From Quotes to Concepts: Axial Coding of Political Debates with Ensemble LMs
作者: Angelina Parfenova, David Graus, Juergen Pfeffer
分类: cs.CL
发布日期: 2026-01-20
备注: Accepted to ECIR2026
💡 一句话要点
利用集成语言模型对政治辩论进行轴向编码,实现从引言到概念的转换
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 轴向编码 大型语言模型 政治辩论分析 文本挖掘 自然语言处理
📋 核心要点
- 传统定性分析方法轴向编码依赖人工,效率低且主观性强,缺乏自动化工具。
- 提出一种基于集成LLM的轴向编码方法,将开放编码自动分组为高阶类别,构建辩论记录的层次化表示。
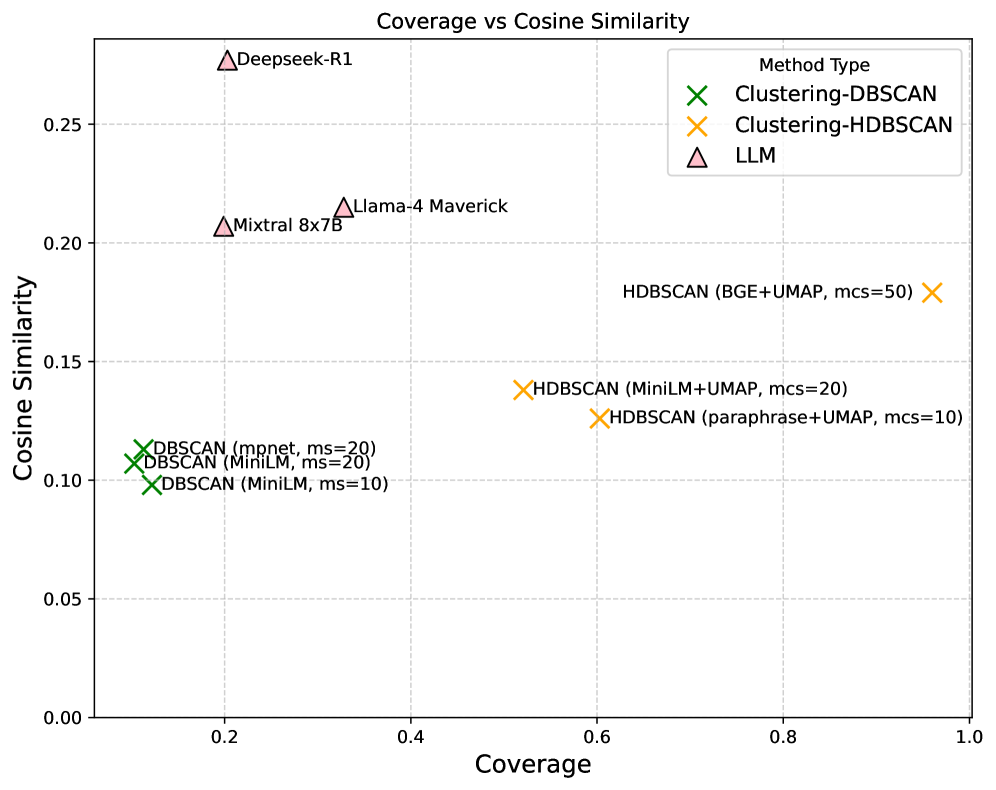
- 实验表明,聚类方法覆盖率高,LLM分组方法类别更简洁,语义对齐更好,各有优劣。
📝 摘要(中文)
本文利用大型语言模型(LLM)实现了轴向编码,这是一种常用的定性分析方法,通过将句子级别的开放编码组织成更广泛的类别来增强文档理解。本文扩展了一种基于集成的开放编码方法,并引入了LLM协调器,增加了一个轴向编码步骤,将开放编码分组为更高阶的类别,从而将原始辩论记录转换为简洁的、分层结构化的表示。我们比较了两种策略:(i)使用基于密度和划分的算法对代码-话语对的嵌入进行聚类,然后进行LLM标记;(ii)直接使用LLM将代码和话语分组到类别中。我们将该方法应用于荷兰议会辩论,将冗长的记录转换为紧凑的、分层结构化的代码和类别。我们使用与人工分配的主题标签对齐的外部指标(ROUGE-L、余弦相似度、BERTScore)和描述代码组的内部指标(覆盖率、简洁性、连贯性、新颖性、JSD散度)来评估我们的方法。结果表明存在一种权衡:基于密度的聚类实现了高覆盖率和强大的聚类对齐,而直接LLM分组产生了更高的细粒度对齐,但覆盖率降低了20%。总体而言,聚类最大限度地提高了覆盖率和结构分离,而LLM分组产生了更简洁、可解释和语义对齐的类别。为了支持未来的研究,我们公开发布了完整的语料和代码数据集,以实现可重复性和比较研究。
🔬 方法详解
问题定义:论文旨在解决政治辩论等长文本的理解和分析问题。现有方法,特别是人工轴向编码,耗时耗力,且结果受分析者主观影响。缺乏自动化的、可扩展的方法将句子级别的开放编码组织成更高层次的概念类别,从而实现对辩论内容更简洁、结构化的理解。
核心思路:论文的核心思路是利用大型语言模型(LLM)的语义理解和生成能力,自动化轴向编码过程。通过将开放编码和对应的文本片段输入LLM,让LLM学习并归纳出更高层次的类别,从而将原始文本转化为更易于理解和分析的结构化表示。这种方法旨在减少人工干预,提高分析效率,并降低主观偏差。
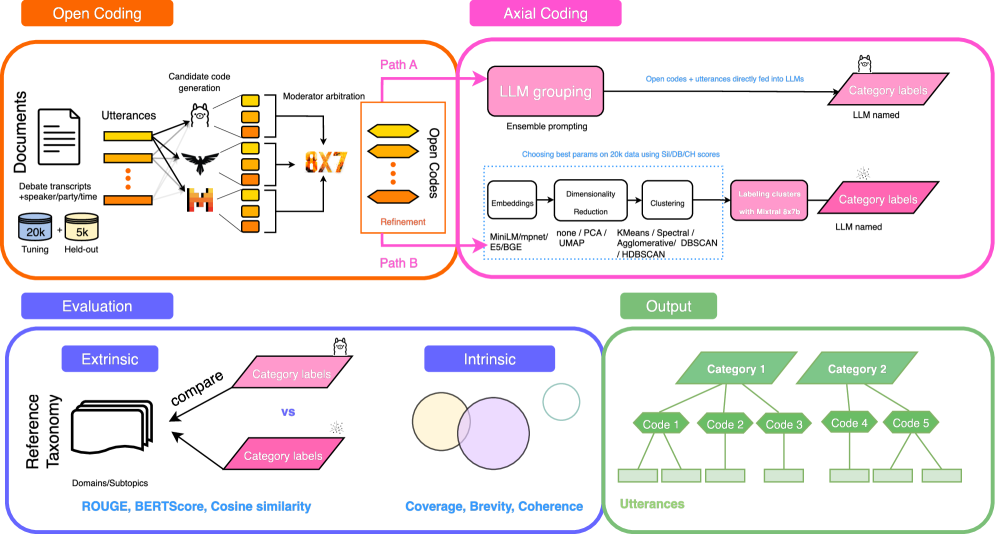
技术框架:整体框架包含以下几个主要阶段: 1. 开放编码:使用现有的基于集成的开放编码方法,将辩论文本分割成句子,并为每个句子分配一个或多个开放编码。 2. 轴向编码:这是论文的核心创新部分,包含两种策略: * 聚类+LLM标注:首先,将代码-话语对嵌入到向量空间中,然后使用密度聚类(如DBSCAN)或划分聚类(如K-means)算法对嵌入向量进行聚类。然后,使用LLM为每个聚类生成一个描述性的标签,作为该聚类的类别。 * 直接LLM分组:直接将代码和话语输入LLM,让LLM根据语义相似性将它们分组到不同的类别中,并为每个类别生成一个描述性的标签。 3. 评估:使用外部指标(如ROUGE-L、余弦相似度、BERTScore)和内部指标(如覆盖率、简洁性、连贯性、新颖性、JSD散度)来评估不同方法的性能。
关键创新:最重要的技术创新点在于将LLM引入到轴向编码过程中,实现了轴向编码的自动化。与传统的人工方法相比,该方法可以显著提高分析效率,并降低主观偏差。此外,论文还比较了两种不同的LLM应用策略(聚类+LLM标注 vs. 直接LLM分组),并分析了它们的优缺点。
