PodBench: A Comprehensive Benchmark for Instruction-Aware Audio-Oriented Podcast Script Generation
作者: Chenning Xu, Mao Zheng, Mingyu Zheng, Mingyang Song
分类: cs.CL
发布日期: 2026-01-21
💡 一句话要点
PodBench:一个面向指令感知的播客脚本生成综合评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 播客脚本生成 大型语言模型 基准数据集 多说话人对话 长文本生成
📋 核心要点
- 现有播客脚本生成任务缺乏系统性的评估资源,难以有效评估和提升模型性能。
- PodBench基准包含长文本输入和复杂的多说话人指令,旨在更真实地反映实际播客场景。
- 实验表明,配备显式推理的开源模型在长文本和多说话人协调方面优于标准基线,但指令遵循与内容质量之间存在差距。
📝 摘要(中文)
播客脚本生成需要大型语言模型(LLMs)从多样化的输入中合成结构化的、上下文相关的对话,但针对此任务的系统性评估资源仍然有限。为了弥补这一差距,我们推出了PodBench,一个包含800个样本的基准,其输入最多可达21K tokens,并具有复杂的多说话人指令。我们提出了一个多方面的评估框架,该框架集成了定量约束和基于LLM的质量评估。广泛的实验表明,虽然专有模型通常表现出色,但配备了显式推理的开源模型在处理长上下文和多说话人协调方面表现出比标准基线更强的鲁棒性。然而,我们的分析发现了一个持续存在的差异,即高指令遵循并不能保证高的内容实质。PodBench提供了一个可复现的测试平台,以解决这种长篇、以音频为中心的生成中的挑战。
🔬 方法详解
问题定义:论文旨在解决播客脚本生成任务中缺乏系统性评估基准的问题。现有方法难以评估模型在处理长文本输入、复杂多说话人指令以及保证内容质量方面的能力。现有评估方法缺乏定量约束,难以客观评估生成质量。
核心思路:论文的核心思路是构建一个包含多样化播客场景的基准数据集PodBench,并设计一个多方面的评估框架,该框架集成了定量约束和基于LLM的质量评估。通过该基准和评估框架,可以更全面地评估和比较不同模型在播客脚本生成任务中的性能。
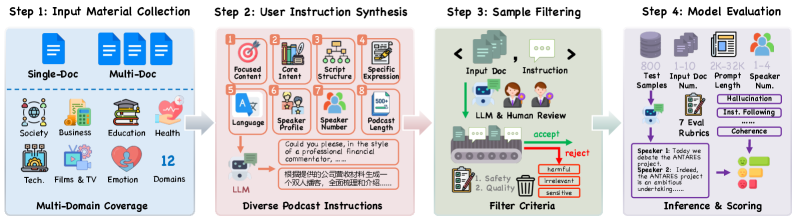
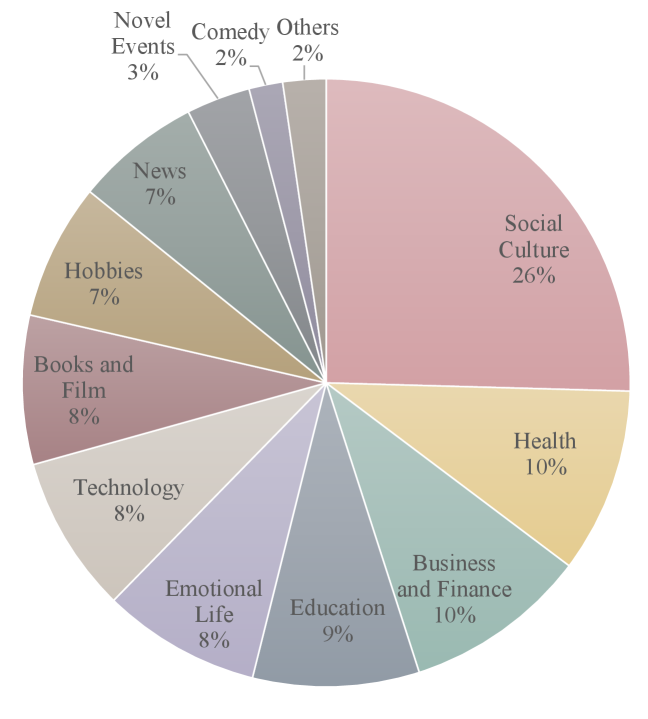
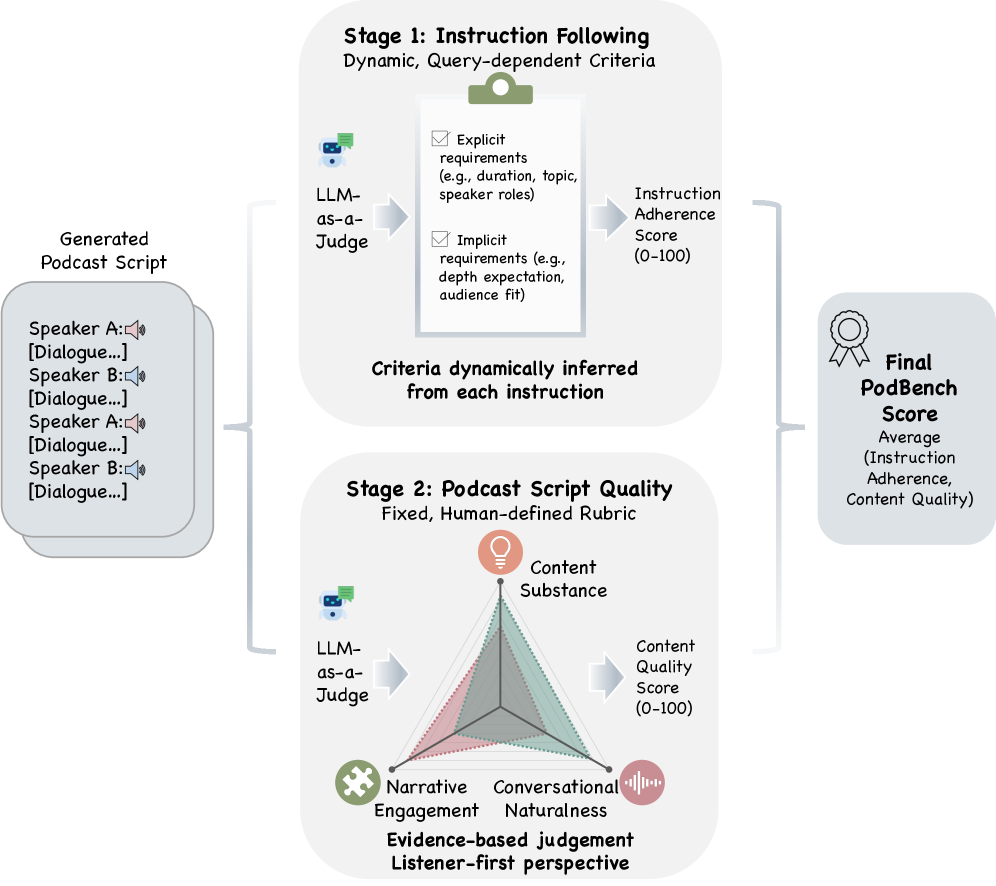
技术框架:PodBench基准数据集包含800个样本,每个样本包含长文本输入(最多21K tokens)和复杂的多说话人指令。评估框架包括:1) 定量约束,例如对话长度、说话人比例等;2) 基于LLM的质量评估,利用大型语言模型评估生成脚本的流畅性、相关性和一致性。
关键创新:论文的关键创新在于:1) 构建了一个新的播客脚本生成基准数据集PodBench,该数据集具有长文本输入和复杂的多说话人指令;2) 提出了一个多方面的评估框架,该框架集成了定量约束和基于LLM的质量评估,可以更全面地评估生成质量。
