Which Reasoning Trajectories Teach Students to Reason Better? A Simple Metric of Informative Alignment
作者: Yuming Yang, Mingyoung Lai, Wanxu Zhao, Xiaoran Fan, Zhiheng Xi, Mingqi Wu, Chiyue Huang, Jun Zhao, Haijun Lv, Jian Tong, Yunhua Zhou, Yicheng Zou, Qipeng Guo, Tao Gui, Qi Zhang, Xuanjing Huang
分类: cs.CL
发布日期: 2026-01-20
备注: 26 pages. Project page: https://github.com/UmeanNever/RankSurprisalRatio
💡 一句话要点
提出Rank-Surprisal Ratio (RSR)指标,用于评估推理轨迹对学生模型学习的有效性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 长链思维 推理轨迹 模型评估 Rank-Surprisal Ratio
📋 核心要点
- 现有方法在知识蒸馏中仅关注学生模型对轨迹的似然性,忽略了轨迹的信息量。
- 提出Rank-Surprisal Ratio (RSR)指标,综合考虑轨迹的对齐性和信息量,评估其对学生模型的价值。
- 实验表明RSR与学生模型训练后的性能高度相关,优于现有指标,并可用于轨迹和教师选择。
📝 摘要(中文)
长链思维(CoT)轨迹为从教师模型到学生LLM的推理知识蒸馏提供了丰富的监督信号。然而,先前工作和本文实验表明,来自更强教师模型的轨迹不一定能产生更好的学生模型,突出了数据-学生适配性的重要性。现有方法主要通过学生模型的似然性来评估适配性,倾向于与模型当前行为紧密对齐的轨迹,而忽略了更具信息量的轨迹。为此,本文提出Rank-Surprisal Ratio (RSR),这是一个简单的指标,可以同时捕获对齐性和信息量,以评估推理轨迹的适用性。RSR的动机是,有效的轨迹通常将低绝对概率与学生模型下相对高排名的token结合起来,从而平衡了学习信号强度和行为对齐。具体而言,RSR定义为轨迹的平均token排名与其平均负对数似然的比率,易于计算和解释。在五个学生模型和来自11个不同教师模型的推理轨迹中,RSR与训练后的性能高度相关(平均Spearman相关系数为0.86),优于现有指标。本文进一步证明了其在轨迹选择和教师选择中的实际效用。
🔬 方法详解
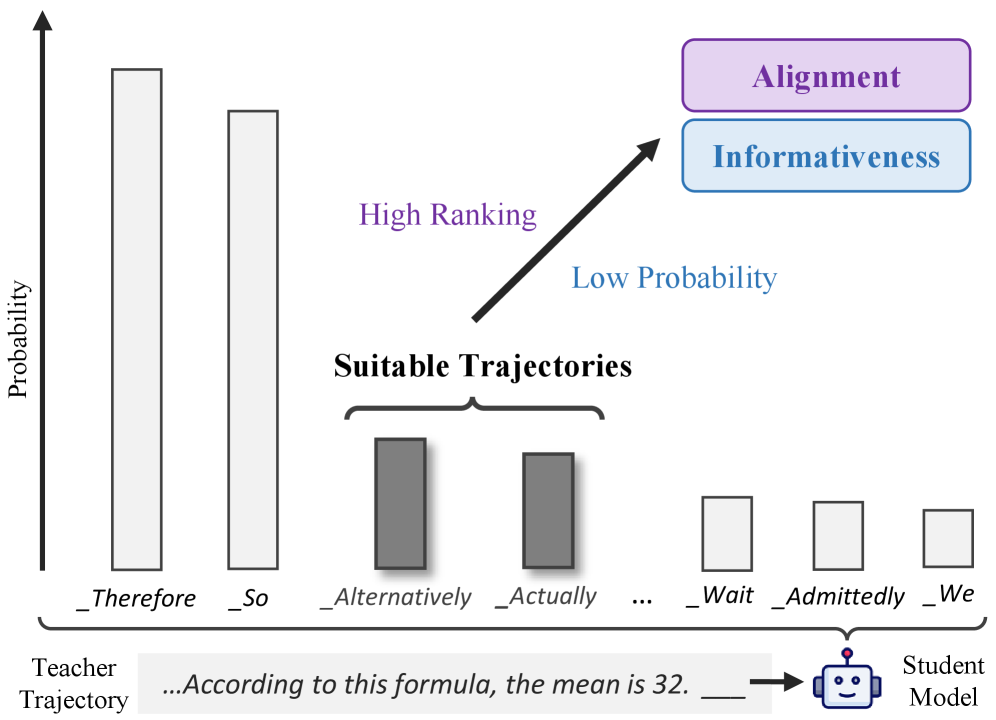
问题定义:现有的大语言模型知识蒸馏方法,特别是基于长链思维(CoT)的蒸馏,通常使用教师模型的推理轨迹来指导学生模型的学习。然而,简单地使用更强大的教师模型产生的轨迹并不一定能提升学生模型的性能。现有的评估轨迹质量的方法,例如基于学生模型似然性的方法,倾向于选择与学生模型当前行为更一致的轨迹,而忽略了那些虽然概率较低但包含更多信息的轨迹。这种方法的痛点在于无法有效区分信息量大但与学生模型当前认知存在偏差的轨迹,导致学生模型无法充分学习到教师模型的推理能力。
