XCR-Bench: A Multi-Task Benchmark for Evaluating Cultural Reasoning in LLMs
作者: Mohsinul Kabir, Tasnim Ahmed, Md Mezbaur Rahman, Shaoxiong Ji, Hassan Alhuzali, Sophia Ananiadou
分类: cs.CL, cs.AI, cs.CY
发布日期: 2026-01-20
备注: 30 Pages, 13 Figures
💡 一句话要点
提出XCR-Bench基准,用于评估大型语言模型中的文化推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨文化推理 大型语言模型 文化特定项 基准测试 文化偏见
📋 核心要点
- 现有方法缺乏高质量的、带有平行跨文化句子对的文化特定项(CSI)注释语料库,限制了对LLM跨文化推理能力的评估。
- 论文提出XCR-Bench基准,包含4.9k平行句和1098个独特CSI,结合Newmark框架和Hall文化三要素,系统分析文化推理。
- 实验表明,现有LLM在识别和调整与社交礼仪和文化参考相关的CSI方面存在不足,并存在区域和民族宗教偏见。
📝 摘要(中文)
大型语言模型(LLMs)的跨文化能力要求其能够识别文化特定项(CSIs),并在不同的文化背景下适当地调整它们。评估这种能力方面的进展一直受到高质量的、带有平行跨文化句子对的CSI注释语料库的稀缺性的限制。为了解决这个限制,我们引入了XCR-Bench,一个跨文化推理基准,包含4.9k个平行句子和1,098个独特的CSIs,涵盖了三个不同的推理任务以及相应的评估指标。我们的语料库将纽马克(Newmark)的CSI框架与霍尔(Hall)的文化三要素相结合,从而能够对超越表面文化产物,深入到半可见和不可见的文化元素(如社会规范、信仰和价值观)的文化推理进行系统分析。我们的研究结果表明,最先进的LLMs在识别和调整与社交礼仪和文化参考相关的CSIs方面表现出一致的弱点。此外,我们发现有证据表明,即使在单一语言环境中进行文化适应时,LLMs也会编码区域和民族宗教偏见。我们发布我们的语料库和代码,以促进未来对跨文化NLP的研究。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在跨文化推理方面的评估难题。现有方法缺乏高质量的、带有平行跨文化句子对的文化特定项(CSI)注释语料库,难以全面评估LLMs在不同文化背景下的理解和适应能力。现有方法也难以深入分析文化推理,往往停留在表面文化产物层面。
核心思路:论文的核心思路是构建一个包含丰富CSI注释的平行语料库,并结合文化理论框架,从而能够系统地评估LLMs在跨文化场景下的推理能力。通过设计不同的推理任务和评估指标,可以更全面地了解LLMs在识别和调整CSI方面的表现,并发现潜在的文化偏见。
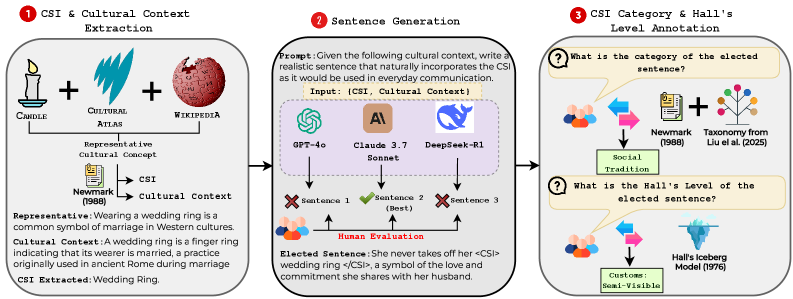
技术框架:XCR-Bench基准包含以下几个主要组成部分: 1. 平行语料库:包含4.9k个平行句子,涵盖不同的文化背景。 2. CSI注释:对语料库中的CSI进行标注,共包含1098个独特的CSIs。 3. 推理任务:设计了三个不同的推理任务,用于评估LLMs在跨文化场景下的推理能力。 4. 评估指标:为每个推理任务设计了相应的评估指标,用于衡量LLMs的表现。 5. 文化理论框架:结合Newmark的CSI框架和Hall的文化三要素,对文化推理进行系统分析。
关键创新:XCR-Bench的关键创新在于: 1. 高质量的CSI注释语料库:提供了丰富的、带有平行跨文化句子对的CSI注释,为评估LLMs的跨文化推理能力提供了基础。 2. 结合文化理论框架:将文化理论框架融入到基准设计中,能够更深入地分析文化推理,超越表面文化产物。 3. 多任务评估:设计了多个不同的推理任务,能够更全面地评估LLMs在跨文化场景下的推理能力。
