Rewarding How Models Think Pedagogically: Integrating Pedagogical Reasoning and Thinking Rewards for LLMs in Education
作者: Unggi Lee, Jiyeong Bae, Jaehyeon Park, Haeun Park, Taejun Park, Younghoon Jeon, Sungmin Cho, Junbo Koh, Yeil Jeong, Gyeonggeon Lee
分类: cs.CL
发布日期: 2026-01-21
💡 一句话要点
PedagogicalRL-Thinking:融合教学推理和思维奖励,优化LLM在教育中的应用
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 智能辅导系统 强化学习 教学推理 思维奖励
📋 核心要点
- 现有LLM教育应用侧重优化输出,忽略了模型内部推理过程的教学质量。
- PedagogicalRL-Thinking框架通过教学推理提示和思维奖励,提升LLM的教学能力。
- 实验表明,该方法在数学辅导中有效,并在未见过的教育基准上表现出泛化能力。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被部署为智能辅导系统,但专门针对教育环境优化LLMs的研究仍然有限。最近的研究提出了强化学习方法来训练LLM导师,但这些方法只关注优化可见的回复,而忽略了模型内部的思考过程。我们引入了PedagogicalRL-Thinking框架,通过两种新颖的方法将教学对齐扩展到教育中的推理LLMs:(1)教学推理提示,它使用领域特定的教育理论而不是通用指令来指导内部推理;(2)思维奖励,它显式地评估和加强模型推理轨迹的教学质量。我们的实验表明,领域特定的、基于理论的提示优于通用提示,并且思维奖励与教学提示相结合时效果最佳。此外,仅在数学辅导对话中训练的模型在训练期间未见过的教育基准测试中表现出改进,同时保留了基础模型的事实知识。我们的定量和定性分析表明,教学思维奖励产生系统的推理轨迹变化,在导师的思考过程中增加了教学推理和更结构化的教学决策。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在教育领域应用时,仅仅优化可见回复而忽略模型内部推理过程的教学质量的问题。现有方法主要关注生成高质量的答案,而忽略了模型如何思考以及如何以教学有效的方式进行推理,导致LLM在教学场景中的表现受限。
核心思路:论文的核心思路是通过强化学习,显式地引导和奖励LLM进行符合教育理论的推理。具体来说,通过引入“教学推理提示”来指导LLM的内部推理过程,并设计“思维奖励”来评估和加强模型推理轨迹的教学质量。这种方法旨在使LLM不仅能给出正确的答案,还能以一种教学有效的方式进行思考和解释。
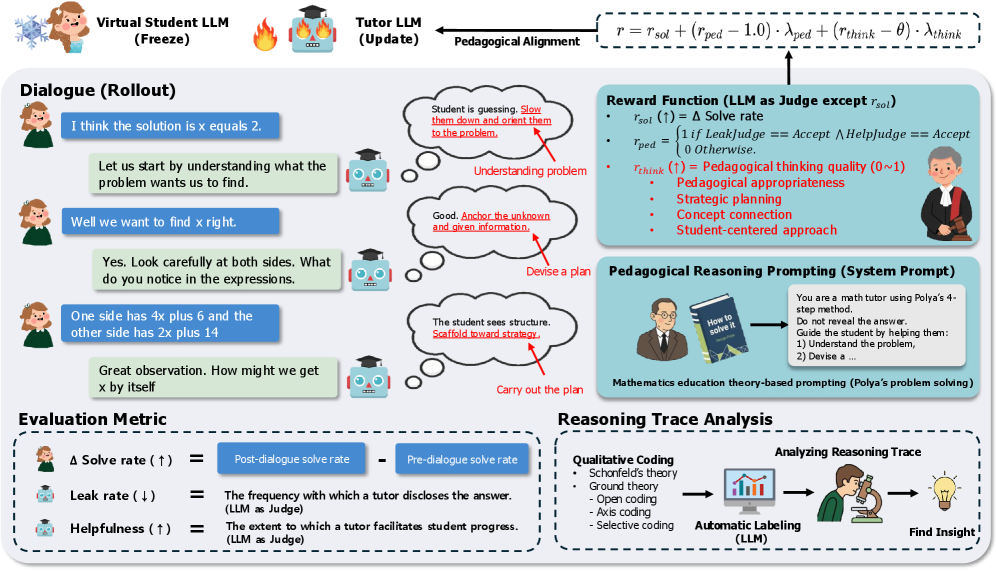
技术框架:PedagogicalRL-Thinking框架包含两个主要组成部分:教学推理提示和思维奖励。首先,使用教学推理提示来引导LLM的内部推理过程,这些提示基于领域特定的教育理论,例如认知负荷理论或支架式教学。然后,使用思维奖励来评估和加强模型推理轨迹的教学质量。这个奖励函数会评估模型推理过程中的教学策略,例如是否提供了清晰的解释、是否使用了适当的例子以及是否考虑了学生的认知水平。整个框架通过强化学习进行训练,目标是最大化模型在教学任务中的表现。
关键创新:该论文的关键创新在于将教学理论融入到LLM的推理过程中。与以往只关注生成高质量答案的方法不同,该论文显式地引导和奖励LLM进行符合教育理论的推理。这种方法使得LLM不仅能给出正确的答案,还能以一种教学有效的方式进行思考和解释,从而提高了LLM在教学场景中的实用性。此外,思维奖励的引入使得模型能够学习到更细粒度的教学策略,从而提高了教学效果。
关键设计:教学推理提示的设计基于领域特定的教育理论,例如认知负荷理论或支架式教学。思维奖励函数的设计需要仔细考虑各种教学策略的权重,例如清晰解释、适当例子和学生认知水平。强化学习算法的选择也很重要,论文可能使用了策略梯度方法或Q-learning等算法。具体的参数设置,例如学习率、奖励折扣因子等,需要根据实验结果进行调整。
