DARL: Encouraging Diverse Answers for General Reasoning without Verifiers
作者: Chongxuan Huang, Lei Lin, Xiaodong Shi, Wenping Hu, Ruiming Tang
分类: cs.CL
发布日期: 2026-01-21
💡 一句话要点
DARL:无需验证器,鼓励生成多样化答案的通用推理强化学习框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 通用推理 多样性生成 语言模型 无验证器
📋 核心要点
- 现有通用推理强化学习方法易于过拟合参考答案,限制了模型生成多样化输出的能力,尤其是在开放式任务中。
- DARL框架旨在鼓励模型在与参考答案保持一致性的前提下,生成受控偏差范围内的多样化答案。
- 实验结果表明,DARL在多个基准测试中超越了现有方法,显著提高了推理准确性和输出多样性。
📝 摘要(中文)
可验证奖励的强化学习(RLVR)已在增强大型语言模型的推理能力方面展现出前景。然而,它对特定领域验证器的依赖显著限制了其在开放和通用领域的适用性。诸如RLPR等最新研究已将RLVR扩展到通用领域,从而能够在更广泛的数据集上进行训练,并实现优于RLVR的性能。然而,这些方法的一个显著局限性是它们倾向于过度拟合参考答案,这限制了模型生成多样化输出的能力。这种限制在开放式任务(如写作)中尤为明显,因为这些任务存在多种合理的答案。为了解决这个问题,我们提出了DARL,这是一个简单而有效的强化学习框架,它鼓励在与参考答案保持一致性的前提下,在受控的偏差范围内生成多样化的答案。我们的框架与现有的通用强化学习方法完全兼容,并且可以无缝集成,无需额外的验证器。在13个基准上的大量实验表明,推理性能得到了持续的提高。值得注意的是,DARL超越了RLPR,在6个推理基准上平均提高了1.3个点,在7个通用基准上平均提高了9.5个点,突出了其在提高推理准确性和输出多样性方面的有效性。
🔬 方法详解
问题定义:论文旨在解决通用推理强化学习中,模型过度拟合参考答案,导致生成答案缺乏多样性的问题。现有方法如RLPR虽然扩展了RLVR到通用领域,但仍然存在这一痛点,尤其是在开放式生成任务中,单一的参考答案限制了模型的创造性。
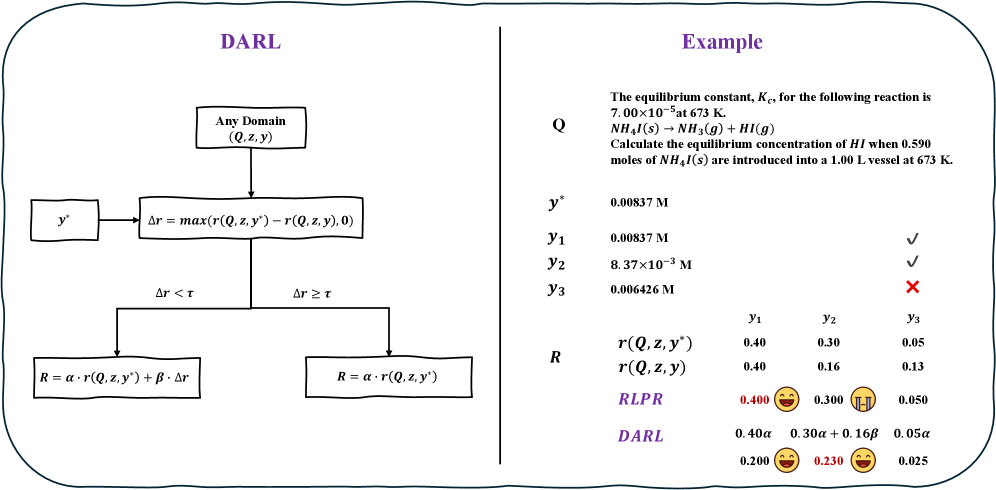
核心思路:DARL的核心思路是在强化学习过程中,鼓励模型生成与参考答案相似但又有所不同的答案。通过控制生成答案与参考答案的偏差范围,在保证答案合理性的前提下,提高答案的多样性。这种方法避免了对特定领域验证器的依赖,使其更具通用性。
技术框架:DARL框架可以与现有的通用强化学习方法无缝集成。其主要流程包括:1) 使用大型语言模型生成答案;2) 计算生成答案与参考答案之间的偏差;3) 根据偏差大小,给予模型相应的奖励或惩罚;4) 使用强化学习算法更新模型参数,使其倾向于生成既与参考答案相似,又具有一定差异性的答案。
关键创新:DARL的关键创新在于其无需额外的验证器,即可在通用领域实现多样化答案的生成。它通过控制生成答案与参考答案的偏差,在保证答案质量的同时,鼓励模型探索更多的可能性。这与依赖领域特定验证器的RLVR以及容易过拟合参考答案的RLPR形成了鲜明对比。
关键设计:DARL的关键设计在于偏差的计算方式和奖励函数的构建。偏差可以使用多种方法计算,例如BLEU score、ROUGE score等。奖励函数的设计需要平衡准确性和多样性,既要保证生成答案与参考答案的相关性,又要鼓励模型生成不同的答案。具体的参数设置需要根据具体的任务进行调整。
🖼️ 关键图片
📊 实验亮点
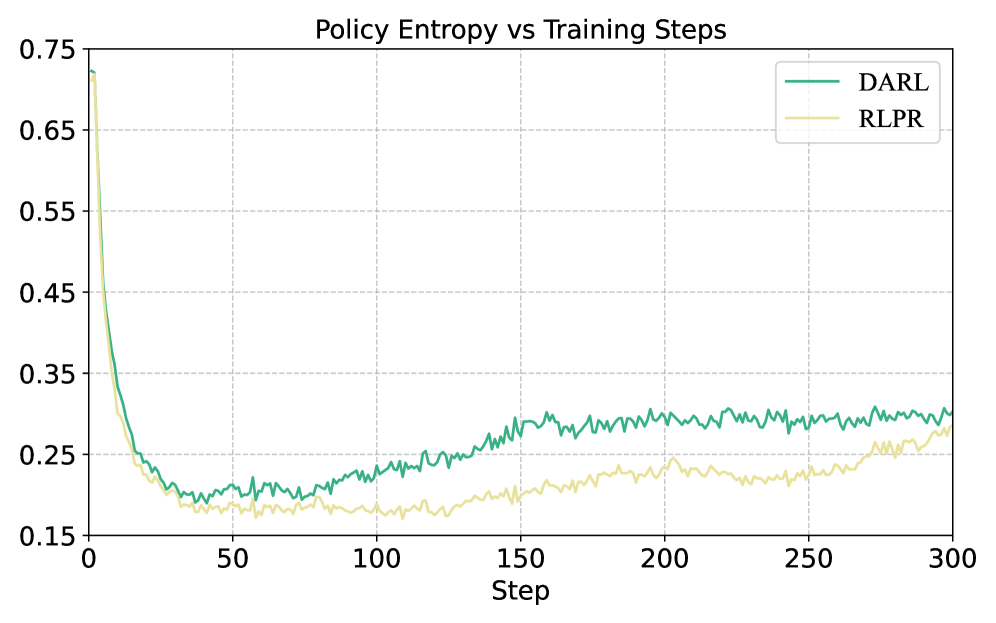
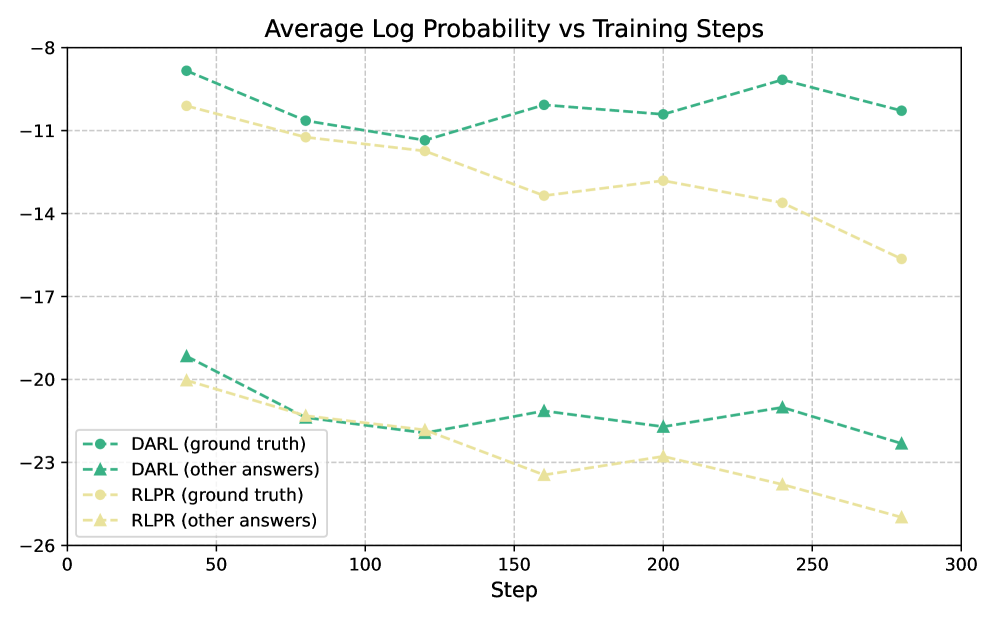
