HALT: Hallucination Assessment via Latent Testing
作者: Rohan Bhatnagar, Youran Sun, Chi Andrew Zhang, Yixin Wen, Haizhao Yang
分类: cs.CL
发布日期: 2026-01-20
💡 一句话要点
HALT:通过隐空间测试评估大语言模型的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉检测 不确定性估计 中间层表示 残差探针
📋 核心要点
- 现有LLM在生成答案时存在幻觉问题,即生成不真实或不准确的内容,即使模型内部存在不确定性。
- HALT方法通过在LLM中间层插入轻量级探针,直接读取隐藏状态中的幻觉风险信号,无需完全解码。
- 实验表明,HALT在多个QA基准测试中表现出色,能有效识别幻觉风险,并可用于选择性生成和路由。
📝 摘要(中文)
大型语言模型(LLM)中的幻觉可以理解为忠实读出的失败:尽管内部表示可能编码了关于查询的不确定性,但解码压力仍然产生流畅的答案。我们提出了一种轻量级的残差探针,可以直接从问题token的中间隐藏状态读取幻觉风险,其动机是这些层保留了在最终解码阶段被衰减的认知信号。该探针是一个小型辅助网络,其计算成本比token生成低几个数量级,并且可以与推理完全并行地进行评估,从而在低风险情况下实现近乎瞬时的幻觉风险估计,且几乎没有增加延迟。我们将探针部署为agentic评论员,用于快速选择性生成和路由,允许LLM立即回答确定的查询,同时将不确定的查询委托给更强的验证管道。在四个QA基准测试和多个LLM系列中,该方法实现了强大的AUROC和AURAC,在数据集偏移下具有良好的泛化能力,并揭示了中间表示中可解释的结构,将快速内部不确定性读出定位为可靠agentic AI的原则性基础。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中普遍存在的幻觉问题,即模型生成与事实不符或无意义的内容。现有方法通常依赖于外部知识库或复杂的后处理步骤来检测和纠正幻觉,计算成本高昂且延迟较大。这些方法无法有效利用LLM内部蕴含的不确定性信息,导致在低风险情况下也需要进行额外的验证步骤。
