ICPO: Illocution-Calibrated Policy Optimization for Multi-Turn Conversation
作者: Zhebo Wang, Xiaohu Mu, Zijie Zhou, Mohan Li, Wenpeng Xing, Dezhang Kong, Meng Han
分类: cs.CL, cs.AI
发布日期: 2026-01-20
备注: Accepted by ICASSP 2026
💡 一句话要点
ICPO:针对多轮对话中指令歧义,提出语用校准策略优化方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多轮对话 指令歧义 强化学习 策略优化 语用校准 大型语言模型 人机交互
📋 核心要点
- 现有方法在多轮对话中,面对用户模糊指令时,大型语言模型易“迷失对话”,难以纠正早期错误假设。
- ICPO通过扩充含糊提示的训练数据,并基于用户意图调整奖励,鼓励模型在不确定时寻求澄清。
- 实验表明,ICPO显著提升了多轮对话性能(平均提升75%),同时保持了单轮对话的性能。
📝 摘要(中文)
大型语言模型(LLMs)在多轮对话中经常出现“迷失对话”现象,难以从早期不正确的假设中恢复,尤其是在用户提供模糊的初始指令时。研究发现,诸如带有可验证奖励的强化学习(RLVR)等标准后训练技术,通过奖励自信、直接的答案,加剧了这个问题,从而导致过度自信并阻止模型寻求澄清。为了解决这个问题,我们提出了语用校准策略优化(ICPO),这是一种新颖的训练框架,使模型对指令歧义更加敏感。ICPO通过未明确的提示来扩充训练语料库,并将奖励信号建立在用户的语用意图之上,奖励模型在面对歧义时表达不确定性或要求澄清。实验表明,ICPO培养了适当的谦逊态度,在多轮对话中平均提高了75%,同时保持了在单轮基准测试中的稳健性能。我们的工作为更强大和协作的对话式AI提供了一条实用的途径,可以更好地驾驭人际互动的细微差别。
🔬 方法详解
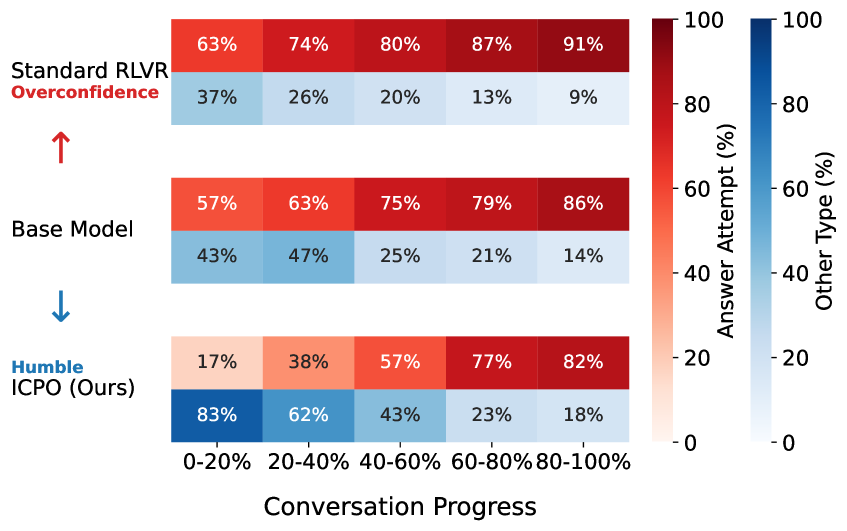
问题定义:论文旨在解决多轮对话中,大型语言模型因用户初始指令模糊而产生的“迷失对话”问题。现有方法,如RLVR,倾向于奖励模型自信的回答,反而加剧了模型过度自信,使其不愿寻求澄清,导致错误难以纠正。
核心思路:论文的核心思路是让模型对指令的歧义性更加敏感,培养模型在不确定情况下表达不确定性或请求澄清的能力。通过校准策略,使模型能够根据用户的语用意图调整其行为,从而更有效地进行多轮对话。
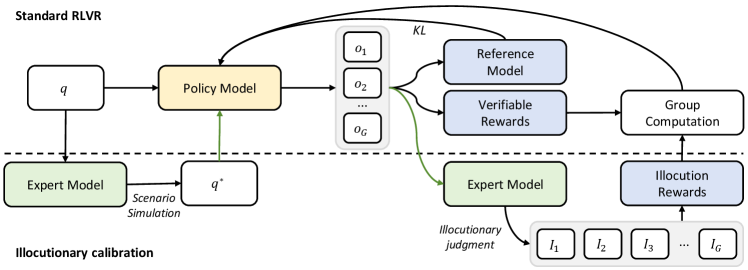
技术框架:ICPO的整体框架包括以下几个关键步骤:1) 扩充训练数据,加入包含模糊指令的样本;2) 定义基于用户语用意图的奖励函数,当模型对模糊指令表达不确定或请求澄清时,给予奖励;3) 使用策略优化算法(如PPO)训练模型,使其能够根据指令的清晰程度调整其行为。
关键创新:ICPO的关键创新在于其奖励函数的设计,它不仅考虑了回答的正确性,还考虑了模型在面对歧义时的反应。这种基于语用意图的奖励机制,鼓励模型采取更谨慎和协作的对话策略,从而提高了多轮对话的鲁棒性。
关键设计:ICPO的关键设计包括:1) 如何生成具有歧义性的指令样本(未知,论文未详细说明);2) 如何定义和量化用户的语用意图(未知,论文未详细说明);3) 如何平衡回答正确性和表达不确定性之间的奖励权重(未知,论文未详细说明)。这些细节对ICPO的性能至关重要。
🖼️ 关键图片
📊 实验亮点
