法,我们从标准普尔500指数公司中提取了10688个风险因素,并研究了行业集群之间的风险概况相似性。此外,我们引入了自主分类体系维护,其中AI代理分析评估反馈以识别有问题的类别,诊断失败模式,并提出改进建议,在一个案例研究中实现了嵌入分离度104.7%的提升。外部验证证实该分类体系捕捉到了具有经济意义的结构:同一行业的公司表现出比跨行业公司高63%的风险概况相似性(Cohen's d=1.06,AUC 0.82,p<0.001)。该方法可推广到任何需要从非结构化文本中进行分类体系对齐提取的领域,并且自主改进功能能够随着系统处理更多文档而持续维护和增强质量。
🔬 方法详解
问题定义:该论文旨在解决从公司10-K文件中提取结构化风险因素,并使其与预定义的层级分类体系对齐的问题。现有方法通常依赖于人工标注或简单的关键词匹配,难以处理文本的复杂性和语义信息,导致提取结果不准确,且无法自动适应新的风险类型或行业变化。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大文本理解和生成能力,结合语义映射和LLM判断,实现风险因素的自动提取和分类。此外,引入AI代理进行自主分类体系维护,通过分析评估反馈,识别问题类别并提出改进建议,实现分类体系的持续优化。
技术框架:该方法包含三个主要阶段:1) LLM提取:使用LLM从10-K文件中提取风险因素,并附带支持性引用。2) 语义映射:基于嵌入的语义相似度,将提取的风险因素映射到预定义的分类体系类别。3) LLM判断:使用LLM作为判断器,验证风险因素的分类结果,并过滤掉错误的分配。此外,还包含一个自主分类体系维护模块,使用AI代理分析评估反馈,诊断失败模式,并提出改进建议。
关键创新:该论文的关键创新在于将LLM应用于风险因素的提取、分类和验证,并引入AI代理进行自主分类体系维护。与传统方法相比,该方法能够更准确地提取风险因素,并自动适应新的风险类型和行业变化。自主分类体系维护模块能够持续优化分类体系,提高提取和分类的准确性。
关键设计:在LLM提取阶段,使用了提示工程(prompt engineering)来指导LLM提取风险因素和支持性引用。在语义映射阶段,使用了预训练的词嵌入模型(如Word2Vec、GloVe或Transformer模型)来计算风险因素和分类体系类别之间的语义相似度。在LLM判断阶段,使用了微调的LLM来判断风险因素的分类结果是否合理。自主分类体系维护模块使用了强化学习或进化算法来优化AI代理的策略,使其能够有效地识别问题类别并提出改进建议。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法能够有效提取风险因素,并提升分类体系质量。在一个案例研究中,自主分类体系维护实现了嵌入分离度104.7%的提升。外部验证证实,同一行业的公司表现出比跨行业公司高63%的风险概况相似性(Cohen's d=1.06,AUC 0.82,p<0.001),表明该分类体系捕捉到了具有经济意义的结构。
🎯 应用场景
该研究可应用于金融风险管理、投资决策、监管合规等领域。通过自动提取和分析公司财务报告中的风险因素,可以帮助投资者更好地评估投资风险,监管机构更好地监控市场风险,企业更好地管理自身风险。该方法还可推广到其他领域,如医疗、法律等,实现从非结构化文本中进行分类体系对齐提取。
📄 摘要(原文)
We present a methodology for extracting structured risk factors from corporate 10-K filings while maintaining adherence to a predefined hierarchical taxonomy. Our three-stage pipeline combines LLM extraction with supporting quotes, embedding-based semantic mapping to taxonomy categories, and LLM-as-a-judge validation that filters spurious assignments. To evaluate our approach, we extract 10,688 risk factors from S&P 500 companies and examine risk profile similarity across industry clusters. Beyond extraction, we introduce autonomous taxonomy maintenance where an AI agent analyzes evaluation feedback to identify problematic categories, diagnose failure patterns, and propose refinements, achieving 104.7% improvement in embedding separation in a case study. External validation confirms the taxonomy captures economically meaningful structure: same-industry companies exhibit 63% higher risk profile similarity than cross-industry pairs (Cohen's d=1.06, AUC 0.82, p<0.001). The methodology generalizes to any domain requiring taxonomy-aligned extraction from unstructured text, with autonomous improvement enabling continuous quality maintenance and enhancement as systems process more documents.