核心思路:论文的核心思路是,LLM在生成答案的过程中,其内部的中间隐藏状态实际上包含了关于答案确定性的信息。即使最终的解码输出可能由于各种压力(如流畅性要求)而产生幻觉,但中间层仍然保留了反映模型不确定性的认知信号。因此,可以通过训练一个轻量级的探针,直接从这些中间层读取幻觉风险,从而实现快速且高效的幻觉检测。
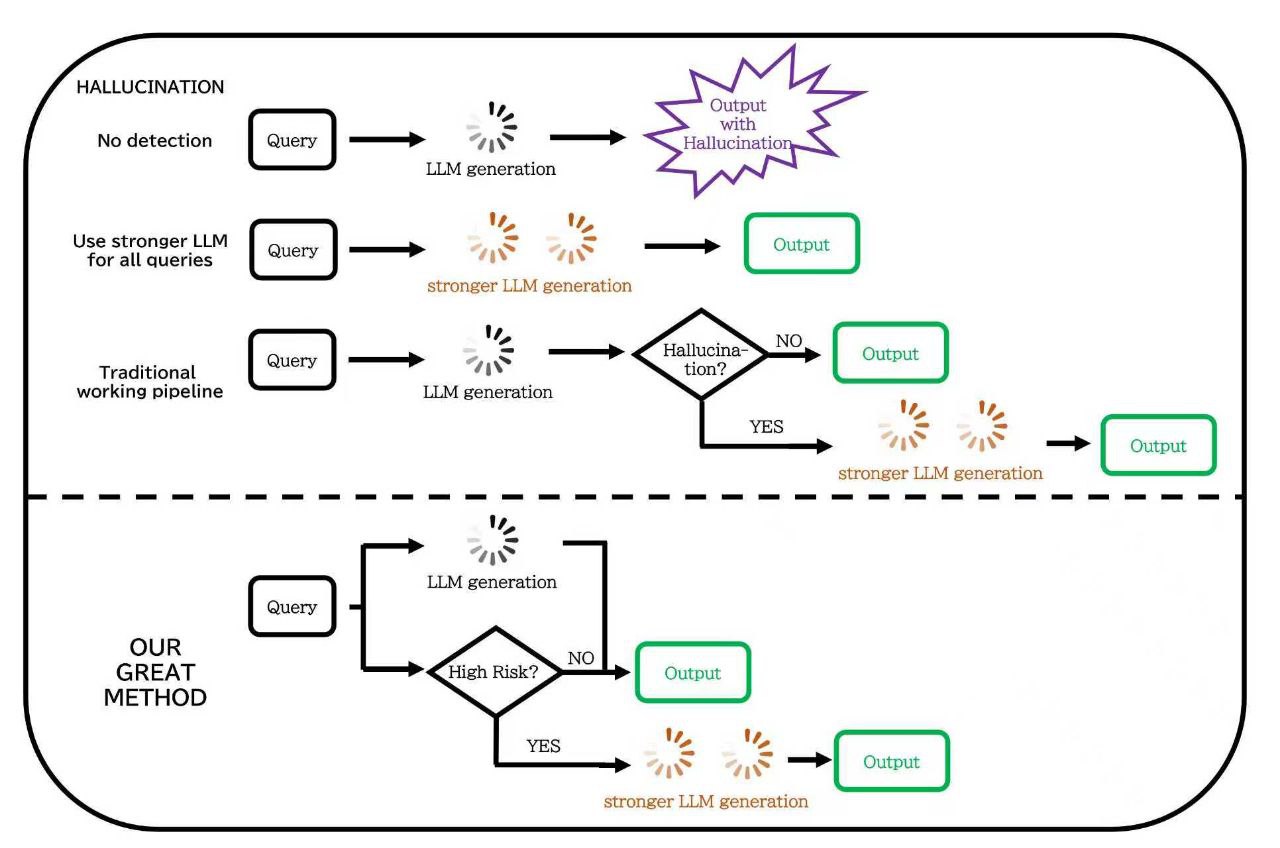
技术框架:HALT方法的技术框架主要包括以下几个步骤:1) 在LLM的中间层(通常是问题token对应的隐藏状态)插入残差探针;2) 使用包含真实性和幻觉样本的数据集训练探针,使其能够预测给定隐藏状态的幻觉风险;3) 在推理阶段,探针与LLM并行运行,快速评估每个查询的幻觉风险;4) 根据风险评估结果,对于低风险查询,LLM直接生成答案;对于高风险查询,则将其路由到更强的验证管道进行进一步处理。
关键创新:HALT方法的关键创新在于:1) 提出了一种轻量级的内部幻觉风险评估机制,避免了昂贵的外部知识库查询和后处理步骤;2) 利用LLM中间层的隐藏状态作为幻觉风险的信号源,挖掘了模型内部蕴含的不确定性信息;3) 实现了与LLM推理过程并行运行的快速风险评估,有效降低了延迟。与现有方法相比,HALT方法更加高效、可扩展,并且能够更好地利用LLM自身的知识和推理能力。
关键设计:HALT探针是一个小型的前馈神经网络,其输入是LLM中间层的隐藏状态,输出是一个标量值,表示幻觉风险。探针的训练目标是最小化预测风险与真实标签之间的差异,可以使用二元交叉熵损失函数。为了保证探针的轻量性,其网络结构通常比较简单,例如只有几层全连接层,并且参数量远小于LLM本身。此外,论文还探索了不同的探针位置(即选择哪些中间层)和探针类型(例如,线性探针、多层感知机),以优化性能。
