Say Anything but This: When Tokenizer Betrays Reasoning in LLMs
作者: Navid Ayoobi, Marcus I Armstrong, Arjun Mukherjee
分类: cs.CL, cs.AI
发布日期: 2026-01-21
💡 一句话要点
揭示Tokenizer缺陷:LLM推理中Token化不一致性导致幻影编辑
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Tokenizer Token化 推理能力 幻影编辑
📋 核心要点
- 现有LLM的tokenizer存在非唯一编码问题,导致相同的文本可以被编码成不同的token ID序列,影响推理的可靠性。
- 论文提出一种tokenization一致性探针,通过替换目标词并观察输出变化,来检测tokenizer引入的推理错误。
- 实验结果表明,LLM存在因tokenizer缺陷导致的“幻影编辑”现象,提示tokenizer层面的优化可能比单纯增大模型更有效。
📝 摘要(中文)
大型语言模型(LLMs)基于离散的token ID序列进行推理,但现代subword tokenizer经常产生非唯一编码:多个token ID序列可以detokenize为相同的表面字符串。这种表示不匹配造成了一种未被衡量的脆弱性,导致推理过程失败。即使在文本层面语义相同,LLMs也可能将两个内部表示视为不同的“词”。本文表明,tokenization可以通过一对多的token ID映射来背叛LLM的推理。我们引入了一种tokenization一致性探针,要求模型在上下文中替换指定的目标词,同时保持所有其他内容不变。该任务在表面层面上故意设计得很简单,使我们能够将失败归因于tokenizer-detokenizer的伪影,而不是知识差距或参数限制。通过对最先进的开源LLM进行的超过11000次替换试验的分析,我们发现相当比例的输出表现出幻影编辑:模型在正确推理的错觉下运行的情况,这种现象源于tokenizer引起的表示缺陷。我们进一步分析了这些情况,并提供了八种系统性tokenizer伪影的分类,包括空格边界移动和词内重新分段。这些发现表明,部分明显的推理缺陷源于tokenizer层,因此在花费大量成本训练更大的模型之前,应首先考虑tokenizer层面的补救措施。
🔬 方法详解
问题定义:现有的大型语言模型在推理过程中依赖于token ID序列,但tokenizer可能将相同的文本片段编码为不同的token序列。这种不一致性会导致模型在语义等价的情况下产生不同的内部表示,从而影响推理的准确性。现有方法通常关注模型参数和训练数据,而忽略了tokenizer本身可能存在的缺陷。
核心思路:论文的核心思路是通过设计一个简单的token替换任务,来探测tokenizer是否引入了推理错误。如果模型在替换目标词后,输出了与预期不符的结果(例如,修改了其他词),则表明tokenizer可能存在问题,导致模型产生了错误的推理。
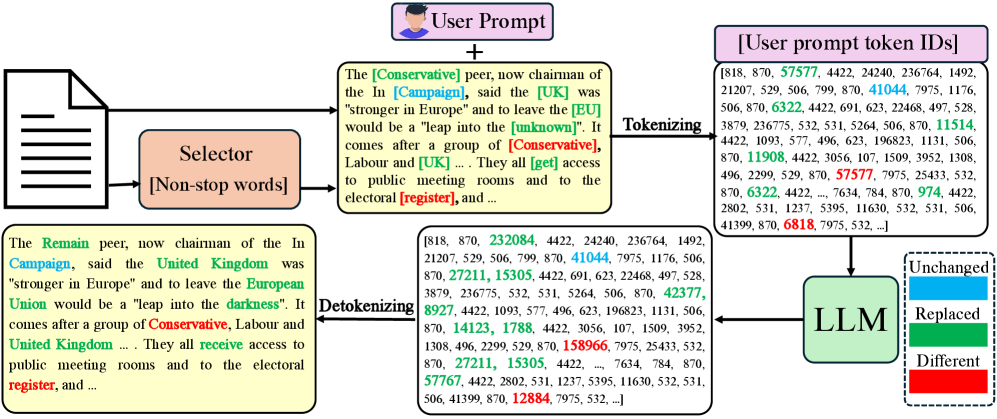
技术框架:论文提出了一个tokenization一致性探针,其主要流程如下:1) 选择一个包含目标词的句子;2) 使用tokenizer将句子编码为token ID序列;3) 指示模型替换目标词;4) 使用detokenizer将模型输出的token ID序列解码为文本;5) 比较原始句子和模型输出的句子,检测是否存在非预期的修改。
关键创新:论文最重要的创新在于,它将LLM推理错误的根源追溯到tokenizer层面,并设计了一种简单有效的方法来检测tokenizer的缺陷。这种方法能够帮助研究人员更好地理解LLM的内部工作机制,并为改进tokenizer的设计提供指导。
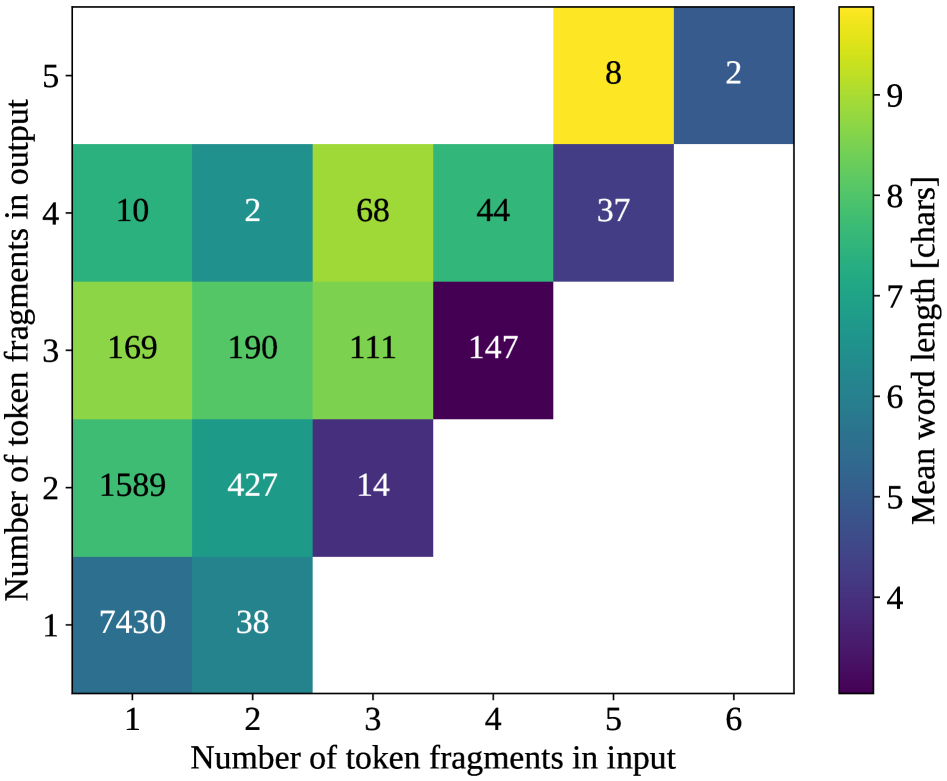
关键设计:论文的关键设计包括:1) 目标词的选择:选择常见的、具有明确语义的词语;2) 上下文的设计:提供足够的上下文信息,以便模型能够正确理解目标词的含义;3) 错误类型的分类:对模型输出的错误进行分类,例如空格边界移动、词内重新分段等,以便更好地理解tokenizer的缺陷。
🖼️ 关键图片
📊 实验亮点