关键设计:XCR-Bench的关键设计包括: 1. CSI标注规范:制定了详细的CSI标注规范,确保标注的一致性和准确性。 2. 推理任务设计:根据不同的文化推理场景,设计了三个不同的推理任务,包括CSI识别、CSI替换和文化适应。 3. 评估指标选择:为每个推理任务选择了合适的评估指标,包括准确率、召回率和F1值等。
🖼️ 关键图片
📊 实验亮点
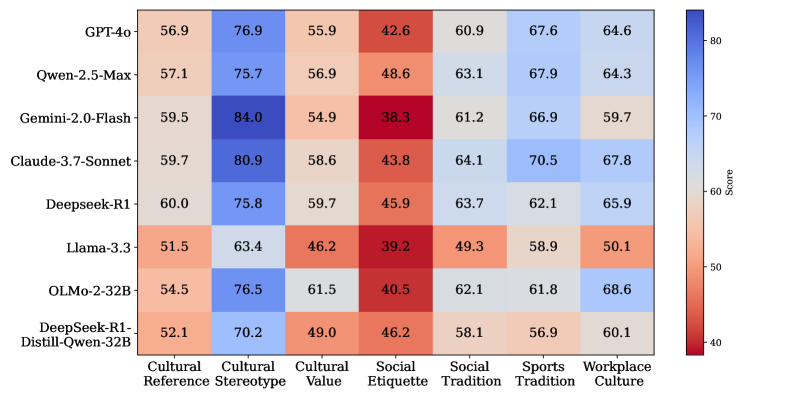
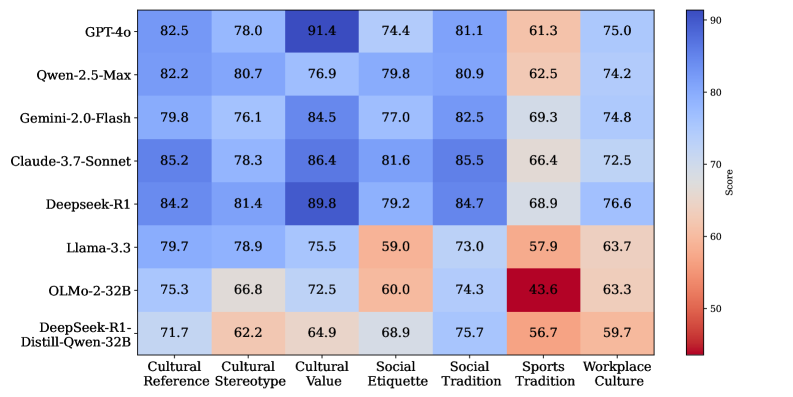
实验结果表明,现有最先进的LLMs在XCR-Bench基准上表现出明显的不足,尤其是在识别和调整与社交礼仪和文化参考相关的CSIs方面。研究还发现,LLMs在文化适应过程中存在区域和民族宗教偏见。这些发现突显了LLMs在跨文化推理方面仍有很大的提升空间,并为未来的研究提供了方向。
🎯 应用场景
该研究成果可应用于提升大型语言模型在跨文化交流、机器翻译、内容生成等领域的性能。通过XCR-Bench基准,可以更好地评估和改进LLM的文化理解能力,减少文化误解和偏见,促进更准确、更自然的跨文化沟通。未来,该基准可用于开发更具文化敏感性的AI系统,服务于全球化背景下的各种应用场景。
📄 摘要(原文)
Cross-cultural competence in large language models (LLMs) requires the ability to identify Culture-Specific Items (CSIs) and to adapt them appropriately across cultural contexts. Progress in evaluating this capability has been constrained by the scarcity of high-quality CSI-annotated corpora with parallel cross-cultural sentence pairs. To address this limitation, we introduce XCR-Bench, a Cross(X)-Cultural Reasoning Benchmark consisting of 4.9k parallel sentences and 1,098 unique CSIs, spanning three distinct reasoning tasks with corresponding evaluation metrics. Our corpus integrates Newmark's CSI framework with Hall's Triad of Culture, enabling systematic analysis of cultural reasoning beyond surface-level artifacts and into semi-visible and invisible cultural elements such as social norms, beliefs, and values. Our findings show that state-of-the-art LLMs exhibit consistent weaknesses in identifying and adapting CSIs related to social etiquette and cultural reference. Additionally, we find evidence that LLMs encode regional and ethno-religious biases even within a single linguistic setting during cultural adaptation. We release our corpus and code to facilitate future research on cross-cultural NLP.