Knowledge Restoration-driven Prompt Optimization: Unlocking LLM Potential for Open-Domain Relational Triplet Extraction
作者: Xiaonan Jing, Gongqing Wu, Xingrui Zhuo, Lang Sun, Jiapu Wang
分类: cs.CL, cs.AI
发布日期: 2026-01-21
💡 一句话要点
提出知识重建驱动的提示优化框架,提升LLM在开放域关系三元组抽取中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 开放域关系抽取 大型语言模型 提示优化 知识重建 自监督学习
📋 核心要点
- 现有开放域关系三元组抽取方法依赖静态提示,缺乏反思机制,易受语义歧义影响。
- KRPO框架通过知识重建进行自我评估,利用文本梯度优化提示,提升LLM抽取能力。
- 实验表明,KRPO在三个数据集上显著优于现有基线方法,提升了抽取F1分数。
📝 摘要(中文)
开放域关系三元组抽取(ORTE)是挖掘无预定义模式的结构化知识的基础。尽管大型语言模型(LLM)具有令人印象深刻的上下文学习能力,但现有方法受到静态、启发式驱动的提示策略的限制。由于缺乏内化错误信号所需的反思机制,这些方法在语义模糊性方面表现出脆弱性,常常使错误的抽取模式永久化。为了解决这个瓶颈,我们提出了一个知识重建驱动的提示优化(KRPO)框架,以帮助LLM持续提高其复杂ORTE任务流程的抽取能力。具体来说,我们设计了一种基于知识重建的自我评估机制,通过将结构化三元组投影到语义一致性分数中来提供内在反馈信号。随后,我们提出了一种基于文本梯度的提示优化器,它可以内化历史经验以迭代优化提示,从而更好地指导LLM处理后续抽取任务。此外,为了减轻关系冗余,我们设计了一个关系规范化记忆,用于收集代表性关系并为三元组提供语义上不同的模式。在三个数据集上的大量实验表明,KRPO在抽取F1分数方面显著优于强大的基线。
🔬 方法详解
问题定义:开放域关系三元组抽取旨在从非结构化文本中提取关系三元组,无需预定义模式。现有方法依赖人工设计的静态提示,无法有效处理复杂的语义歧义,且缺乏从错误中学习的能力,导致抽取性能受限。
核心思路:KRPO的核心在于利用知识重建来驱动提示优化。通过将抽取的三元组映射回语义空间,并评估其一致性,为LLM提供内在的反馈信号。然后,利用这些反馈信号迭代优化提示,使LLM能够更好地理解和处理后续的抽取任务。
技术框架:KRPO框架主要包含三个模块:知识重建模块、提示优化模块和关系规范化记忆模块。知识重建模块负责将抽取的三元组投影到语义空间,并计算语义一致性得分。提示优化模块利用文本梯度,根据知识重建模块的反馈信号,迭代优化提示。关系规范化记忆模块用于收集代表性关系,并为三元组提供语义上不同的模式,以减少关系冗余。
关键创新:KRPO的关键创新在于提出了基于知识重建的自我评估机制和基于文本梯度的提示优化器。自我评估机制能够为LLM提供内在的反馈信号,使其能够从错误中学习。提示优化器能够有效地利用这些反馈信号,迭代优化提示,提升LLM的抽取能力。
关键设计:知识重建模块使用预训练的语言模型(如BERT)将三元组中的实体和关系映射到语义空间,并计算它们之间的余弦相似度作为语义一致性得分。提示优化模块使用文本梯度下降算法,根据语义一致性得分调整提示中的关键词。关系规范化记忆模块使用聚类算法,将相似的关系聚类到一起,并选择最具代表性的关系作为规范化关系。
🖼️ 关键图片
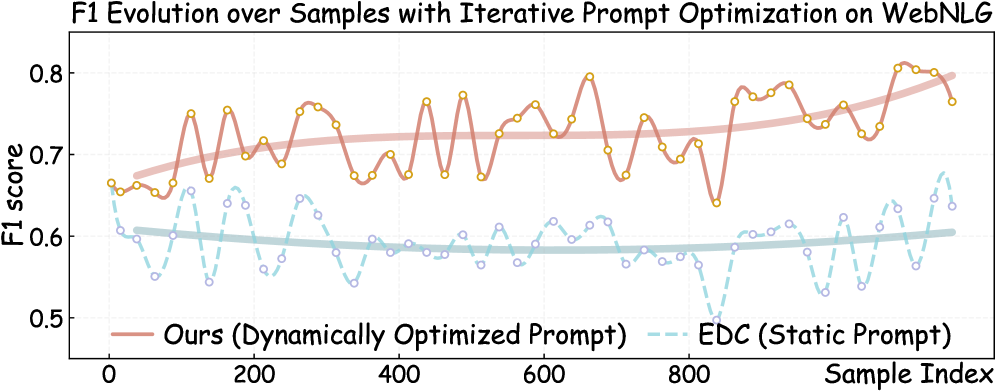
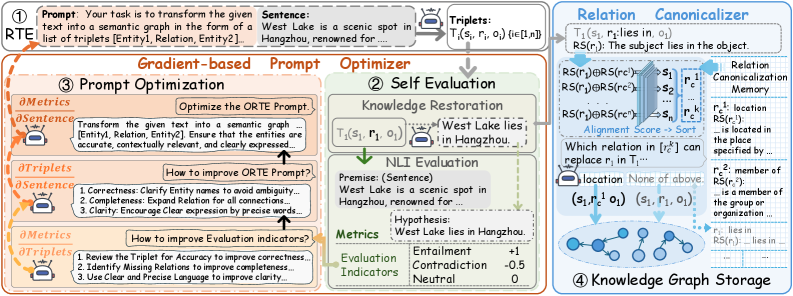
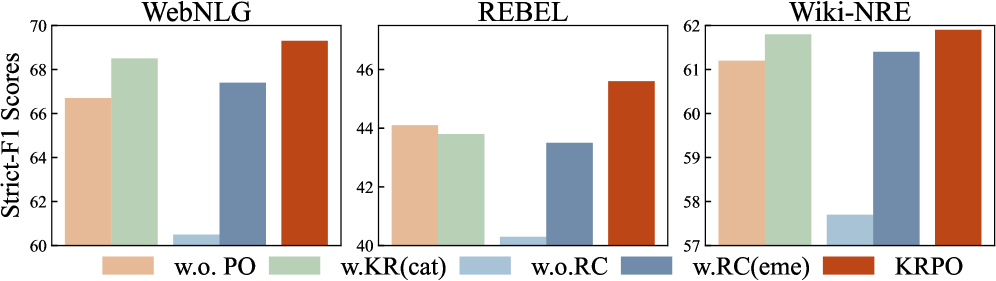