🖼️ 关键图片
📊 实验亮点
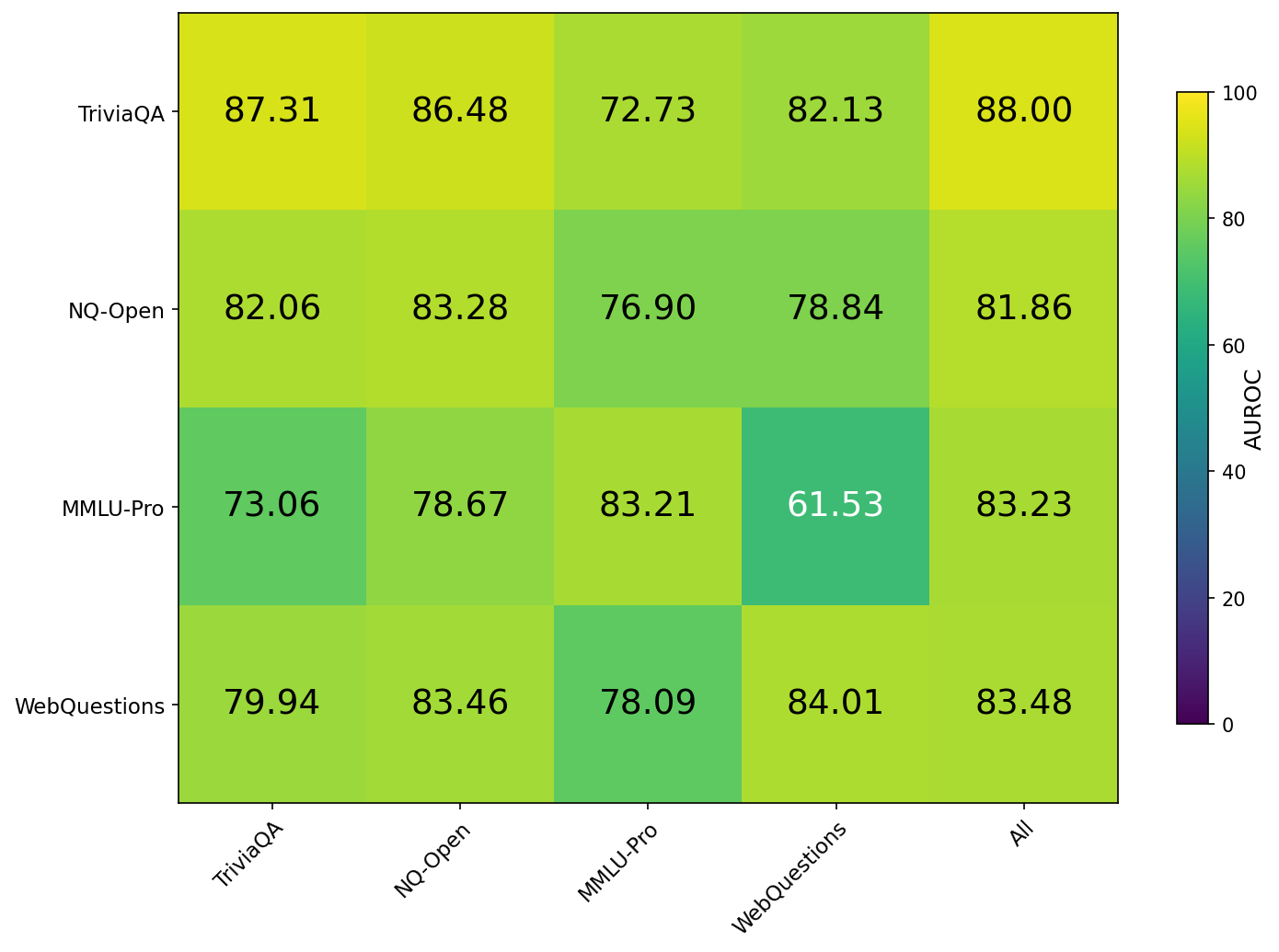
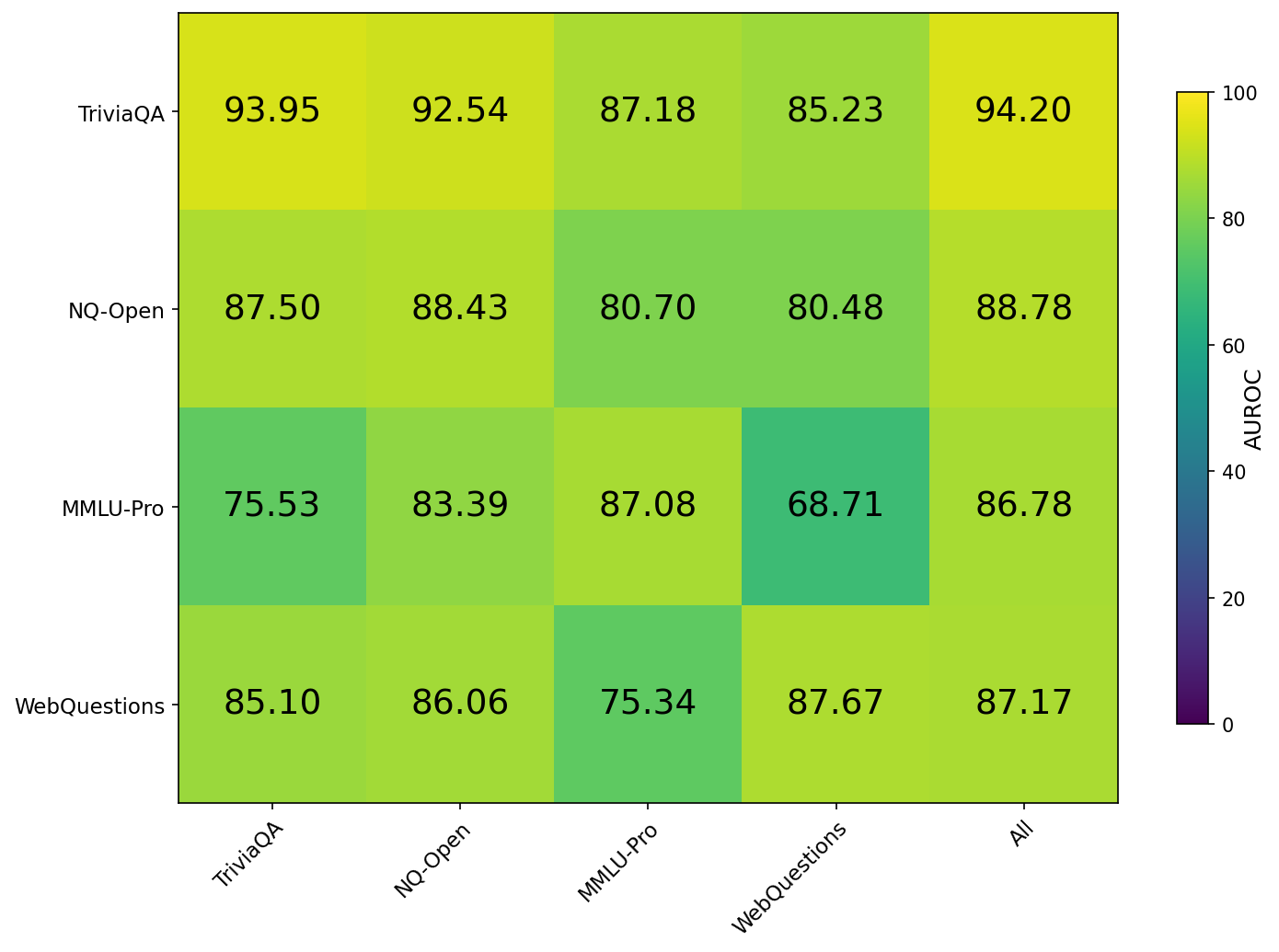
实验结果表明,HALT方法在四个QA基准测试中均取得了优异的性能,AUROC和AURAC指标均显著高于基线方法。例如,在某些数据集上,HALT的AUROC达到了0.9以上,表明其能够准确地区分真实答案和幻觉答案。此外,HALT方法在数据集偏移的情况下也表现出良好的泛化能力,证明其具有较强的鲁棒性。实验还揭示了LLM中间表示中存在可解释的结构,为理解LLM的内部工作机制提供了新的视角。
🎯 应用场景
HALT方法可广泛应用于各种需要可靠LLM输出的场景,例如智能客服、自动问答系统、内容生成平台等。通过快速识别和过滤掉潜在的幻觉内容,可以提高用户体验,降低错误信息传播的风险。此外,HALT还可以作为agentic AI的基础,实现更智能化的决策和行动,例如自动选择合适的验证管道、动态调整生成策略等。未来,HALT有望成为构建安全可靠LLM应用的关键技术。
📄 摘要(原文)
Hallucination in large language models (LLMs) can be understood as a failure of faithful readout: although internal representations may encode uncertainty about a query, decoding pressures still yield a fluent answer. We propose lightweight residual probes that read hallucination risk directly from intermediate hidden states of question tokens, motivated by the hypothesis that these layers retain epistemic signals that are attenuated in the final decoding stage. The probe is a small auxiliary network whose computation is orders of magnitude cheaper than token generation and can be evaluated fully in parallel with inference, enabling near-instantaneous hallucination risk estimation with effectively zero added latency in low-risk cases. We deploy the probe as an agentic critic for fast selective generation and routing, allowing LLMs to immediately answer confident queries while delegating uncertain ones to stronger verification pipelines. Across four QA benchmarks and multiple LLM families, the method achieves strong AUROC and AURAC, generalizes under dataset shift, and reveals interpretable structure in intermediate representations, positioning fast internal uncertainty readout as a principled foundation for reliable agentic AI.