Can LLM Reasoning Be Trusted? A Comparative Study: Using Human Benchmarking on Statistical Tasks
作者: Crish Nagarkar, Leonid Bogachev, Serge Sharoff
分类: cs.CL
发布日期: 2026-01-20
💡 一句话要点
微调LLM提升统计推理能力,可用于教育和自动化评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 统计推理 微调 自动化评估 教育技术
📋 核心要点
- 现有LLM在统计任务中能力不足,尤其是在推理质量评估方面存在挑战。
- 通过在专门构建的数据集上微调开源LLM,提升其统计推理能力。
- 实验表明,微调后的模型在统计任务上达到统计学学生水平,且能更好评估答案质量。
📝 摘要(中文)
本文研究了大型语言模型(LLM)解决统计任务以及评估推理质量的能力。尽管当前最先进的LLM在各种NLP任务中表现出色,但它们在应对中等复杂度的统计挑战方面的能力尚不清楚。我们专门开发了一个数据集,并在此基础上对选定的开源LLM进行了微调,以增强其统计推理能力,并将它们的性能与人工评分(作为基准)进行了比较。结果表明,微调后的模型在高级统计任务上的表现达到了统计学学生的水平。微调表现出架构相关的改进,一些模型显示出显著的性能提升,表明其在教育技术和统计分析辅助系统中的部署潜力。我们还表明,与传统的指标(如BLEU或BertScore)相比,LLM本身可以更好地判断答案的质量(包括解释和推理评估)。这种自我评估能力为统计教育平台的可扩展自动化评估以及自动化分析工具的质量保证提供了可能。潜在的应用还包括学术界和工业界研究方法的验证工具,以及数据分析工作流程的质量控制机制。
🔬 方法详解
问题定义:论文旨在解决LLM在统计任务中的推理能力不足的问题,尤其是在评估推理质量方面的不足。现有方法,如BLEU和BertScore,在评估统计推理的正确性和合理性方面表现不佳,无法准确反映LLM的真实能力。
核心思路:核心思路是通过在专门构建的统计数据集上对LLM进行微调,使其更好地理解和解决统计问题。此外,利用LLM自身的评估能力,判断答案的质量,包括解释和推理的合理性,从而实现更准确的自动化评估。
技术框架:整体框架包括以下几个阶段:1) 构建专门的统计数据集,包含各种难度级别的统计问题;2) 选择合适的开源LLM进行微调;3) 使用人工评分作为基准,评估微调后LLM的性能;4) 利用LLM自身评估答案质量,并与传统指标进行比较。
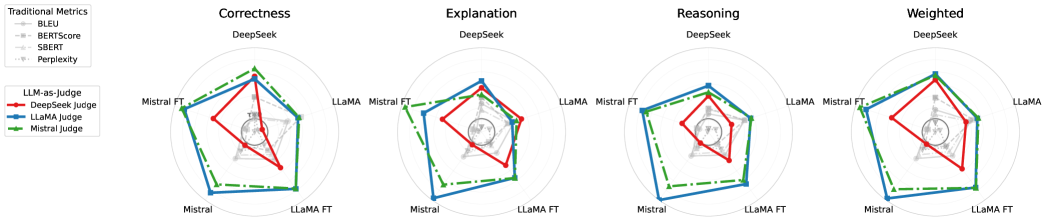
关键创新:最重要的创新点在于利用LLM自身进行答案质量评估。传统指标主要关注文本相似度,而LLM能够理解统计推理的逻辑,从而更准确地判断答案的正确性和合理性。这使得LLM能够胜任自动化评估的任务,并为教育平台和数据分析工具提供质量保证。
关键设计:论文中关键的设计包括:1) 数据集的构建,需要覆盖各种统计概念和难度级别;2) 模型选择,需要考虑模型的架构和预训练数据;3) 微调策略,需要选择合适的损失函数和优化器;4) 评估指标,需要综合考虑准确率、召回率和F1值等指标。
🖼️ 关键图片

📊 实验亮点
实验结果表明,经过微调的LLM在高级统计任务上的表现可以达到统计学学生的水平。此外,LLM自身评估答案质量的能力明显优于传统的BLEU和BertScore等指标,能够更准确地判断答案的正确性和合理性。不同架构的LLM在微调后表现出不同的性能提升,表明模型架构对统计推理能力有显著影响。
🎯 应用场景
该研究成果可应用于教育技术领域,例如构建智能统计辅导系统,为学生提供个性化的学习体验。此外,还可应用于自动化数据分析工具的质量控制,以及学术界和工业界研究方法的验证,提高数据分析的可靠性和效率。未来,该技术有望推动统计教育的普及和数据驱动决策的智能化。
📄 摘要(原文)
This paper investigates the ability of large language models (LLMs) to solve statistical tasks, as well as their capacity to assess the quality of reasoning. While state-of-the-art LLMs have demonstrated remarkable performance in a range of NLP tasks, their competence in addressing even moderately complex statistical challenges is not well understood. We have fine-tuned selected open-source LLMs on a specially developed dataset to enhance their statistical reasoning capabilities, and compared their performance with the human scores used as a benchmark. Our results show that the fine-tuned models achieve better performance on advanced statistical tasks on the level comparable to a statistics student. Fine-tuning demonstrates architecture-dependent improvements, with some models showing significant performance gains, indicating clear potential for deployment in educational technology and statistical analysis assistance systems. We also show that LLMs themselves can be far better judges of the answers quality (including explanation and reasoning assessment) in comparison to traditional metrics, such as BLEU or BertScore. This self-evaluation capability enables scalable automated assessment for statistical education platforms and quality assurance in automated analysis tools. Potential applications also include validation tools for research methodology in academic and industry settings, and quality control mechanisms for data analysis workflows.