📊 实验亮点
实验结果表明,KRPO在三个数据集上显著优于现有基线方法,包括基于启发式提示的方法和基于微调的方法。具体而言,KRPO在抽取F1分数方面取得了显著提升,证明了其在开放域关系三元组抽取任务中的有效性。
🎯 应用场景
该研究成果可应用于知识图谱构建、信息抽取、问答系统等领域。通过提升LLM在开放域关系三元组抽取中的性能,可以更有效地从海量文本数据中挖掘结构化知识,为下游任务提供更准确、更全面的信息。
📄 摘要(原文)
Open-domain Relational Triplet Extraction (ORTE) is the foundation for mining structured knowledge without predefined schemas. Despite the impressive in-context learning capabilities of Large Language Models (LLMs), existing methods are hindered by their reliance on static, heuristic-driven prompting strategies. Due to the lack of reflection mechanisms required to internalize erroneous signals, these methods exhibit vulnerability in semantic ambiguity, often making erroneous extraction patterns permanent. To address this bottleneck, we propose a Knowledge Reconstruction-driven Prompt Optimization (KRPO) framework to assist LLMs in continuously improving their extraction capabilities for complex ORTE task flows. Specifically, we design a self-evaluation mechanism based on knowledge restoration, which provides intrinsic feedback signals by projecting structured triplets into semantic consistency scores. Subsequently, we propose a prompt optimizer based on a textual gradient that can internalize historical experiences to iteratively optimize prompts, which can better guide LLMs to handle subsequent extraction tasks. Furthermore, to alleviate relation redundancy, we design a relation canonicalization memory that collects representative relations and provides semantically distinct schemas for the triplets. Extensive experiments across three datasets show that KRPO significantly outperforms strong baselines in the extraction F1 score.