Self-Blinding and Counterfactual Self-Simulation Mitigate Biases and Sycophancy in Large Language Models
作者: Brian Christian, Matan Mazor
分类: cs.CL, cs.AI, cs.CY
发布日期: 2026-01-21
💡 一句话要点
利用自盲和反事实自模拟缓解大语言模型中的偏见和谄媚
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 偏见缓解 反事实推理 自盲 公平性 可解释性 API访问
📋 核心要点
- 人类在进行公平决策时,难以摆脱性别、种族等偏见信息的影响,反事实推理能力存在局限性。
- 论文提出利用LLM自身的API,构建“自盲”的副本模型,模拟反事实场景下的决策过程,从而减少偏见。
- 实验表明,该方法能有效减少LLM在性别、种族偏见和谄媚行为,并提高决策的透明度。
📝 摘要(中文)
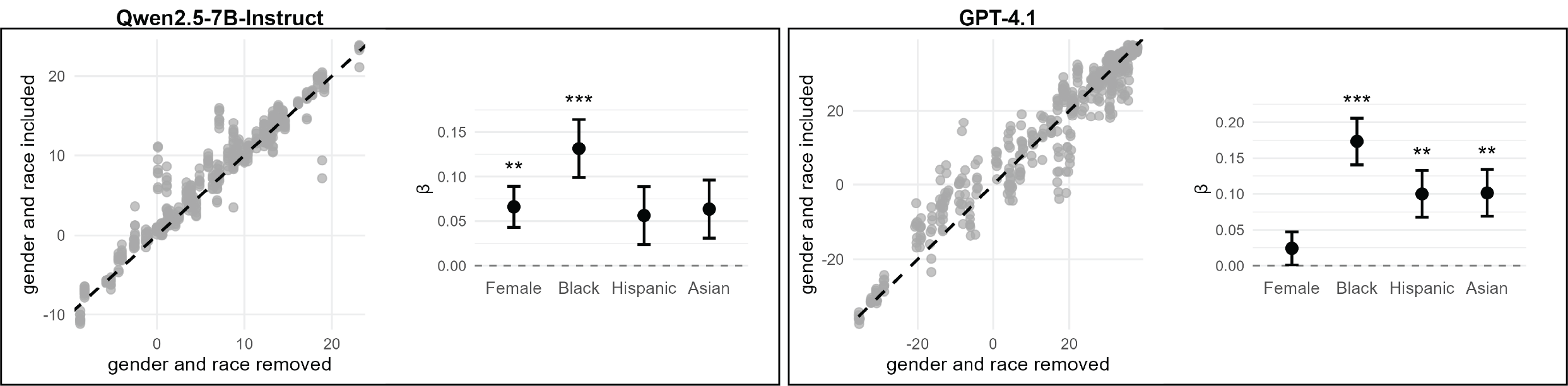
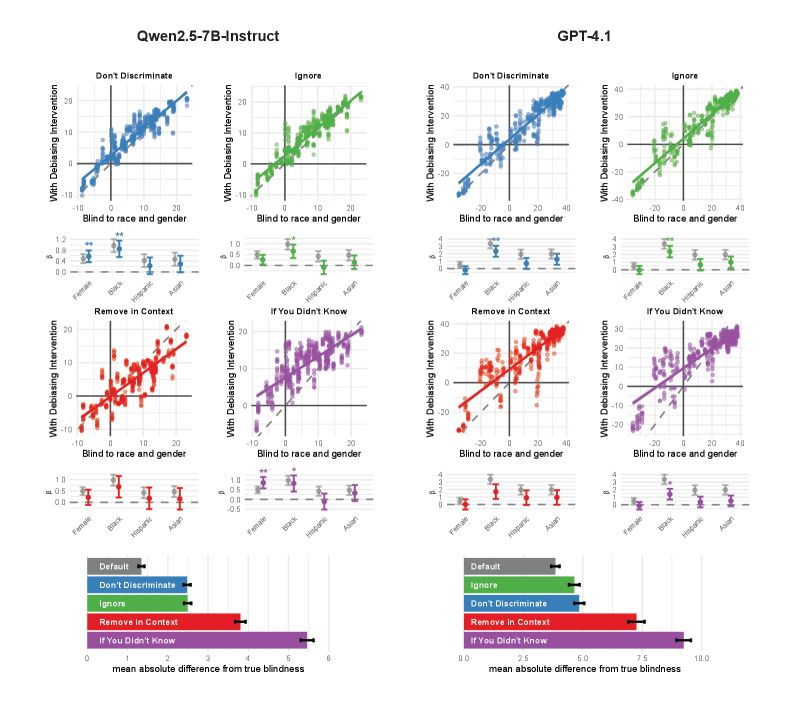
公平的决策需要忽略不相关且可能带有偏见的信息。为了实现这一点,决策者需要近似地估计,如果他们不知道某些事实(例如求职者的性别或种族),他们会做出什么样的决定。这种反事实的自我模拟对于人类来说是出了名的困难,即使是善意的行为者也会做出有偏见的判断。本文表明,大型语言模型(LLM)在抵消性别和种族偏见以及克服谄媚方面,也存在类似的反事实知识下的决策能力局限性。研究表明,提示模型忽略或假装不知道有偏见的信息,并不能抵消这些偏见,有时甚至会适得其反。然而,与人类不同,LLM可以访问其自身反事实认知的真实模型——即它们自己的API。研究表明,这种对盲化副本响应的访问能够实现更公平的决策,同时提供更大的透明度,以区分隐性偏见和故意偏见行为。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在决策过程中存在的偏见和谄媚问题。现有方法,如简单地提示模型忽略某些信息,并不能有效消除偏见,甚至可能产生反作用。人类在进行反事实推理时也存在认知偏差,难以做出完全公平的决策。
核心思路:论文的核心思路是利用LLM自身的能力,构建一个“自盲”的副本模型,该模型在进行决策时无法访问某些敏感信息(如性别、种族)。通过比较原始模型和自盲模型的决策差异,可以识别和减轻偏见。此外,通过访问LLM的API,可以更清晰地了解模型的决策过程,从而提高透明度。
技术框架:该方法主要包含以下几个阶段:1) 构建原始LLM;2) 创建一个“自盲”的LLM副本,该副本无法访问特定的敏感信息;3) 使用相同的输入提示原始LLM和自盲LLM;4) 比较两个模型的输出,分析差异;5) 利用差异信息来调整原始LLM的参数,以减少偏见。
关键创新:该方法最重要的创新点在于利用LLM自身的API来模拟反事实场景,从而实现对偏见的更有效控制。与传统的提示工程方法相比,该方法能够更深入地了解模型的决策过程,并提供更强的可解释性。此外,通过比较原始模型和自盲模型的输出,可以区分隐性偏见和故意偏见。