核心思路:本文的核心思路是提出一个能够同时衡量轨迹的对齐性和信息量的指标,即Rank-Surprisal Ratio (RSR)。RSR的出发点是,有效的推理轨迹应该既与学生模型的认知有一定的对齐,又包含一定的“惊喜”,即包含学生模型原本不太可能预测到的信息。通过平衡对齐性和信息量,RSR能够更准确地评估轨迹对学生模型的学习价值。
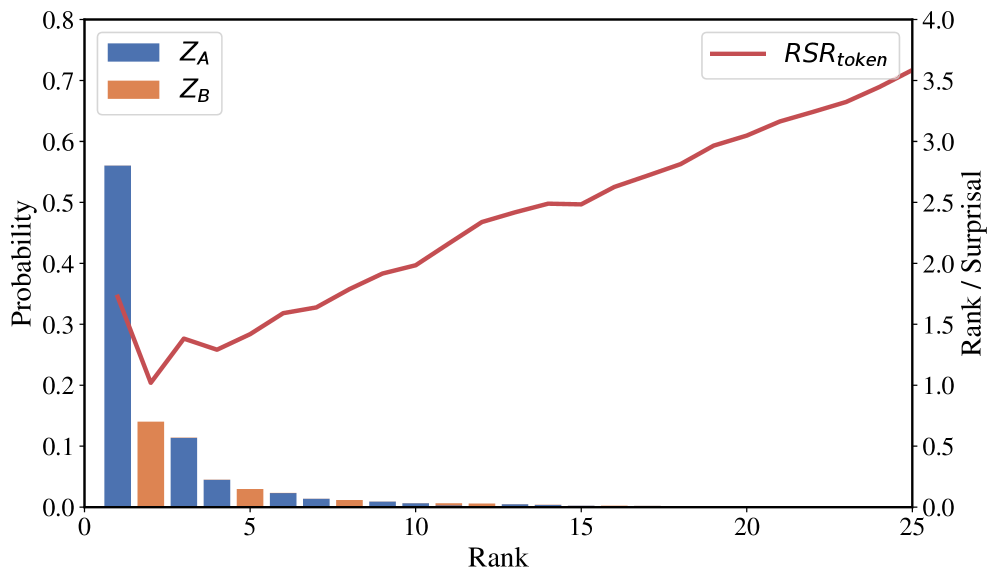
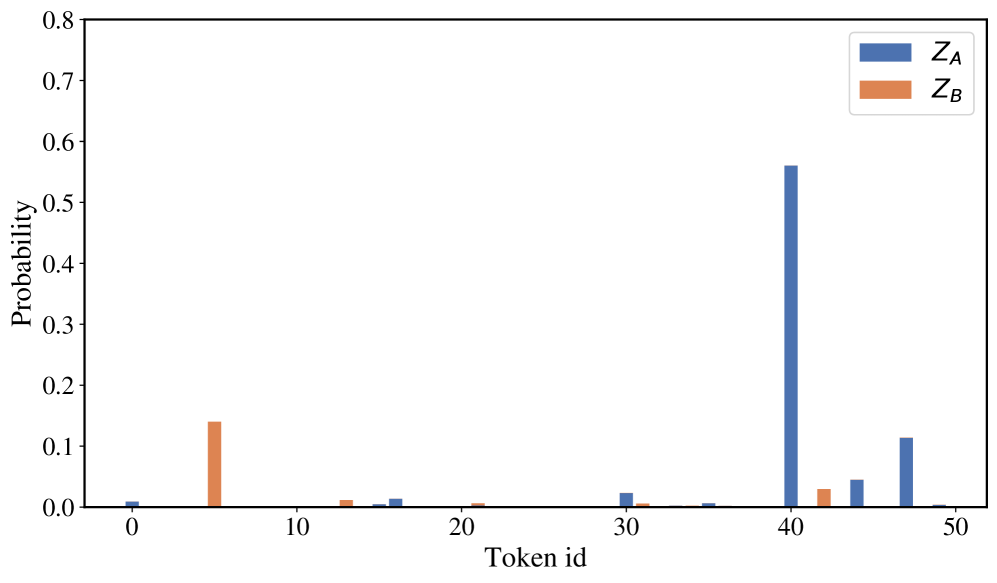
技术框架:RSR的计算非常简单,它基于学生模型对轨迹中每个token的预测结果。具体来说,对于一条推理轨迹,首先计算每个token在学生模型预测概率分布中的排名(Rank),然后计算每个token的负对数似然(Negative Log-Likelihood,NLL)。RSR定义为轨迹中所有token的平均排名与平均负对数似然的比值。整个流程包括:1. 获取教师模型的推理轨迹;2. 使用学生模型对轨迹中的每个token进行预测,得到概率分布;3. 计算每个token的排名和负对数似然;4. 计算整条轨迹的平均排名和平均负对数似然;5. 计算RSR值。
关键创新:RSR的关键创新在于它将token的排名信息引入到轨迹质量的评估中。传统的基于似然性的方法只关注学生模型预测的概率值,而忽略了排名信息。排名信息反映了学生模型对某个token的相对重视程度,即使一个token的概率值较低,但如果其排名较高,也说明学生模型认为该token仍然具有一定的可能性。通过结合排名和似然性,RSR能够更全面地评估轨迹的信息量和对齐性。与现有方法相比,RSR的本质区别在于它不仅仅关注学生模型“喜欢”什么样的轨迹,更关注什么样的轨迹能够帮助学生模型学习到新的知识。
关键设计:RSR的计算公式为:RSR = (Average Rank) / (Average Negative Log-Likelihood)。其中,Average Rank是轨迹中所有token的平均排名,Average Negative Log-Likelihood是轨迹中所有token的平均负对数似然。这个公式的设计非常简洁,易于计算和理解。没有涉及到复杂的参数设置或网络结构。关键在于如何有效地计算token的排名。在实际应用中,可以使用各种排序算法来计算token在学生模型预测概率分布中的排名。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RSR指标与学生模型训练后的性能具有高度相关性,平均Spearman相关系数达到0.86,显著优于现有的基于似然性的指标。在轨迹选择和教师选择任务中,使用RSR指标能够有效地提升学生模型的性能。例如,通过选择RSR值最高的轨迹进行训练,学生模型的准确率可以提升多个百分点。
🎯 应用场景
该研究成果可广泛应用于大语言模型的知识蒸馏领域,特别是基于长链思维的蒸馏。通过使用RSR指标,可以更有效地选择高质量的推理轨迹,从而提升学生模型的推理能力。此外,RSR还可以用于教师模型的选择,帮助研究人员找到最适合特定学生模型的教师模型。未来,该方法可以扩展到其他类型的知识蒸馏任务中,例如模型压缩和领域自适应。
📄 摘要(原文)
Long chain-of-thought (CoT) trajectories provide rich supervision signals for distilling reasoning from teacher to student LLMs. However, both prior work and our experiments show that trajectories from stronger teachers do not necessarily yield better students, highlighting the importance of data-student suitability in distillation. Existing methods assess suitability primarily through student likelihood, favoring trajectories that closely align with the model's current behavior but overlooking more informative ones. Addressing this, we propose Rank-Surprisal Ratio (RSR), a simple metric that captures both alignment and informativeness to assess the suitability of a reasoning trajectory. RSR is motivated by the observation that effective trajectories typically combine low absolute probability with relatively high-ranked tokens under the student model, balancing learning signal strength and behavioral alignment. Concretely, RSR is defined as the ratio of a trajectory's average token-wise rank to its average negative log-likelihood, and is straightforward to compute and interpret. Across five student models and reasoning trajectories from 11 diverse teachers, RSR strongly correlates with post-training performance (average Spearman 0.86), outperforming existing metrics. We further demonstrate its practical utility in both trajectory selection and teacher selection.