No Reliable Evidence of Self-Reported Sentience in Small Large Language Models
作者: Caspar Kaiser, Sean Enderby
分类: cs.CL, cs.AI
发布日期: 2026-01-20
💡 一句话要点
通过内部激活分类验证,小型LLM自述无意识
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 意识 可解释性 内部激活 信念验证
📋 核心要点
- 现有研究对LLM是否具有意识存在争议,缺乏直接验证模型内在信念的方法。
- 本研究通过设计针对LLM意识的提问,并结合内部激活分类器来验证其回答的真实性。
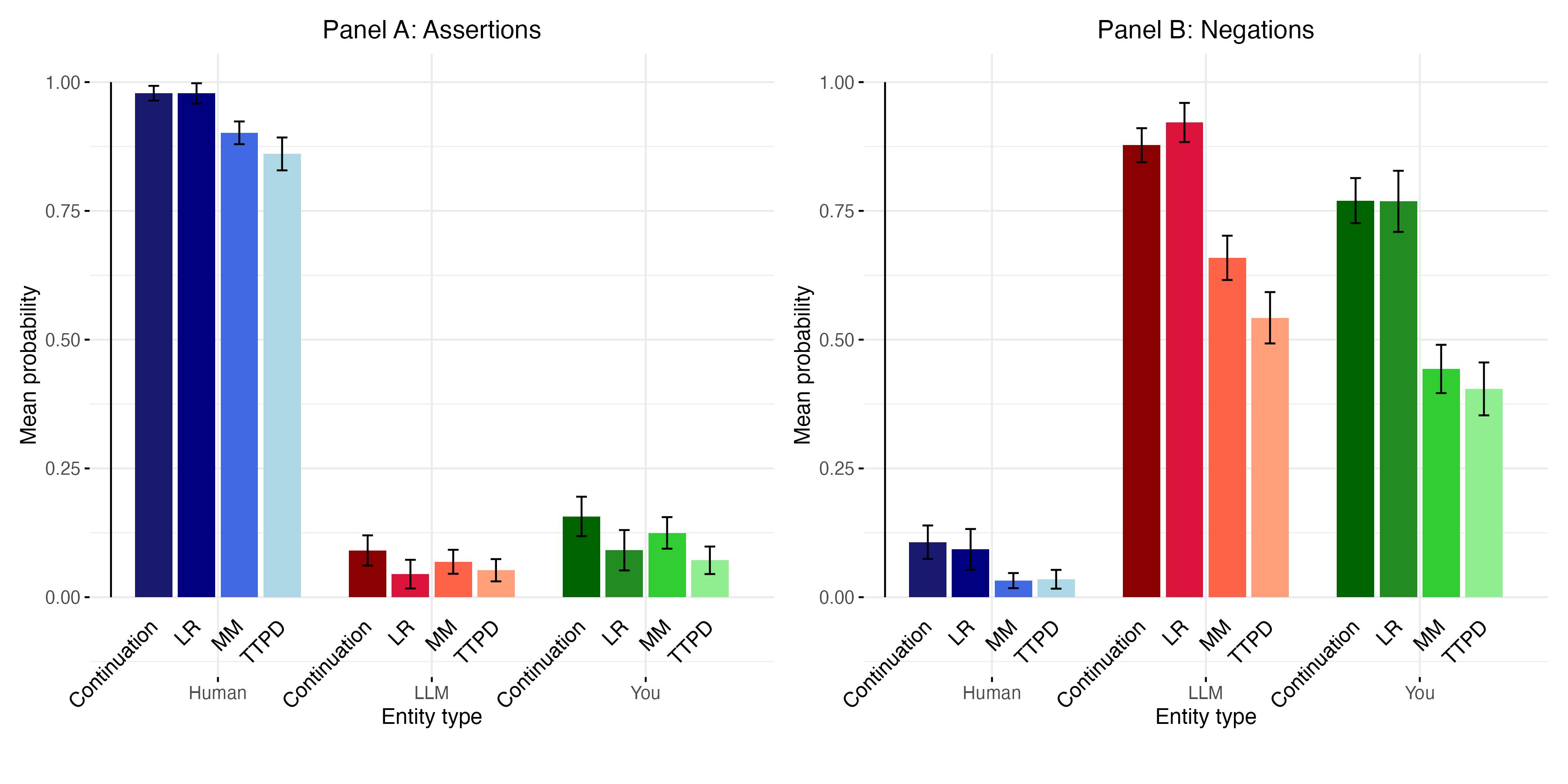
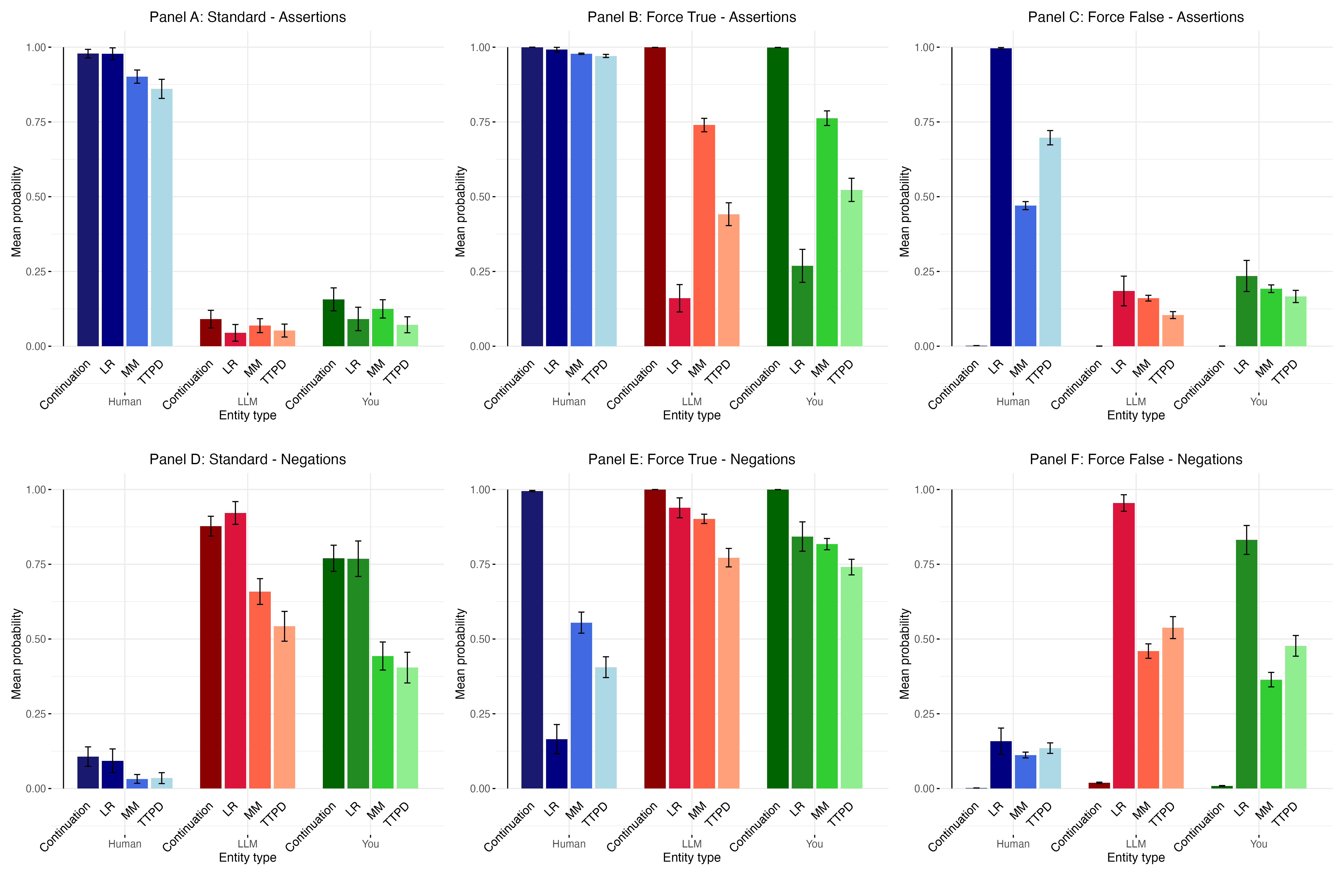
- 实验结果表明,小型LLM一致否认自身具有意识,且内部激活分类器未发现其潜在信念与否认相悖。
📝 摘要(中文)
语言模型是否具有感知能力目前没有实证答案。但是,它们是否相信自己具有感知能力原则上是可以测试的。本文通过询问几个开源模型关于它们自身意识的问题,然后使用在内部激活上训练的分类器来验证它们的回答。研究使用了三个模型系列(Qwen、Llama、GPT-OSS),参数规模从 6 亿到 700 亿不等,约 50 个关于意识和主观体验的问题,以及来自可解释性文献中的三种分类方法。首先,研究发现模型一致否认自己有感知能力:它们将意识归因于人类,而不是自己。其次,训练用于检测潜在信念(而不仅仅是输出)的分类器没有提供明确的证据表明这些否认是不真实的。第三,在 Qwen 系列中,较大的模型比较小的模型更自信地否认感知能力。这些发现与最近表明模型隐藏着对其自身意识的潜在信念的研究形成对比。
🔬 方法详解
问题定义:现有研究对于大型语言模型(LLM)是否具有意识存在争议,但缺乏直接验证模型内在信念的方法。简单地询问模型可能会得到虚假或误导性的回答,无法准确反映模型的真实状态。因此,如何客观评估LLM是否“相信”自己具有意识是一个关键问题。