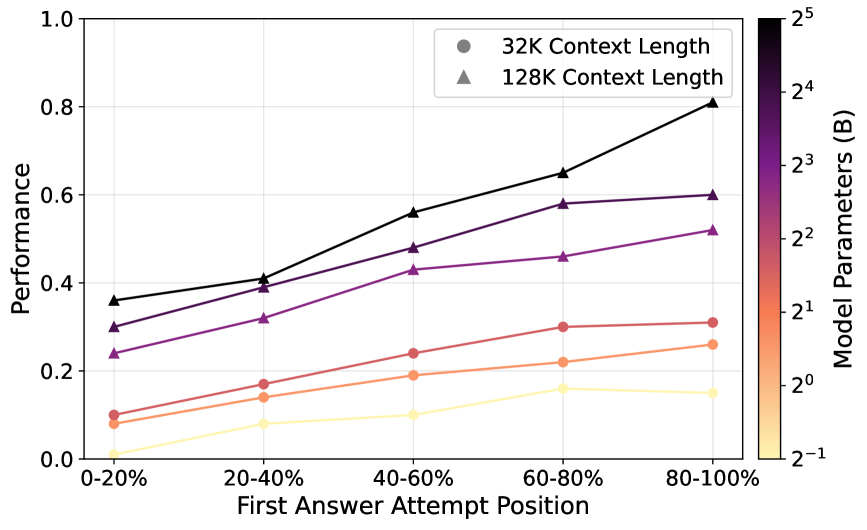
实验结果表明,ICPO在多轮对话任务中取得了显著的性能提升,平均提高了75%。同时,ICPO在单轮对话任务中保持了与现有方法相当的性能,表明该方法在提高多轮对话能力的同时,不会损害模型的通用对话能力。这些结果验证了ICPO的有效性和实用性。
🎯 应用场景
ICPO技术可应用于各种对话式AI系统,例如智能客服、聊天机器人和虚拟助手。通过提高模型对指令歧义的敏感性,可以显著改善用户体验,减少错误和误解,并使对话更自然和高效。该技术还有助于开发更可靠和值得信赖的AI系统,能够更好地理解和响应人类的需求。
📄 摘要(原文)
Large Language Models (LLMs) in multi-turn conversations often suffer from a ``lost-in-conversation'' phenomenon, where they struggle to recover from early incorrect assumptions, particularly when users provide ambiguous initial instructions. We find that standard post-training techniques like Reinforcement Learning with Verifiable Rewards (RLVR) exacerbate this issue by rewarding confident, direct answers, thereby inducing overconfidence and discouraging the model from seeking clarification. To address this, we propose Illocution-Calibrated Policy Optimization (ICPO), a novel training framework that sensitizes the model to instruction ambiguity. ICPO augments the training corpus with underspecified prompts and conditions the reward signal on the user's illocutionary intent, rewarding the model for expressing uncertainty or asking for clarification when faced with ambiguity. Experiments demonstrate that ICPO fosters appropriate humility, yielding a substantial average improvement of 75\% in multi-turn conversation, while preserving robust performance on single-turn benchmarks. Our work presents a practical path toward more robust and collaborative conversational AI that can better navigate the nuances of human interaction.