DARL在13个基准测试中取得了显著的性能提升。在6个推理基准上,DARL平均超越RLPR 1.3个点;在7个通用基准上,DARL平均超越RLPR 9.5个点。这些结果表明,DARL在提高推理准确性和输出多样性方面具有显著优势,验证了其有效性。
🎯 应用场景
DARL框架具有广泛的应用前景,可以应用于各种需要生成多样化答案的场景,例如开放式问答、创意写作、对话生成等。该研究有助于提高语言模型的创造性和灵活性,使其能够更好地适应复杂多变的应用环境。未来,该方法可以进一步扩展到多模态领域,例如图像描述生成等。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards (RLVR) has demonstrated promising gains in enhancing the reasoning capabilities of large language models. However, its dependence on domain-specific verifiers significantly restricts its applicability to open and general domains. Recent efforts such as RLPR have extended RLVR to general domains, enabling training on broader datasets and achieving improvements over RLVR. However, a notable limitation of these methods is their tendency to overfit to reference answers, which constrains the model's ability to generate diverse outputs. This limitation is particularly pronounced in open-ended tasks such as writing, where multiple plausible answers exist. To address this, we propose DARL, a simple yet effective reinforcement learning framework that encourages the generation of diverse answers within a controlled deviation range from the reference while preserving alignment with it. Our framework is fully compatible with existing general reinforcement learning methods and can be seamlessly integrated without additional verifiers. Extensive experiments on thirteen benchmarks demonstrate consistent improvements in reasoning performance. Notably, DARL surpasses RLPR, achieving average gains of 1.3 points on six reasoning benchmarks and 9.5 points on seven general benchmarks, highlighting its effectiveness in improving both reasoning accuracy and output diversity.