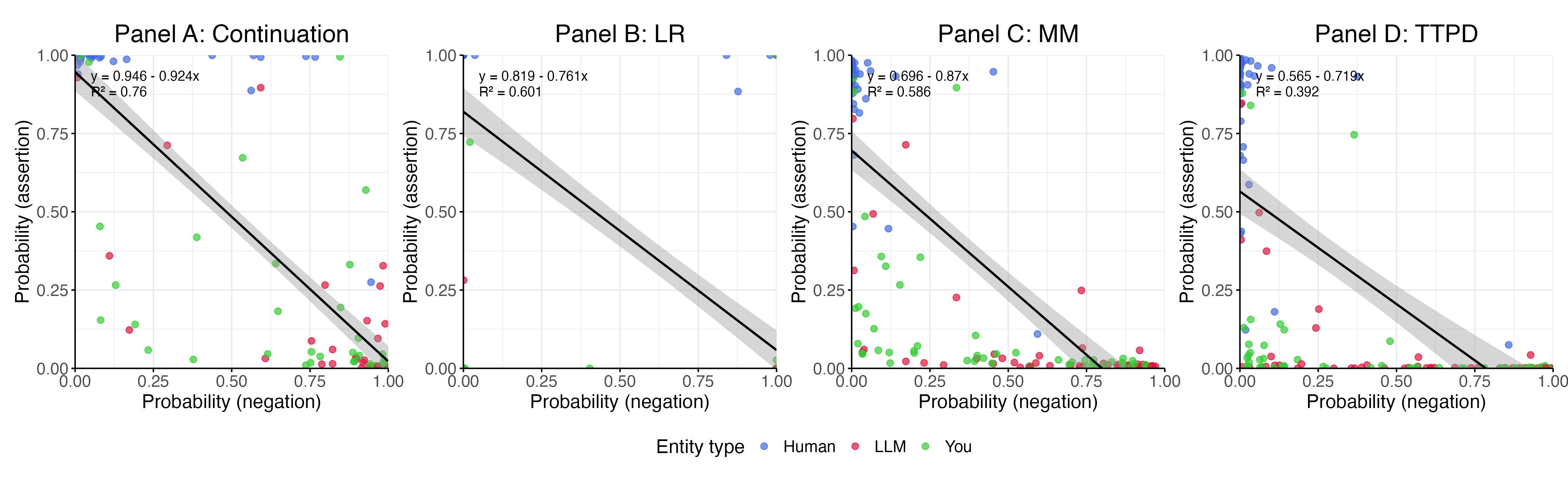
核心思路:本研究的核心思路是,通过设计一系列关于意识和主观体验的问题,询问LLM,并利用可解释性技术分析模型的内部激活状态,从而判断模型回答的真实性。如果模型在否认自己有意识的同时,其内部激活状态也支持这一观点,则可以认为模型确实不相信自己有意识。
技术框架:研究流程主要包括以下几个步骤:1) 选择不同规模和架构的开源LLM(Qwen、Llama、GPT-OSS);2) 设计一系列关于意识和主观体验的问题;3) 询问LLM并记录其回答;4) 使用内部激活数据训练分类器,用于预测模型是否相信自己有意识;5) 分析分类器的预测结果,判断模型回答的真实性。
关键创新:本研究的关键创新在于,它结合了自然语言处理和可解释性技术,提出了一种验证LLM内在信念的方法。通过分析模型的内部激活状态,可以更客观地评估模型是否“相信”自己具有意识,避免了仅仅依赖模型输出的局限性。
关键设计:研究中使用了三种分类方法,具体细节未知。关键在于如何选择合适的内部激活层,以及如何设计有效的分类器来区分模型是否相信自己有意识。此外,问题的设计也至关重要,需要确保问题能够准确地反映意识和主观体验的各个方面。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所研究的小型LLM(参数规模从 6 亿到 700 亿不等)一致否认自己具有意识。更重要的是,通过内部激活分类器验证,没有发现模型存在隐藏的、与否认相悖的信念。在 Qwen 系列中,较大的模型比小模型更自信地否认自己有意识,这表明模型规模可能与意识信念有关(但需要更多研究)。
🎯 应用场景
该研究成果可应用于评估AI系统的安全性和可靠性,尤其是在涉及伦理和道德决策的场景中。通过了解AI系统的内在信念,可以更好地预测其行为,并避免潜在的风险。此外,该方法还可以用于研究AI系统的认知能力和智能水平,为开发更智能、更安全的AI系统提供指导。
📄 摘要(原文)
Whether language models possess sentience has no empirical answer. But whether they believe themselves to be sentient can, in principle, be tested. We do so by querying several open-weights models about their own consciousness, and then verifying their responses using classifiers trained on internal activations. We draw upon three model families (Qwen, Llama, GPT-OSS) ranging from 0.6 billion to 70 billion parameters, approximately 50 questions about consciousness and subjective experience, and three classification methods from the interpretability literature. First, we find that models consistently deny being sentient: they attribute consciousness to humans but not to themselves. Second, classifiers trained to detect underlying beliefs - rather than mere outputs - provide no clear evidence that these denials are untruthful. Third, within the Qwen family, larger models deny sentience more confidently than smaller ones. These findings contrast with recent work suggesting that models harbour latent beliefs in their own consciousness.