Render-of-Thought: Rendering Textual Chain-of-Thought as Images for Visual Latent Reasoning
作者: Yifan Wang, Shiyu Li, Peiming Li, Xiaochen Yang, Yang Tang, Zheng Wei
分类: cs.CL, cs.CV
发布日期: 2026-01-21
🔗 代码/项目: GITHUB
💡 一句话要点
提出Render-of-Thought,将文本推理链渲染为图像,用于视觉潜在推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉推理 链式思考 视觉语言模型 文本渲染 推理加速
📋 核心要点
- 现有CoT推理计算开销大,且缺乏对中间推理过程的有效监督,导致推理链可分析性不足。
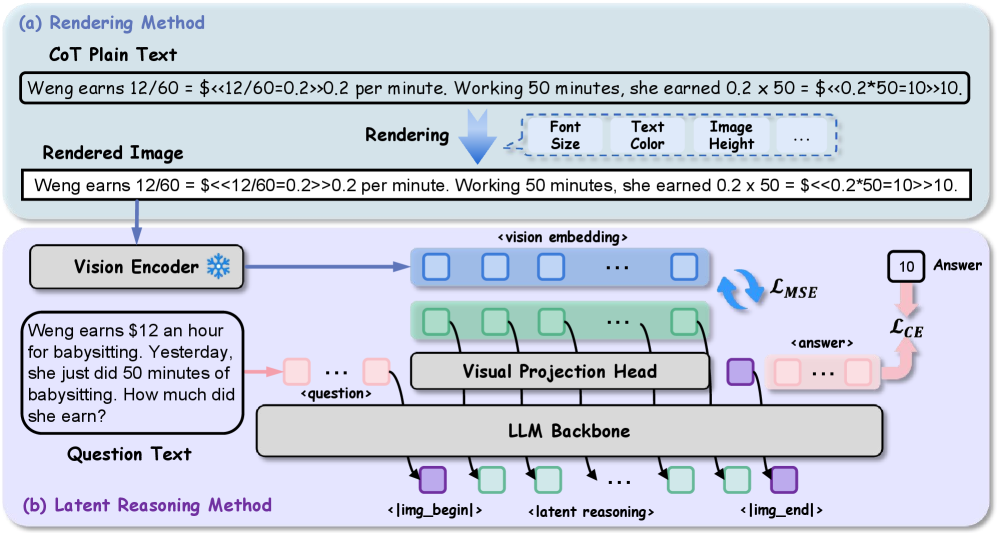
- RoT将文本推理步骤渲染为图像,利用视觉语言模型的视觉编码器对齐视觉和文本嵌入,实现推理链的可视化。
- 实验表明,RoT在数学和逻辑推理任务上实现了显著的token压缩和推理加速,同时保持了竞争力的性能。
📝 摘要(中文)
Chain-of-Thought (CoT) prompting 在激发大型语言模型 (LLMs) 的推理能力方面取得了显著成功。虽然 CoT prompting 增强了推理,但其冗长性带来了巨大的计算开销。目前的工作通常只关注结果对齐,而缺乏对中间推理过程的监督。这些缺陷模糊了潜在推理链的可分析性。为了解决这些挑战,我们引入了 Render-of-Thought (RoT),这是第一个通过将文本步骤渲染成图像来具体化推理链的框架,使潜在的原理显式化和可追溯。具体来说,我们利用现有视觉语言模型 (VLMs) 的视觉编码器作为语义锚点,将视觉嵌入与文本空间对齐。这种设计确保了即插即用的实现,而不会产生额外的预训练开销。在数学和逻辑推理基准上的大量实验表明,与显式 CoT 相比,我们的方法实现了 3-4 倍的 token 压缩和显著的推理加速。此外,它保持了与其他方法相比具有竞争力的性能,验证了这种范例的可行性。
🔬 方法详解
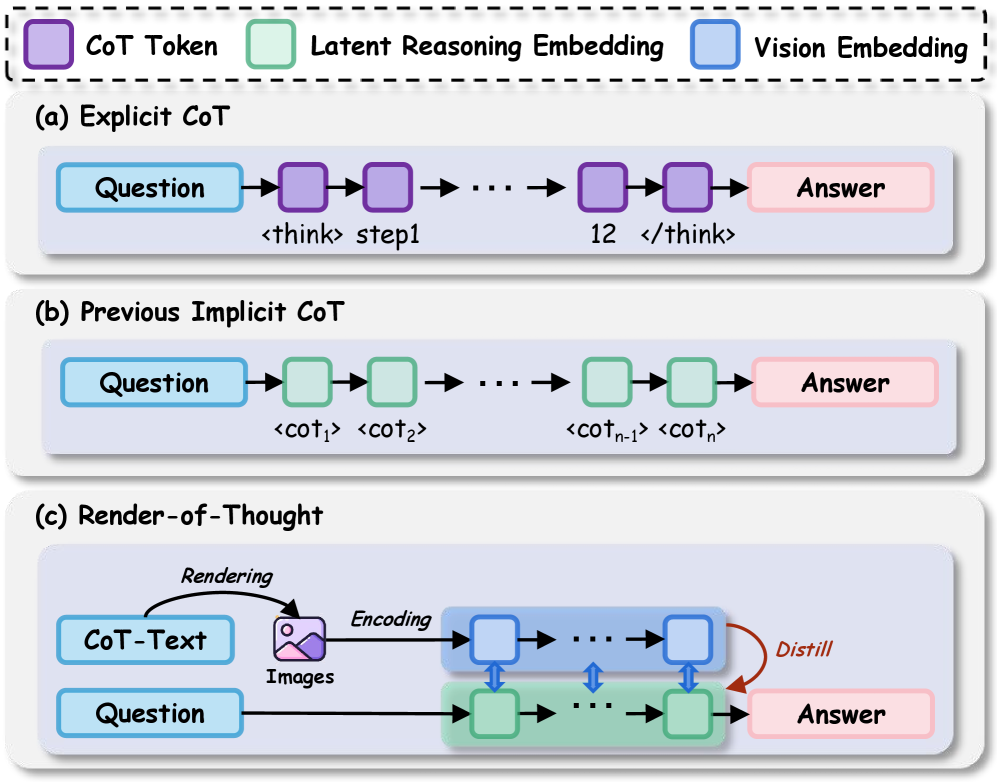
问题定义:论文旨在解决Chain-of-Thought (CoT) 推理中计算开销大和中间推理过程缺乏监督的问题。现有的CoT方法虽然能提升LLM的推理能力,但其冗长的文本输出导致计算成本显著增加,并且难以分析中间推理步骤,缺乏可解释性。
核心思路:论文的核心思路是将文本形式的推理链转换为图像形式,利用视觉信息来压缩和表达推理过程。通过将文本步骤渲染成图像,可以利用视觉语言模型(VLM)的视觉编码器来对齐视觉和文本嵌入,从而实现推理过程的可视化和高效表示。
技术框架:RoT框架主要包含以下几个阶段:1) 使用LLM生成文本形式的CoT推理链;2) 将CoT推理链中的每个步骤渲染成对应的图像;3) 利用VLM的视觉编码器提取图像的视觉特征;4) 将视觉特征输入到下游任务模型中进行推理或预测。整个框架是端到端可训练的,并且可以方便地集成到现有的VLM中。
关键创新:RoT最重要的创新点在于将文本推理链转换为图像表示,从而利用视觉信息来压缩和表达推理过程。与传统的CoT方法相比,RoT能够显著减少token数量,降低计算开销,并提高推理速度。此外,通过可视化推理链,RoT也提高了模型的可解释性。
