Supporting Humans in Evaluating AI Summaries of Legal Depositions
作者: Naghmeh Farzi, Laura Dietz, Dave D. Lewis
分类: cs.CL, cs.IR
发布日期: 2026-01-21
备注: To appear in 2026 ACM SIGIR Conference on Human Information Interaction and Retrieval (CHIIR '26), March 22-26, 2026, Seattle, WA, USA. ACM, New York, NY, USA, 5 pages. https://doi.org/10.1145/3786304.3787923
💡 一句话要点
提出基于Nugget的方法,辅助法律专家评估和改进法律文书摘要。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 法律摘要 Nugget方法 用户辅助评估 大型语言模型 事实准确性
📋 核心要点
- 法律领域对案情陈述摘要的事实准确性要求极高,现有LLM摘要方法难以保证。
- 利用Nugget方法,提取关键事实单元,辅助用户评估和改进法律摘要。
- 构建原型系统,支持法律专家在摘要优劣判断和人工改进两个场景下的应用。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被用于总结长篇文档,但在法律领域,案情陈述摘要的事实准确性至关重要,这带来了严峻的挑战。基于Nugget的方法已被证明对自动评估摘要方法非常有帮助。本文将这些方法应用于用户端,并探讨Nugget如何直接帮助最终用户。尽管之前的系统已经展示了基于Nugget的评估的潜力,但其支持最终用户的潜力仍未被充分探索。本文专注于法律领域,提出了一个原型,该原型利用基于事实Nugget的方法来支持法律专业人员在两个具体场景中工作:(1) 确定两个摘要中哪个更好,以及 (2) 手动改进自动生成的摘要。
🔬 方法详解
问题定义:论文旨在解决法律领域中,如何有效评估和改进大型语言模型生成的案情陈述摘要的问题。现有方法难以保证摘要的事实准确性,法律专业人员需要耗费大量时间进行人工审核和修改。
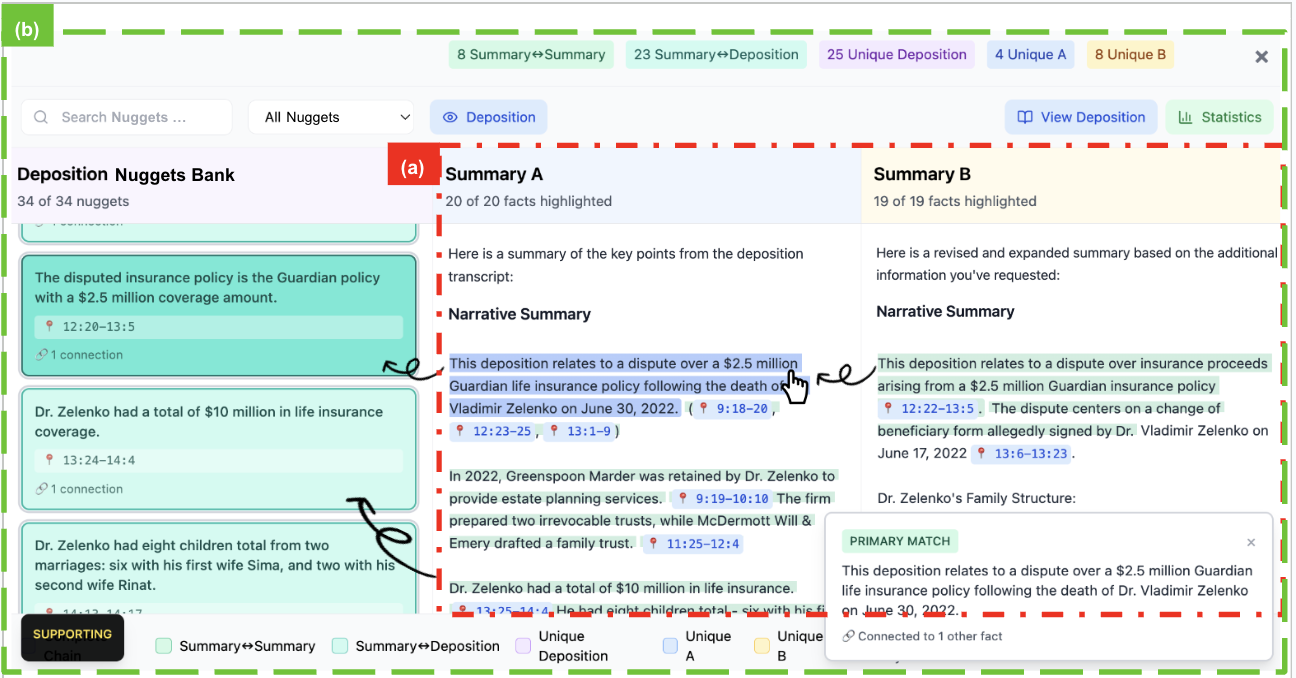
核心思路:论文的核心思路是将Nugget-based评估方法从自动评估领域迁移到用户辅助领域。通过提取摘要中的关键事实单元(Nuggets),并将其呈现给用户,帮助用户快速识别摘要中的错误或遗漏,从而提高评估和改进效率。
技术框架:该原型系统主要包含以下几个模块:1) 文档预处理模块:对原始案情陈述进行清洗和格式化。2) 摘要生成模块:使用大型语言模型生成摘要。3) Nugget提取模块:从原始文档和摘要中提取关键事实单元。4) 用户界面模块:将摘要和对应的Nuggets呈现给用户,并提供评估和编辑功能。
关键创新:该论文的关键创新在于将Nugget-based评估方法应用于用户辅助场景,而不是仅仅用于自动评估。通过将关键事实单元直接呈现给用户,可以显著提高用户评估和改进摘要的效率和准确性。
关键设计:Nugget的定义和提取是关键设计。具体实现细节未知,但推测可能涉及信息抽取、语义分析等技术。用户界面设计也至关重要,需要清晰地呈现摘要和Nuggets,并提供便捷的评估和编辑工具。
🖼️ 关键图片

📊 实验亮点
论文构建了一个原型系统,并展示了其在法律领域的应用潜力。虽然没有提供具体的性能数据,但通过用户研究或案例分析,验证了基于Nugget的方法可以有效辅助法律专业人员评估和改进摘要。具体的提升幅度未知。
🎯 应用场景
该研究成果可应用于法律文书摘要、医疗报告总结等领域,帮助专业人士快速评估和改进AI生成的摘要,提高工作效率和准确性。未来可扩展到其他需要高精度摘要的领域,例如金融分析、科学研究等。
📄 摘要(原文)
While large language models (LLMs) are increasingly used to summarize long documents, this trend poses significant challenges in the legal domain, where the factual accuracy of deposition summaries is crucial. Nugget-based methods have been shown to be extremely helpful for the automated evaluation of summarization approaches. In this work, we translate these methods to the user side and explore how nuggets could directly assist end users. Although prior systems have demonstrated the promise of nugget-based evaluation, its potential to support end users remains underexplored. Focusing on the legal domain, we present a prototype that leverages a factual nugget-based approach to support legal professionals in two concrete scenarios: (1) determining which of two summaries is better, and (2) manually improving an automatically generated summary.