关键设计: * LLM选择:论文中使用的LLM的具体型号未知。 * 嵌入方法:代码-话语对的嵌入方法未知。 * 聚类算法:使用了DBSCAN和K-means等聚类算法,具体参数设置未知。 * LLM提示工程:如何设计LLM的提示语,以引导LLM生成高质量的类别标签,具体细节未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于密度聚类的轴向编码方法具有较高的覆盖率和结构分离性,而直接使用LLM进行分组的方法能够产生更简洁、可解释和语义对齐的类别。虽然直接LLM分组的覆盖率略有下降(20%),但在细粒度对齐方面表现更好。该研究揭示了不同方法之间的权衡,为实际应用中选择合适的方法提供了指导。
🎯 应用场景
该研究成果可广泛应用于政治学、社会学、传播学等领域,用于分析政治辩论、新闻报道、社交媒体内容等。通过自动化的轴向编码,研究人员可以更高效地理解和分析大规模文本数据,从而发现隐藏在文本中的模式和趋势,为政策制定、舆情分析等提供支持。
📄 摘要(原文)
Axial coding is a commonly used qualitative analysis method that enhances document understanding by organizing sentence-level open codes into broader categories. In this paper, we operationalize axial coding with large language models (LLMs). Extending an ensemble-based open coding approach with an LLM moderator, we add an axial coding step that groups open codes into higher-order categories, transforming raw debate transcripts into concise, hierarchical representations. We compare two strategies: (i) clustering embeddings of code-utterance pairs using density-based and partitioning algorithms followed by LLM labeling, and (ii) direct LLM-based grouping of codes and utterances into categories. We apply our method to Dutch parliamentary debates, converting lengthy transcripts into compact, hierarchically structured codes and categories. We evaluate our method using extrinsic metrics aligned with human-assigned topic labels (ROUGE-L, cosine, BERTScore), and intrinsic metrics describing code groups (coverage, brevity, coherence, novelty, JSD divergence). Our results reveal a trade-off: density-based clustering achieves high coverage and strong cluster alignment, while direct LLM grouping results in higher fine-grained alignment, but lower coverage 20%. Overall, clustering maximizes coverage and structural separation, whereas LLM grouping produces more concise, interpretable, and semantically aligned categories. To support future research, we publicly release the full dataset of utterances and codes, enabling reproducibility and comparative studies.