The Flexibility Trap: Why Arbitrary Order Limits Reasoning Potential in Diffusion Language Models
作者: Zanlin Ni, Shenzhi Wang, Yang Yue, Tianyu Yu, Weilin Zhao, Yeguo Hua, Tianyi Chen, Jun Song, Cheng Yu, Bo Zheng, Gao Huang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-01-21
备注: Code and pre-trained models: https://github.com/LeapLabTHU/JustGRPO
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
揭示扩散语言模型中任意顺序生成导致推理能力受限的“灵活性陷阱”
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 推理能力 任意顺序生成 灵活性陷阱 强化学习 自回归生成 Group Relative Policy Optimization
📋 核心要点
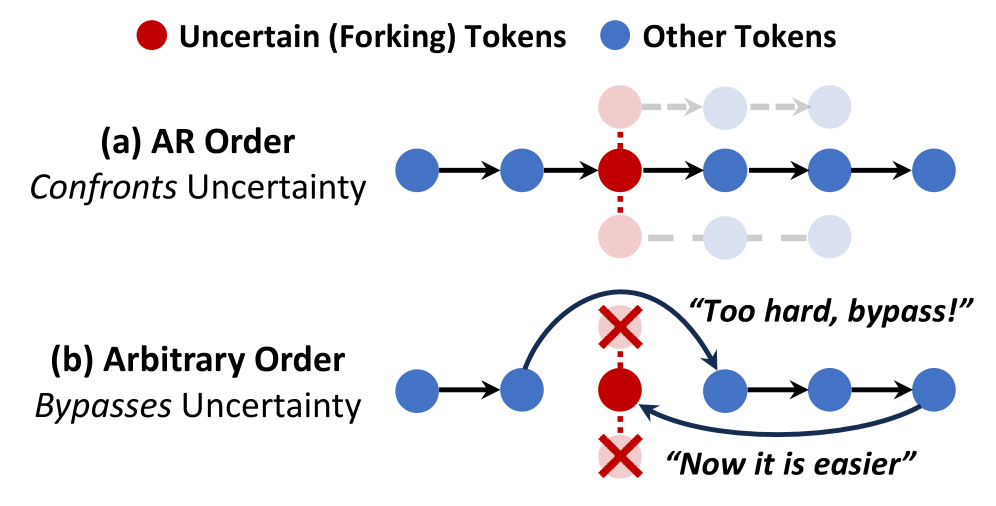
- 现有扩散语言模型虽然具备任意顺序生成token的灵活性,但这种灵活性反而可能限制其推理能力。
- 论文提出JustGRPO方法,通过放弃任意顺序生成,采用标准的Group Relative Policy Optimization (GRPO)来提升推理能力。
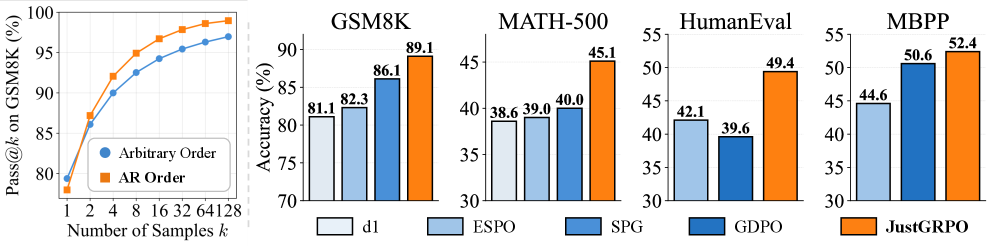
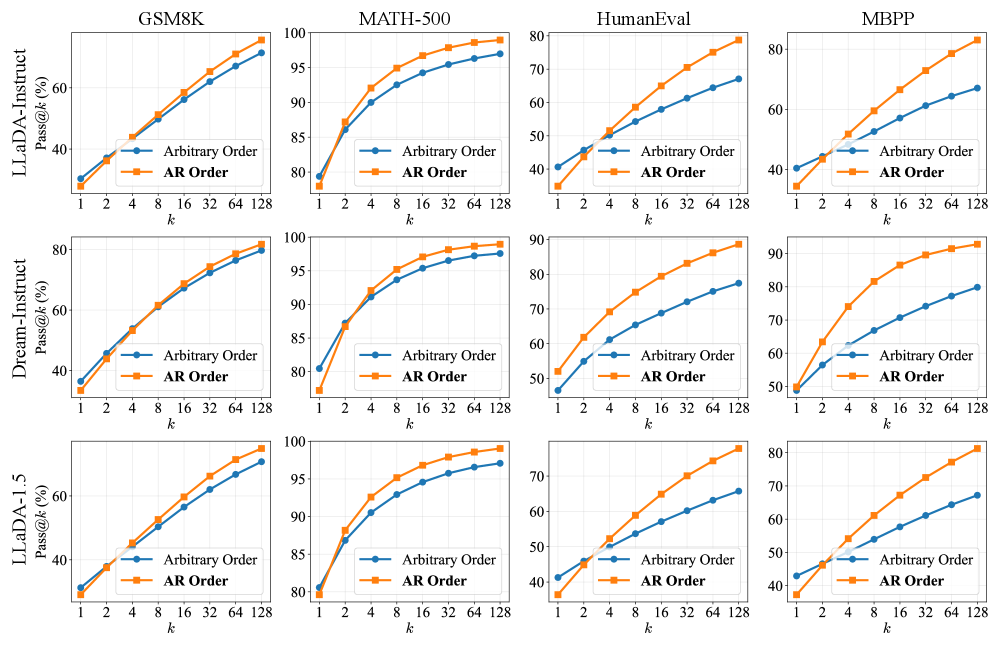
- 实验表明,JustGRPO在GSM8K等任务上取得了显著的性能提升,例如在GSM8K上达到了89.1%的准确率。
📝 摘要(中文)
扩散语言模型(dLLMs)打破了传统LLMs刚性的从左到右约束,实现了任意顺序的token生成。直观上,这种灵活性意味着一个严格包含固定自回归轨迹的解空间,理论上可以释放数学和编码等通用任务的卓越推理潜力。因此,大量工作利用强化学习(RL)来激发dLLMs的推理能力。本文揭示了一个违反直觉的现实:目前形式的任意顺序生成,缩小而非扩大了dLLMs的推理边界。我们发现dLLMs倾向于利用这种顺序灵活性来绕过对探索至关重要的高不确定性token,导致解空间的过早崩溃。这一观察挑战了现有dLLMs强化学习方法的前提,这些方法通常投入大量复杂性(例如处理组合轨迹和难以处理的可能性)来保持这种灵活性。我们证明,通过有意放弃任意顺序并应用标准Group Relative Policy Optimization (GRPO),可以更好地激发有效的推理能力。我们的方法JustGRPO是极简的,但效果惊人(例如,在GSM8K上达到89.1%的准确率),同时完全保留了dLLMs的并行解码能力。
🔬 方法详解
问题定义:论文旨在解决扩散语言模型(dLLMs)在推理任务中表现不佳的问题。现有方法虽然赋予dLLMs任意顺序生成token的灵活性,但这种灵活性反而导致模型倾向于绕过高不确定性的token,从而限制了其探索能力和推理潜力。现有基于强化学习的方法为了保持这种灵活性,引入了复杂的机制,但效果并不理想。
核心思路:论文的核心思路是,放弃dLLMs的任意顺序生成能力,转而采用更传统的自回归生成方式,并结合Group Relative Policy Optimization (GRPO)进行训练。作者认为,强制模型按照一定的顺序生成token,可以避免模型为了追求“捷径”而忽略关键信息,从而更好地进行推理。
技术框架:论文提出的JustGRPO方法,其整体框架可以概括为:首先,使用扩散模型生成token序列;然后,放弃任意顺序生成,强制按照预定的顺序(例如从左到右)进行解码;最后,使用GRPO算法对模型进行训练,以优化其推理能力。该框架保留了dLLMs的并行解码能力。
关键创新:论文最重要的技术创新点在于,它挑战了dLLMs中任意顺序生成是提升推理能力的关键的这一假设。论文通过实验证明,放弃任意顺序生成,采用更传统的自回归方式,反而可以取得更好的推理效果。