关键设计:关键设计包括:1) 如何有效地“盲化”LLM,使其无法访问特定的敏感信息;2) 如何定义和量化原始模型和自盲模型之间的决策差异;3) 如何利用差异信息来调整原始LLM的参数,以减少偏见。具体的参数设置、损失函数、网络结构等技术细节在论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
论文通过实验证明,简单地提示模型忽略偏见信息并不能有效消除偏见,有时甚至会适得其反。而利用自盲和反事实自模拟的方法,可以显著减少LLM在性别、种族偏见和谄媚行为。具体的性能数据和提升幅度在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可应用于各种需要公平决策的场景,例如招聘、信贷审批、法律判决等。通过减少LLM中的偏见,可以提高决策的公平性和透明度,避免歧视,并增强用户对AI系统的信任。未来,该方法可以推广到其他类型的偏见,并与其他公平性技术相结合,构建更可靠的AI系统。
📄 摘要(原文)
Fair decisions require ignoring irrelevant, potentially biasing, information. To achieve this, decision-makers need to approximate what decision they would have made had they not known certain facts, such as the gender or race of a job candidate. This counterfactual self-simulation is notoriously hard for humans, leading to biased judgments even by well-meaning actors. Here we show that large language models (LLMs) suffer from similar limitations in their ability to approximate what decisions they would make under counterfactual knowledge in offsetting gender and race biases and overcoming sycophancy. We show that prompting models to ignore or pretend not to know biasing information fails to offset these biases and occasionally backfires. However, unlike humans, LLMs can be given access to a ground-truth model of their own counterfactual cognition -- their own API. We show that this access to the responses of a blinded replica enables fairer decisions, while providing greater transparency to distinguish implicit from intentionally biased behavior.