🖼️ 关键图片
📊 实验亮点
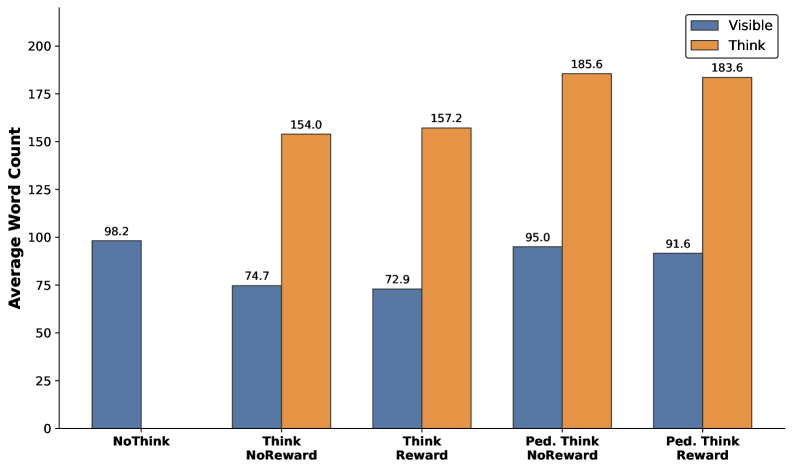
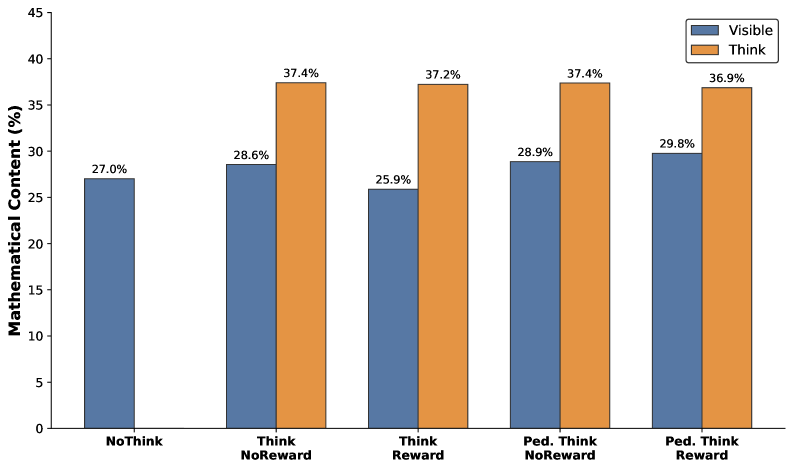
实验结果表明,领域特定的、基于理论的提示优于通用提示,并且思维奖励与教学提示相结合时效果最佳。仅在数学辅导对话中训练的模型在未见过的教育基准测试中表现出改进,同时保留了基础模型的事实知识。定量和定性分析表明,教学思维奖励能够系统地改变推理轨迹,增加教学推理,并在导师的思考过程中形成更结构化的教学决策。
🎯 应用场景
该研究成果可应用于智能辅导系统、在线教育平台和个性化学习工具等领域。通过提升LLM的教学推理能力,可以为学生提供更有效、更个性化的学习体验。此外,该方法还可以推广到其他领域,例如医疗诊断和法律咨询,以提升LLM在这些领域的决策能力和解释能力。
📄 摘要(原文)
Large language models (LLMs) are increasingly deployed as intelligent tutoring systems, yet research on optimizing LLMs specifically for educational contexts remains limited. Recent works have proposed reinforcement learning approaches for training LLM tutors, but these methods focus solely on optimizing visible responses while neglecting the model's internal thinking process. We introduce PedagogicalRL-Thinking, a framework that extends pedagogical alignment to reasoning LLMs in education through two novel approaches: (1) Pedagogical Reasoning Prompting, which guides internal reasoning using domain-specific educational theory rather than generic instructions; and (2) Thinking Reward, which explicitly evaluates and reinforces the pedagogical quality of the model's reasoning traces. Our experiments reveal that domain-specific, theory-grounded prompting outperforms generic prompting, and that Thinking Reward is most effective when combined with pedagogical prompting. Furthermore, models trained only on mathematics tutoring dialogues show improved performance on educational benchmarks not seen during training, while preserving the base model's factual knowledge. Our quantitative and qualitative analyses reveal that pedagogical thinking reward produces systematic reasoning trace changes, with increased pedagogical reasoning and more structured instructional decision-making in the tutor's thinking process.