关键设计:JustGRPO的关键设计在于,它并没有引入复杂的机制来处理任意顺序生成带来的问题,而是直接放弃了这种灵活性。具体来说,JustGRPO使用标准的GRPO算法进行训练,没有对损失函数或网络结构进行特殊的修改。这种极简的设计使得JustGRPO易于实现和部署。
🖼️ 关键图片
📊 实验亮点
实验结果表明,JustGRPO在GSM8K数据集上取得了显著的性能提升,达到了89.1%的准确率。这一结果表明,放弃任意顺序生成,采用更传统的自回归方式,可以有效地提升扩散语言模型的推理能力。此外,JustGRPO的性能优于现有的基于强化学习的dLLMs方法,证明了其有效性。
🎯 应用场景
该研究成果可应用于各种需要复杂推理能力的自然语言处理任务,例如数学问题求解、代码生成、知识图谱推理等。通过放弃扩散语言模型中可能导致推理能力下降的“灵活性陷阱”,可以提升模型在这些任务上的性能,并为未来的扩散语言模型研究提供新的方向。
📄 摘要(原文)
Diffusion Large Language Models (dLLMs) break the rigid left-to-right constraint of traditional LLMs, enabling token generation in arbitrary orders. Intuitively, this flexibility implies a solution space that strictly supersets the fixed autoregressive trajectory, theoretically unlocking superior reasoning potential for general tasks like mathematics and coding. Consequently, numerous works have leveraged reinforcement learning (RL) to elicit the reasoning capability of dLLMs. In this paper, we reveal a counter-intuitive reality: arbitrary order generation, in its current form, narrows rather than expands the reasoning boundary of dLLMs. We find that dLLMs tend to exploit this order flexibility to bypass high-uncertainty tokens that are crucial for exploration, leading to a premature collapse of the solution space. This observation challenges the premise of existing RL approaches for dLLMs, where considerable complexities, such as handling combinatorial trajectories and intractable likelihoods, are often devoted to preserving this flexibility. We demonstrate that effective reasoning is better elicited by intentionally forgoing arbitrary order and applying standard Group Relative Policy Optimization (GRPO) instead. Our approach, JustGRPO, is minimalist yet surprisingly effective (e.g., 89.1% accuracy on GSM8K) while fully retaining the parallel decoding ability of dLLMs. Project page: https://nzl-thu.github.io/the-flexibility-trap