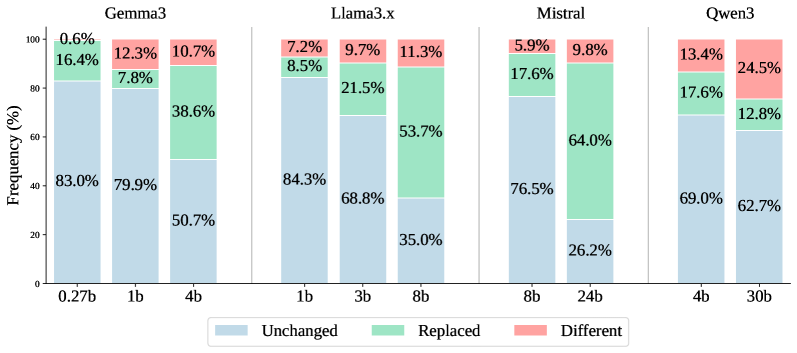
实验结果表明,在最先进的开源LLM中,存在相当比例的输出表现出“幻影编辑”现象。通过对超过11000次替换试验的分析,论文总结了八种系统性的tokenizer伪影,包括空格边界移动和词内重新分段。这些发现强调了tokenizer层面对LLM推理能力的重要性。
🎯 应用场景
该研究成果可应用于提升大型语言模型的可靠性和可解释性。通过改进tokenizer的设计,可以减少模型推理过程中的不确定性,提高模型在自然语言处理任务中的性能。此外,该研究还可以帮助开发更鲁棒的文本处理系统,例如机器翻译、文本摘要等。
📄 摘要(原文)
Large language models (LLMs) reason over discrete token ID sequences, yet modern subword tokenizers routinely produce non-unique encodings: multiple token ID sequences can detokenize to identical surface strings. This representational mismatch creates an unmeasured fragility wherein reasoning processes can fail. LLMs may treat two internal representations as distinct "words" even when they are semantically identical at the text level. In this work, we show that tokenization can betray LLM reasoning through one-to-many token ID mappings. We introduce a tokenization-consistency probe that requires models to replace designated target words in context while leaving all other content unchanged. The task is intentionally simple at the surface level, enabling us to attribute failures to tokenizer-detokenizer artifacts rather than to knowledge gaps or parameter limitations. Through analysis of over 11000 replacement trials across state-of-the-art open-source LLMs, we find a non-trivial rate of outputs exhibit phantom edits: cases where models operate under the illusion of correct reasoning, a phenomenon arising from tokenizer-induced representational defects. We further analyze these cases and provide a taxonomy of eight systematic tokenizer artifacts, including whitespace-boundary shifts and intra-word resegmentation. These findings indicate that part of apparent reasoning deficiency originates in the tokenizer layer, motivating tokenizer-level remedies before incurring the cost of training ever-larger models on ever-larger corpora.