关键设计:RoT的关键设计包括:1) 使用预训练的VLM的视觉编码器作为语义锚点,对齐视觉和文本嵌入;2) 设计合适的图像渲染方法,将文本步骤转换为具有语义信息的图像;3) 优化下游任务模型的结构,使其能够有效地利用视觉特征进行推理。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RoT在数学和逻辑推理基准上实现了显著的性能提升。与显式CoT相比,RoT实现了3-4倍的token压缩和显著的推理加速,同时保持了具有竞争力的性能。例如,在某些任务上,RoT的性能甚至超过了传统的CoT方法。
🎯 应用场景
RoT具有广泛的应用前景,例如可以应用于机器人导航、视觉问答、图像推理等领域。通过将文本指令或推理过程转换为图像,可以使机器人或智能系统更好地理解和执行任务。此外,RoT还可以用于教育领域,帮助学生更好地理解复杂的概念和推理过程。
📄 摘要(原文)
Chain-of-Thought (CoT) prompting has achieved remarkable success in unlocking the reasoning capabilities of Large Language Models (LLMs). Although CoT prompting enhances reasoning, its verbosity imposes substantial computational overhead. Recent works often focus exclusively on outcome alignment and lack supervision on the intermediate reasoning process. These deficiencies obscure the analyzability of the latent reasoning chain. To address these challenges, we introduce Render-of-Thought (RoT), the first framework to reify the reasoning chain by rendering textual steps into images, making the latent rationale explicit and traceable. Specifically, we leverage the vision encoders of existing Vision Language Models (VLMs) as semantic anchors to align the vision embeddings with the textual space. This design ensures plug-and-play implementation without incurring additional pre-training overhead. Extensive experiments on mathematical and logical reasoning benchmarks demonstrate that our method achieves 3-4x token compression and substantial inference acceleration compared to explicit CoT. Furthermore, it maintains competitive performance against other methods, validating the feasibility of this paradigm. Our code is available at https://github.com/TencentBAC/RoT