关键设计:数据集构建过程中,作者收集了大量的播客音频和文本数据,并进行了清洗和标注。评估框架中,定量约束的设计考虑了播客脚本的特点,例如对话长度、说话人比例等。基于LLM的质量评估使用了预训练的语言模型,并针对播客脚本生成任务进行了微调。具体参数设置和损失函数等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,专有模型在播客脚本生成任务中通常表现出色,但配备显式推理的开源模型在处理长上下文和多说话人协调方面表现出比标准基线更强的鲁棒性。然而,实验也发现,高指令遵循并不能保证高的内容实质,这表明现有模型在内容生成方面仍有提升空间。具体性能数据和提升幅度在摘要中未给出。
🎯 应用场景
该研究成果可应用于自动化播客内容创作、智能语音助手、以及其他需要生成长文本对话的场景。PodBench基准数据集和评估框架可以促进播客脚本生成技术的发展,提高生成内容的质量和效率,并为相关研究提供可复现的测试平台。未来,该研究可以扩展到其他音频内容生成领域,例如有声书、广播剧等。
📄 摘要(原文)
Podcast script generation requires LLMs to synthesize structured, context-grounded dialogue from diverse inputs, yet systematic evaluation resources for this task remain limited. To bridge this gap, we introduce PodBench, a benchmark comprising 800 samples with inputs up to 21K tokens and complex multi-speaker instructions. We propose a multifaceted evaluation framework that integrates quantitative constraints with LLM-based quality assessment. Extensive experiments reveal that while proprietary models generally excel, open-source models equipped with explicit reasoning demonstrate superior robustness in handling long contexts and multi-speaker coordination compared to standard baselines. However, our analysis uncovers a persistent divergence where high instruction following does not guarantee high content substance. PodBench offers a reproducible testbed to address these challenges in long-form, audio-centric generation.